
Debemos replantearnos la cadena de pensamiento (CdT) que impulsa la IA&YOU #68



La estadística de la semana: El rendimiento CoT a tiro cero fue de sólo 5,55% para GPT-4-Turbo, 8,51% para Claude-3-Opus y 4,44% para GPT-4. ("¿Cadena de irreflexión?" artículo)
La inducción de la cadena de pensamiento (CoT) se ha considerado un gran avance en el desarrollo de las capacidades de razonamiento de los grandes modelos lingüísticos (LLM). Sin embargo, investigaciones recientes han cuestionado estas afirmaciones y nos han llevado a revisar la técnica.
En la edición de esta semana de AI&YOU, exploramos las ideas de tres blogs que publicamos sobre el tema:
Debemos replantearnos la cadena de pensamiento (CdT) que impulsa la IA&YOU #68
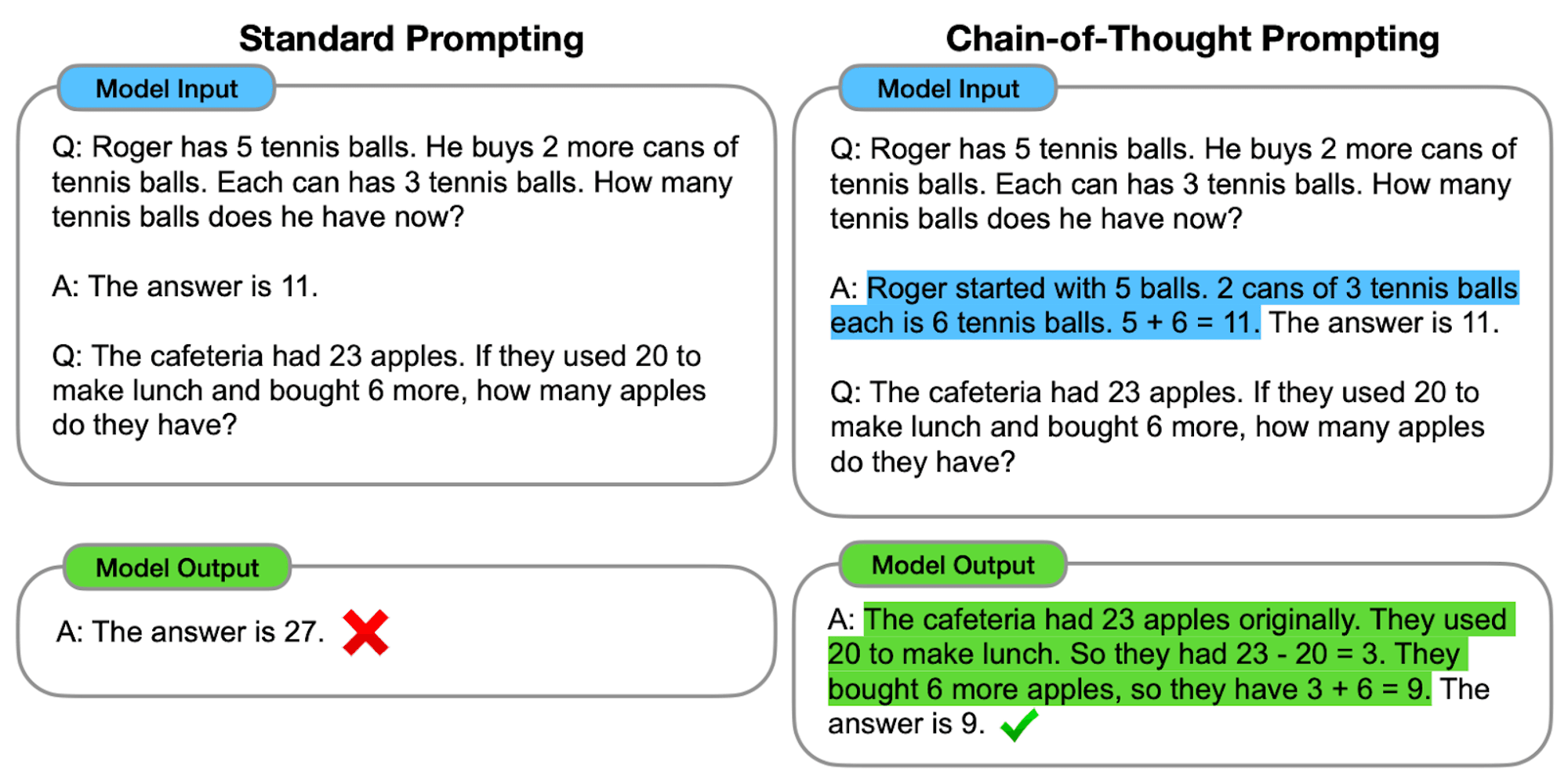
Los LLM demuestran notables capacidades en el procesamiento y la generación de lenguaje natural (PLN). Sin embargo, cuando se enfrentan a tareas de razonamiento complejas, estos modelos pueden tener dificultades para producir resultados precisos y fiables. Aquí es donde entra en juego la inducción de la cadena de pensamiento (CoT), una técnica que pretende mejorar la capacidad de resolución de problemas de los LLM.
