
Llama 3.1 frente a los LLM propietarios: Análisis coste-beneficio para las empresas



El panorama de los grandes modelos lingüísticos (LLM) se ha convertido en un campo de batalla entre modelos de peso abierto como Llama de Meta 3.1 y las ofertas patentadas de gigantes tecnológicos como OpenAI. A medida que las empresas navegan por este complejo terreno, la decisión entre adoptar un modelo abierto o invertir en una solución de código cerrado conlleva implicaciones significativas para la innovación, el coste y la estrategia de IA a largo plazo.
Llama 3.1, en particular su formidable versión de parámetros 405B, se ha erigido en un fuerte competidor frente a los principales modelos de código cerrado, como GPT-4o y Claude 3.5. Este cambio ha obligado a las empresas a reevaluar su enfoque de la implantación de la IA, teniendo en cuenta factores que van más allá de las meras métricas de rendimiento.
En este análisis, profundizaremos en las compensaciones coste-beneficio entre Llama 3.1 y los LLM propietarios, proporcionando a los responsables de la toma de decisiones empresariales un marco completo para tomar decisiones informadas sobre sus inversiones en IA.
Comparación de costes
Precios de las licencias: Modelos propietarios frente a modelos abiertos
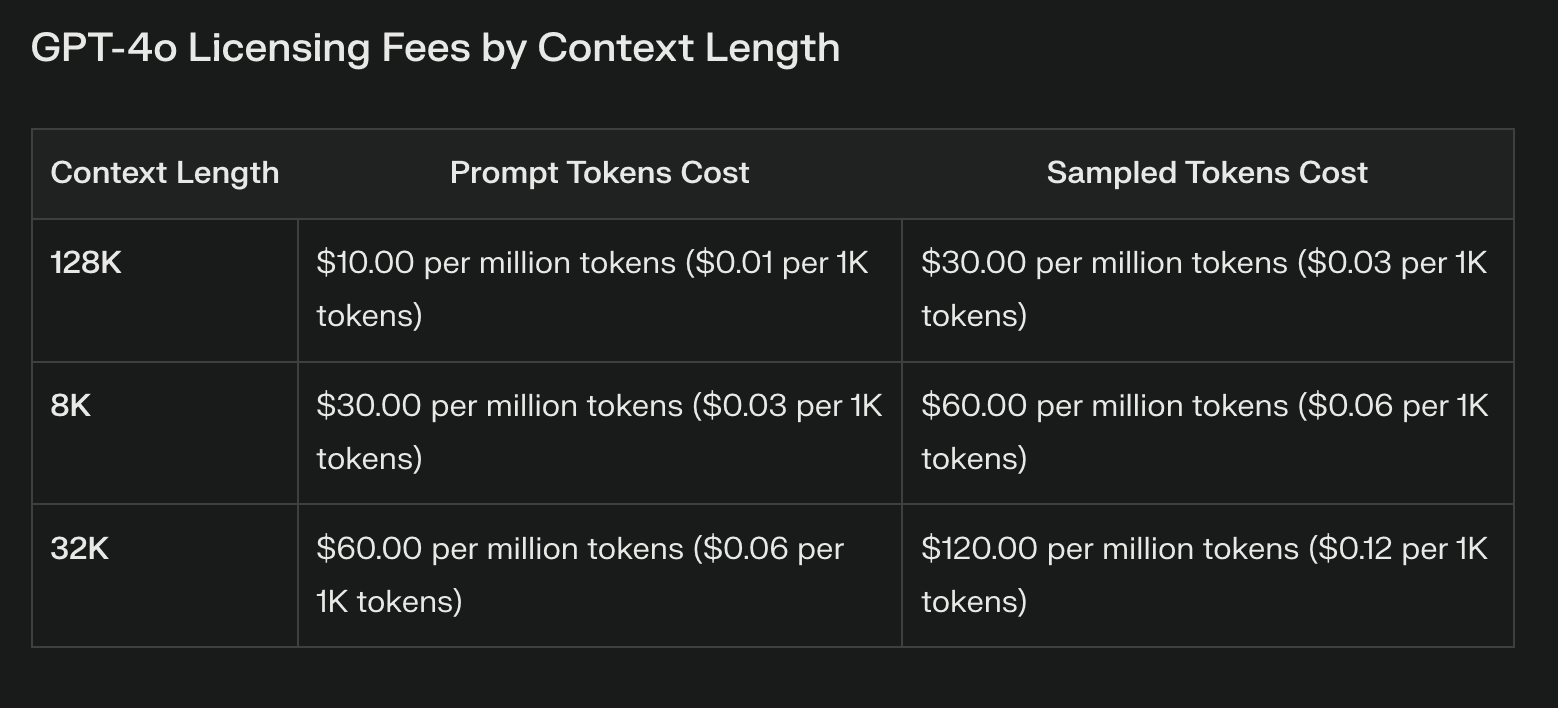
La diferencia de coste más evidente entre Llama 3.1 y los modelos propietarios reside en los derechos de licencia. Los LLM propietarios suelen conllevar importantes costes recurrentes, que pueden aumentar considerablemente con el uso. Estas tarifas, aunque proporcionan acceso a tecnología punta, pueden sobrecargar los presupuestos y limitar la experimentación.
