
Cómo debería utilizar su empresa las bases de datos vectoriales para sus aplicaciones LLM en 2024



En los últimos años, los grandes modelos lingüísticos (LLM) han revolucionado el panorama de las aplicaciones empresariales de IA. Estos potentes modelos de aprendizaje automático han demostrado notables capacidades de procesamiento, generación y comprensión del lenguaje natural, abriendo un mundo de posibilidades para las empresas de todos los sectores. Sin embargo, a medida que los LLM se vuelven más sofisticados y exigentes, las empresas se enfrentan al reto de almacenar y recuperar de forma eficiente las enormes cantidades de datos necesarias para entrenar y hacer funcionar estos modelos. Las bases de datos vectoriales son la clave para liberar todo el potencial de los LLM. LLMs en empresa Aplicaciones de la IA.
Bases de datos vectoriales
Las bases de datos vectoriales son bases de datos especializadas diseñadas para almacenar y gestionar datos vectoriales de alta dimensión. A diferencia de las bases de datos tradicionales, que almacenan los datos en filas y columnas, las bases de datos vectoriales representan los datos como vectores numéricos en un espacio vectorial. Cada punto de datos, como un documento de texto o una imagen, se convierte en una incrustación vectorial: una representación numérica densa y de longitud fija que captura el significado semántico de los datos.
Cómo funcionan las bases de datos vectoriales
En el núcleo de las bases de datos vectoriales se encuentra el concepto de incrustación vectorial y espacio vectorial. Las incrustaciones vectoriales se generan mediante modelos de aprendizaje automático, como word2vec o BERT, que aprenden a asignar puntos de datos a un espacio vectorial de alta dimensión. En este espacio vectorial, los puntos de datos similares están representados por vectores cercanos entre sí, mientras que los puntos de datos disímiles están más alejados.
Las bases de datos vectoriales permiten realizar operaciones eficaces de búsqueda de similitudes y del vecino más próximo. Cuando se proporciona un vector de consulta, la base de datos puede encontrar rápidamente los vectores más similares en el espacio vectorial utilizando métricas de distancia como la similitud coseno o la distancia euclídea. Esto permite recuperar datos relevantes de forma rápida y precisa basándose en la similitud semántica y no en la coincidencia exacta de palabras clave.
Ventajas del uso de bases de datos vectoriales para aplicaciones LLM
Las bases de datos vectoriales ofrecen varias ventajas clave sobre las bases de datos tradicionales a la hora de soportar aplicaciones LLM:
Búsqueda semántica: Las bases de datos vectoriales permiten la búsqueda semántica, lo que permite a los LLM recuperar información basada en el significado y el contexto de la consulta en lugar de basarse en coincidencias exactas de palabras clave. Así se obtienen resultados más pertinentes y precisos.
Escalabilidad: Las bases de datos vectoriales están diseñadas para manejar datos vectoriales a gran escala de forma eficiente. Pueden almacenar y procesar millones o incluso miles de millones de vectores de alta dimensión, lo que las hace ideales para los conjuntos de datos masivos necesarios para entrenar y operar LLM.
Tiempos de consulta más rápidos: Los algoritmos especializados de indexación y búsqueda utilizados por las bases de datos vectoriales permiten realizar consultas a la velocidad del rayo, incluso en grandes conjuntos de datos. Esto es crucial para las aplicaciones LLM en tiempo real que requieren un acceso rápido a la información relevante.
Mayor precisión: Al aprovechar la información semántica capturada en las incrustaciones vectoriales, las bases de datos vectoriales pueden ayudar a los LLM a proporcionar respuestas más precisas y contextualmente relevantes a las consultas de los usuarios.
A medida que las empresas tratan de aprovechar la potencia de los LLM en sus aplicaciones de IA, las bases de datos vectoriales surgen como una herramienta esencial para el almacenamiento y la recuperación eficiente de datos.

LLM y bases de datos vectoriales: Una combinación perfecta para la IA empresarial
El éxito de los LLM depende en gran medida de la calidad y accesibilidad de los datos con los que se entrenan. Aquí es donde entran en juego las bases de datos vectoriales, que ofrecen una potente solución para almacenar y recuperar las enormes cantidades de datos que necesitan los LLM.