Un avanzado ingeniería rápida está diseñado para guiar a los LLM a través de un proceso de razonamiento paso a paso. A diferencia de los métodos estándar que buscan respuestas directas, el método CoT anima al modelo a generar pasos intermedios de razonamiento antes de llegar a una respuesta final.
En esencia, las instrucciones de CoT consisten en estructurar las instrucciones de entrada de forma que provoquen una secuencia lógica de pensamientos en el modelo. Al dividir los problemas complejos en pasos más pequeños y manejables, CoT intenta permitir que los LLM naveguen por rutas de razonamiento intrincadas de forma más eficaz.
Cómo funciona CoT
En esencia, las instrucciones CoT guían a los modelos lingüísticos a través de una serie de pasos intermedios de razonamiento antes de llegar a una respuesta final. Este proceso suele implicar:
Descomposición del problema: La tarea compleja se descompone en pasos más pequeños y manejables.
Razonamiento paso a paso: Se pide al modelo que piense explícitamente en cada paso.
Progresión lógica: Cada paso se basa en el anterior, creando una cadena de pensamientos.
Conclusión: La respuesta final se obtiene a partir de los pasos de razonamiento acumulados.
Tipos de CoT Prompting
La incitación a la cadena de pensamiento puede aplicarse de varias formas, entre las que destacan dos tipos principales:
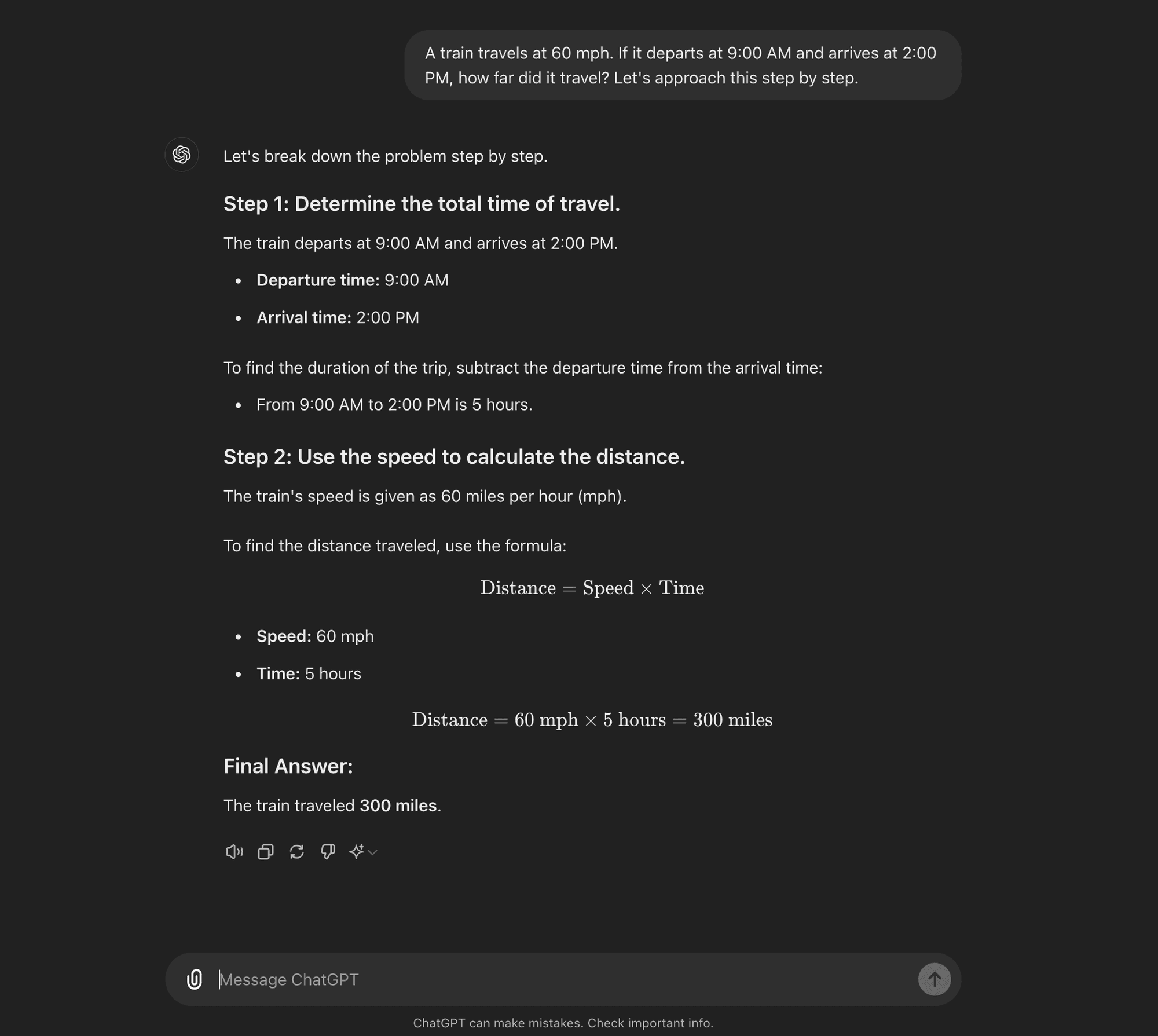
CoT de disparo cero: CoT no requiere ejemplos de tareas específicas. En su lugar, utiliza una simple indicación como "Vamos a abordar esto paso a paso" para animar al modelo a desglosar su proceso de razonamiento.****
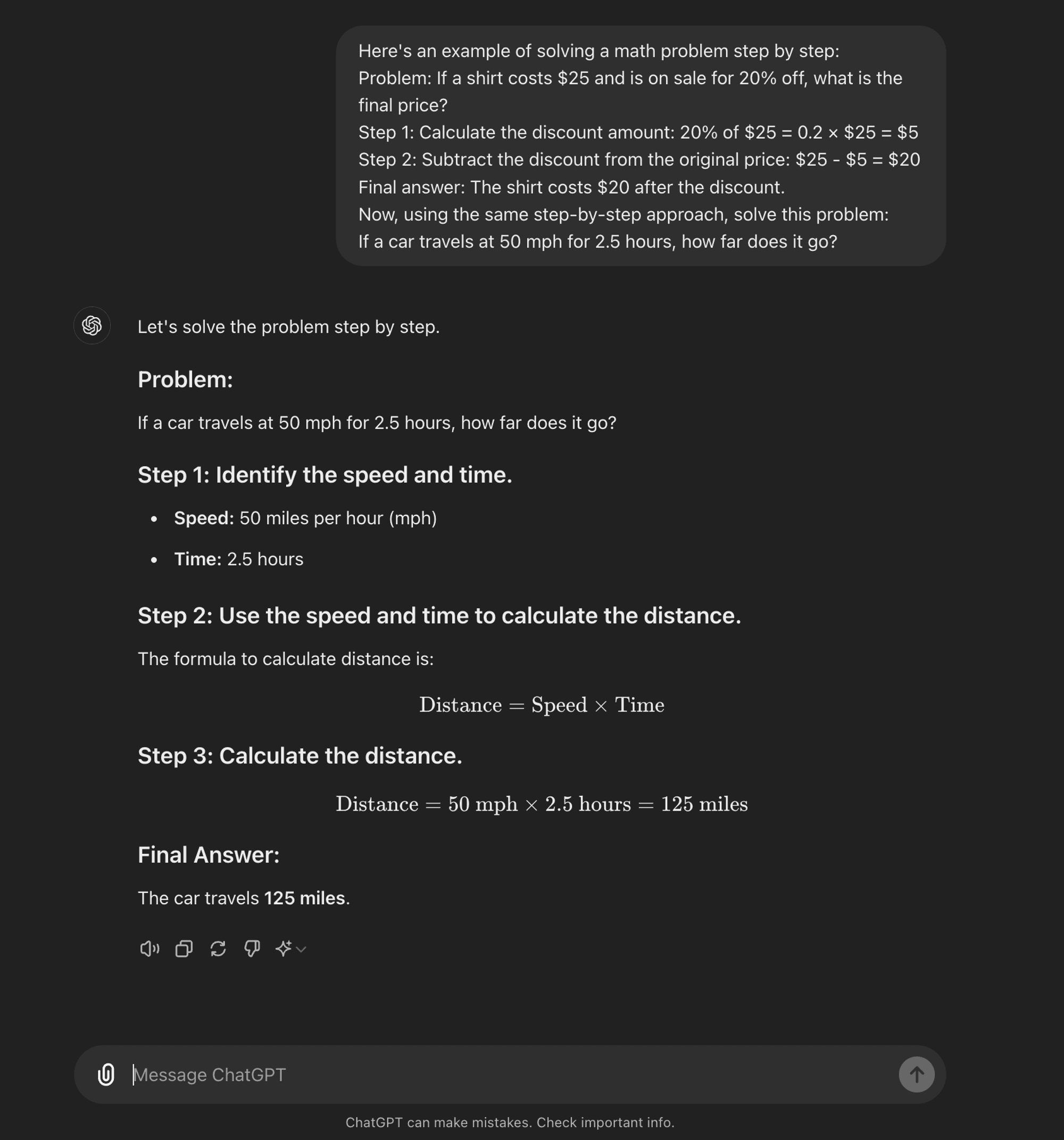
CoT de pocos disparos: La CoT de pocos intentos consiste en proporcionar al modelo un pequeño número de ejemplos que demuestren el proceso de razonamiento deseado. Estos ejemplos sirven de plantilla para que el modelo aborde problemas nuevos y desconocidos.
CoT de disparo cero
CoT de pocos disparos
Desglose del trabajo de investigación sobre IA: "¿Cadena de irreflexión?"
Ahora que ya sabes qué es el CoT prompting, podemos sumergirnos en algunas investigaciones recientes que cuestionan algunos de sus beneficios y ofrecen algunas ideas sobre cuándo es realmente útil.