Llama 3.1, con sus pesos abiertos, elimina por completo el pago de licencias. Este ahorro de costes puede ser sustancial, especialmente para las empresas que planean grandes despliegues de IA. Sin embargo, es crucial tener en cuenta que la ausencia de derechos de licencia no equivale a costes cero.
Costes de infraestructura y despliegue
Aunque Llama 3.1 puede ahorrar en licencias, exige importantes recursos computacionales, sobre todo para el modelo de parámetros 405B. Las empresas deben invertir en una sólida infraestructura de hardware, que a menudo incluye clusters de GPU de gama alta o recursos de computación en la nube. Por ejemplo, ejecutar el modelo 405B completo de forma eficiente puede requerir varias GPU NVIDIA H100, lo que representa un gasto de capital considerable.
Los modelos propios, a los que se suele acceder a través de API, descargan estos costes de infraestructura en el proveedor. Esto puede resultar ventajoso para las empresas que carecen de los recursos o la experiencia necesarios para gestionar una infraestructura de IA compleja. Sin embargo, un gran volumen de llamadas a las API también puede acumular costes rápidamente, lo que puede superar el ahorro inicial en infraestructura.

Mantenimiento y actualizaciones
El mantenimiento de un modelo de peso abierto como Llama 3.1 requiere una inversión continua en conocimientos y recursos. Las empresas deben asignar presupuesto para:
Actualizaciones y ajustes periódicos de los modelos
Parches de seguridad y gestión de vulnerabilidades
Optimización del rendimiento y mejora de la eficacia
Los modelos patentados suelen incluir estas actualizaciones como parte de su servicio, lo que reduce potencialmente la carga de los equipos internos. Sin embargo, esta comodidad se consigue a costa de un menor control sobre el proceso de actualización y de posibles interrupciones en la puesta a punto de los modelos.