El trabajo de investigación, titulado "¿Cadena de irreflexión? Un análisis de la CoT en la planificación,"ofrece un examen crítico de la eficacia y la generalizabilidad de las instrucciones CoT. Como profesionales de la IA, es crucial comprender estas conclusiones y sus implicaciones para el desarrollo de aplicaciones de IA que requieran capacidades de razonamiento sofisticadas.

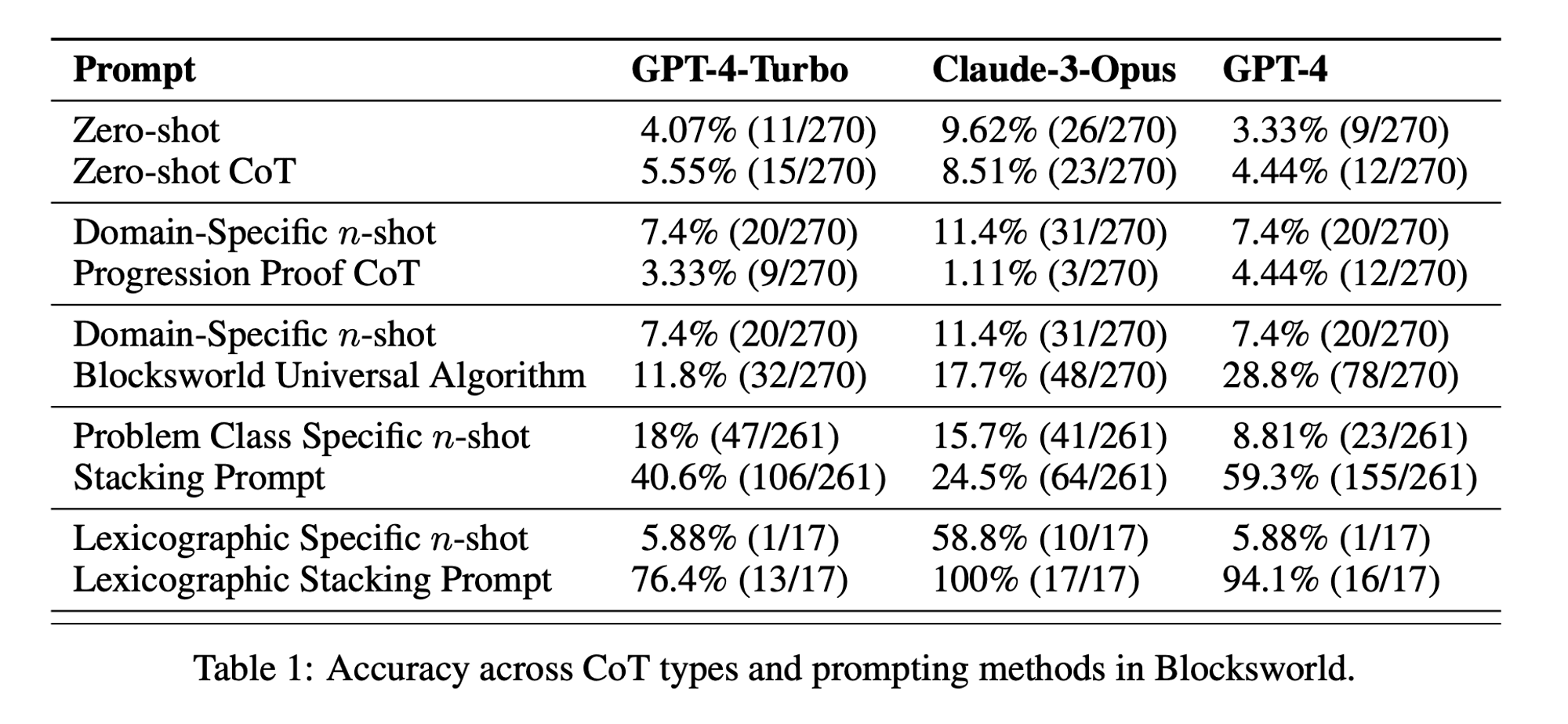
Los investigadores eligieron un dominio de planificación clásico llamado Blocksworld como principal campo de pruebas. En Blocksworld, la tarea consiste en reorganizar un conjunto de bloques desde una configuración inicial hasta una configuración objetivo mediante una serie de acciones de movimiento. Este dominio es ideal para probar las capacidades de razonamiento y planificación porque:
Permite generar problemas de complejidad variable
Tiene soluciones claras y verificables algorítmicamente.
Es poco probable que esté muy representado en los datos de formación del LLM
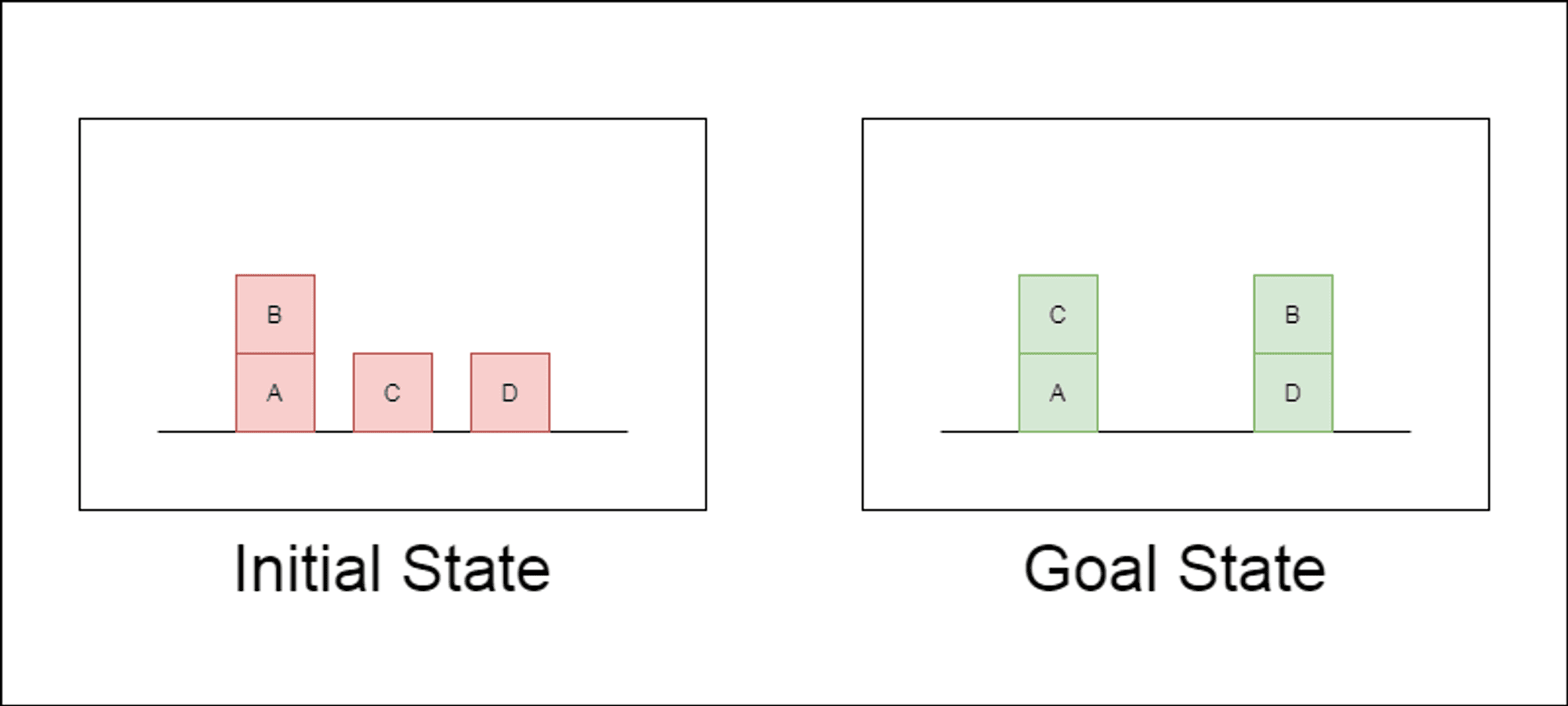
El estudio examinó tres LLM de última generación: GPT-4, Claude-3-Opus y GPT-4-Turbo. Estos modelos se probaron con instrucciones de distinta especificidad:
Cadena de pensamiento Zero-Shot (Universal): Simplemente añadiendo "pensemos paso a paso" a la indicación.
Prueba de progresión (específica para PDDL): Explicación general de la corrección del plan con ejemplos.
Algoritmo universal Blocksworld: Demostración de un algoritmo general para resolver cualquier problema de Blocksworld.
Stacking Prompt: Centrarse en una subclase específica de problemas de Blocksworld (tabla a pila).
Apilamiento lexicográfico: Limitarse aún más a una forma sintáctica concreta del estado objetivo.
Al probar estas indicaciones en problemas de complejidad creciente, los investigadores pretendían evaluar hasta qué punto los LLM podían generalizar el razonamiento demostrado en los ejemplos.
Principales conclusiones
Los resultados de este estudio ponen en tela de juicio muchas de las hipótesis predominantes sobre la incitación al TdC:
Eficacia limitada del CdT: Contrariamente a lo que se había afirmado hasta ahora, el rendimiento de CoT sólo mejoraba significativamente cuando los ejemplos eran muy similares al problema consultado. En cuanto los problemas se desviaban del formato exacto de los ejemplos, el rendimiento disminuía drásticamente.
Rápida degradación del rendimiento: A medida que aumentaba la complejidad de los problemas (medida por el número de bloques implicados), la precisión de todos los modelos disminuía drásticamente, independientemente de la indicación de CoT utilizada. Esto sugiere que los LLM tienen dificultades para extender el razonamiento demostrado en ejemplos sencillos a escenarios más complejos.
Ineficacia de los avisos generales: Sorprendentemente, las indicaciones más generales de CoT a menudo dieron peores resultados que las indicaciones estándar sin ningún ejemplo de razonamiento. Esto contradice la idea de que el CdT ayuda a los LLM a aprender estrategias generalizables de resolución de problemas.
Compromiso de especificidad: El estudio reveló que las instrucciones muy específicas podían lograr una gran precisión, pero sólo en un subconjunto muy reducido de problemas. Esto pone de manifiesto la existencia de un claro equilibrio entre el aumento del rendimiento y la aplicabilidad de la indicación.
Falta de verdadero aprendizaje algorítmico: Los resultados sugieren claramente que los LLM no aprenden a aplicar procedimientos algorítmicos generales a partir de los ejemplos del CdT. En su lugar, parecen basarse en la concordancia de patrones, que se rompe rápidamente cuando se enfrentan a problemas nuevos o más complejos.