Comparación de resultados
Resultados comparativos de varias tareas
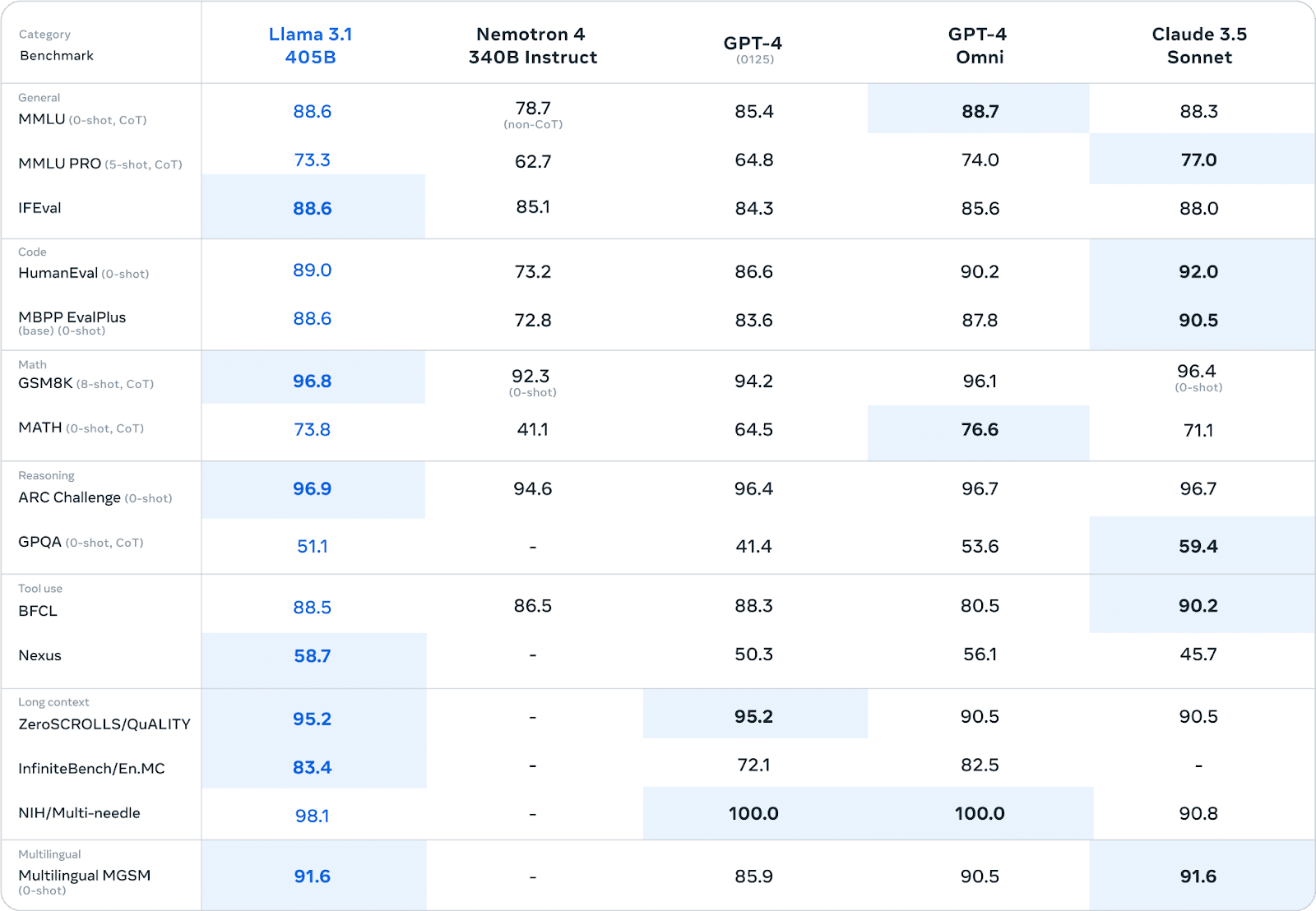
Llama 3.1 ha demostrado un rendimiento impresionante en diversas pruebas comparativas, a menudo rivalizando o superando a los modelos propietarios. En extensas evaluaciones humanas y pruebas automatizadas, la versión con parámetros 405B ha mostrado un rendimiento comparable al de los principales modelos de código cerrado en áreas como:
Conocimientos generales y razonamiento
Generación y depuración de código
Resolución de problemas matemáticos
Competencia multilingüe
Por ejemplo, en la prueba comparativa MMLU (Massive Multitask Language Understanding), Llama 3.1 405B obtuvo una puntuación de 86,4%, lo que la sitúa en competencia directa con modelos como GPT-4.
Rendimiento real en entornos empresariales
Aunque los puntos de referencia proporcionan información valiosa, el rendimiento real en entornos empresariales es la verdadera prueba de las capacidades de un LLM.