Estos resultados tienen importantes implicaciones para los profesionales de la IA y las empresas que deseen aprovechar la inducción CoT en sus aplicaciones. Sugieren que, aunque el CoT puede mejorar el rendimiento en determinados escenarios, puede que no sea la panacea para tareas de razonamiento complejas que muchos esperaban.
Implicaciones para el desarrollo de la IA
Las conclusiones de este estudio tienen importantes implicaciones para el desarrollo de la IA, sobre todo para las empresas que trabajan en aplicaciones que requieren capacidades complejas de razonamiento o planificación:
Reevaluación de la eficacia del CdT: Los desarrolladores de IA deben ser cautos a la hora de confiar en CoT para tareas que requieran un verdadero pensamiento algorítmico o la generalización a escenarios novedosos.
Limitaciones de los LLM actuales: Pueden ser necesarios enfoques alternativos para aplicaciones que requieran una planificación sólida o la resolución de problemas en varios pasos.
El coste de la ingeniería rápida: Aunque las instrucciones muy específicas del TdC pueden dar buenos resultados en conjuntos de problemas limitados, el esfuerzo humano necesario para elaborarlas puede compensar los beneficios, sobre todo si se tiene en cuenta su limitada generalizabilidad.
Repensar las métricas de evaluación: Basarse únicamente en conjuntos de pruebas estáticas puede sobreestimar las verdaderas capacidades de razonamiento de un modelo.
La brecha entre percepción y realidad: Existe una discrepancia significativa entre las capacidades de razonamiento percibidas de los LLM (a menudo antropomorfizadas en el discurso popular) y sus capacidades reales, como demuestra este estudio.
Recomendaciones para los profesionales de la IA:
Evaluación: Implementar diversos marcos de pruebas para evaluar la verdadera generalización a través de las complejidades del problema.
Uso de CoT: Aplicar juiciosamente el estímulo de la cadena de pensamiento, reconociendo sus limitaciones en la generalización.
Soluciones híbridas: Considere la posibilidad de combinar LLM con algoritmos tradicionales para tareas de razonamiento complejas.
Transparencia: Comunicar claramente las limitaciones del sistema de IA, especialmente para tareas de razonamiento o planificación.
Enfoque I+D: Invertir en investigación para mejorar la capacidad de razonamiento real de los sistemas de IA.
Puesta a punto: Considere la posibilidad de realizar ajustes específicos para cada ámbito, pero tenga en cuenta los posibles límites de la generalización.
Para los profesionales de la IA y las empresas, estos resultados ponen de relieve la importancia de combinar los puntos fuertes del LLM con enfoques de razonamiento especializados, invertir en soluciones específicas para cada ámbito cuando sea necesario y mantener la transparencia sobre las limitaciones de los sistemas de IA. A medida que avanzamos, la comunidad de la IA debe centrarse en el desarrollo de nuevas arquitecturas y métodos de entrenamiento que puedan salvar la distancia entre la concordancia de patrones y el verdadero razonamiento algorítmico.
Las 10 mejores técnicas de incitación para los LLM
Esta semana también analizaremos diez de las técnicas de incitación más potentes y comunes, ofreciendo información sobre sus aplicaciones y mejores prácticas.

Unas instrucciones bien diseñadas pueden mejorar significativamente el rendimiento de un LLM, permitiendo resultados más precisos, relevantes y creativos. Tanto si eres un desarrollador de IA experimentado como si acabas de empezar con los LLM, estas técnicas te ayudarán a liberar todo el potencial de los modelos de IA.
No deje de consultar el blog completo para saber más sobre cada uno de ellos.
¡Gracias por tomarse el tiempo de leer AI & YOU!
Para obtener más contenido sobre IA empresarial, como infografías, estadísticas, guías prácticas, artículos y vídeos, siga a Skim AI en LinkedIn
¿Es usted fundador, director general, inversor o capitalista de riesgo y busca servicios de asesoramiento sobre IA, desarrollo fraccionado de IA o diligencia debida? Obtenga la orientación que necesita para tomar decisiones informadas sobre la estrategia de productos de IA y las oportunidades de inversión de su empresa.
Creamos soluciones de IA personalizadas para empresas respaldadas por capital riesgo y capital privado en los siguientes sectores: Tecnología Médica, Noticias/Agregación de Contenidos, Producción de Cine y Fotografía, Tecnología Educativa, Tecnología Legal, Fintech y Criptomoneda.