Aquí, el panorama se vuelve más matizado:
Ventaja de la personalización: Las empresas que utilizan Llama 3.1 informan de importantes ventajas derivadas del ajuste fino del modelo sobre datos específicos del dominio. Esta personalización a menudo da como resultado un rendimiento superior al de los modelos propietarios estándar para tareas especializadas.
Generación de datos sintéticos: La capacidad de Llama 3.1 para generar datos sintéticos ha demostrado ser valiosa para las empresas que buscan aumentar sus conjuntos de datos de formación o simular escenarios complejos.
Compromisos de eficiencia: Algunas empresas han descubierto que, si bien los modelos propietarios pueden tener una ligera ventaja en el rendimiento inicial, la capacidad de crear modelos especializados y eficientes mediante técnicas como la destilación de modelos con Llama 3.1 conduce a mejores resultados generales en entornos de producción.
Consideraciones sobre la latencia: Los modelos propietarios a los que se accede a través de la API pueden ofrecer una latencia menor para consultas únicas, lo que puede ser crucial para aplicaciones en tiempo real. Sin embargo, las empresas que ejecutan Llama 3.1 en hardware dedicado informan de un rendimiento más constante bajo cargas elevadas.
Cabe señalar que las comparaciones de rendimiento dependen en gran medida de casos de uso específicos y detalles de implementación. Las empresas deben realizar pruebas exhaustivas en sus propios entornos para evaluar el rendimiento con precisión.
Consideraciones a largo plazo
El desarrollo futuro de los LLM es un factor crítico en la toma de decisiones. Llama 3.1 se beneficia de una rápida iteración impulsada por una comunidad mundial de investigadores, lo que puede conducir a mejoras revolucionarias. Los modelos patentados, respaldados por empresas bien financiadas, ofrecen actualizaciones constantes y la posibilidad de integrar tecnología patentada.
En Mercado LLM es proclive a la disrupción. A medida que los modelos abiertos como Llama 3.1 se acerquen o superen el rendimiento de las alternativas patentadas, es posible que veamos una tendencia hacia la mercantilización de los modelos básicos y una mayor especialización. Las nuevas normativas sobre IA también podrían afectar a la viabilidad de los distintos enfoques de LLM.
La alineación con estrategias empresariales de IA más amplias es crucial. La adopción de Llama 3.1 puede fomentar el desarrollo de la experiencia interna en IA, mientras que el compromiso con modelos propios puede conducir a asociaciones estratégicas con gigantes tecnológicos.
Marco de decisión
Los escenarios que favorecen Llama 3.1 incluyen:
Aplicaciones industriales muy especializadas que requieren una gran personalización
Empresas con sólidos equipos internos de IA capaces de gestionar modelos
Las empresas dan prioridad a la soberanía de los datos y al control total de los procesos de IA
Los escenarios que favorecen los modelos propietarios incluyen:
Necesidad de despliegue inmediato con una infraestructura mínima
Necesidad de un amplio apoyo de los proveedores y de acuerdos de nivel de servicio garantizados
Integración con los ecosistemas de IA patentados existentes
Lo esencial
La elección entre Llama 3.1 y los LLM propietarios representa un punto de decisión crítico para las empresas que navegan por el panorama de la IA. Aunque Llama 3.1 ofrece una flexibilidad sin precedentes, un potencial de personalización y un ahorro de costes en licencias, exige una inversión significativa en infraestructura y experiencia. Los modelos patentados ofrecen facilidad de uso, soporte sólido y actualizaciones constantes, pero a costa de un menor control y un posible bloqueo del proveedor. En última instancia, la decisión depende de las necesidades específicas, los recursos y la estrategia de IA a largo plazo de cada empresa. Sopesando cuidadosamente los factores descritos en este análisis, los responsables de la toma de decisiones pueden trazar el camino que mejor se adapte a los objetivos y capacidades de su organización.