El papel de los datos en la formación y el ajuste de los LLM
Los LLM se entrenan con conjuntos de datos masivos que contienen miles de millones de palabras, lo que les permite aprender las complejidades del lenguaje y desarrollar una profunda comprensión del contexto y el significado. Una vez preentrenados, los LLM pueden perfeccionarse con datos de dominios específicos para adaptarse a casos de uso y sectores concretos. La calidad y la pertinencia de estos datos influyen directamente en el rendimiento y la precisión de los LLM en las aplicaciones empresariales de IA.
Retos que plantea el uso de bases de datos tradicionales para almacenar y recuperar datos de LLM
Las bases de datos tradicionales, como las relacionales, no son adecuadas para manejar los datos no estructurados y de alta dimensión que requieren los LLM. Estas bases de datos se enfrentan a los siguientes retos:
Escalabilidad: Las bases de datos tradicionales suelen tener problemas de rendimiento cuando tratan con conjuntos de datos a gran escala, lo que dificulta el almacenamiento y la recuperación de las ingentes cantidades de datos necesarias para la formación y el funcionamiento del LLM.
Búsqueda ineficaz: La búsqueda basada en palabras clave en las bases de datos tradicionales no capta el significado semántico y el contexto de los datos, lo que conduce a resultados irrelevantes o incompletos cuando los consultan los LLM.
Falta de flexibilidad: El rígido esquema de las bases de datos tradicionales dificulta la adaptación de los diversos tipos y estructuras de datos asociados a los LLM.
Cómo superan estos retos las bases de datos vectoriales
Las bases de datos vectoriales están diseñadas específicamente para hacer frente a las limitaciones de las bases de datos tradicionales a la hora de soportar los LLM:
Búsqueda eficiente de similitudes para la recuperación de datos en función del contexto: Al representar los datos como vectores en un espacio de altas dimensiones, las bases de datos vectoriales permiten una búsqueda de similitudes rápida y precisa. Las LLM pueden recuperar información relevante basándose en el significado semántico de la consulta, lo que garantiza respuestas más adecuadas al contexto.
Escalabilidad para manejar grandes conjuntos de datos: Las bases de datos vectoriales están diseñadas para manejar grandes cantidades de datos vectoriales de forma eficiente. Pueden escalarse horizontalmente a través de múltiples máquinas, lo que permite el almacenamiento y procesamiento de miles de millones de incrustaciones vectoriales requeridas por los LLM.
Ejemplos reales de LLM que aprovechan las bases de datos vectoriales
Varias aplicaciones empresariales notables de IA han integrado con éxito LLM con bases de datos vectoriales para mejorar el rendimiento y la eficiencia:
GPT-4 de OpenAI y las bases de datos de Anthropic: OpenAI y Anthropic utilizan bases de datos vectoriales para almacenar y recuperar las vastas bases de conocimiento que alimentan sus LLM de última generación, lo que permite una generación del lenguaje más precisa y pertinente en función del contexto.
Búsqueda empresarial y gestión del conocimiento: Empresas como Microsoft y Google utilizan bases de datos vectoriales para mejorar sus sistemas empresariales de búsqueda y gestión del conocimiento, lo que permite a los empleados encontrar información relevante de forma rápida y sencilla mediante consultas en lenguaje natural.
Atención al cliente y chatbots: Las empresas emplean bases de datos vectoriales para almacenar y recuperar datos de clientes, información sobre productos e historiales de conversaciones, lo que permite a los chatbots impulsados por LLM ofrecer una atención al cliente más personalizada y eficiente.
Identificación de casos de uso de bases de datos vectoriales en sus aplicaciones LLM
Antes de implantar una base de datos vectorial, es fundamental identificar los casos de uso específicos en los que puede aportar más valor a las aplicaciones de IA de su empresa. La búsqueda semántica y la recuperación de información es un área en la que destacan las bases de datos vectoriales, ya que permiten a los usuarios encontrar información relevante mediante consultas en lenguaje natural. Al representar documentos, imágenes y otros datos como vectores, las LLM pueden recuperar los resultados semánticamente más similares, mejorando la precisión y relevancia de los resultados de búsqueda.
Otro caso de uso clave es la generación aumentada por recuperación, en la que los LLM pueden generar respuestas más precisas y contextualmente relevantes mediante la integración con bases de datos vectoriales. Durante el proceso de generación, el LLM puede recuperar información relevante de la base de datos vectorial basándose en la consulta de entrada, lo que mejora la coherencia y la corrección factual del texto generado.
Los sistemas de personalización y recomendación también pueden beneficiarse enormemente de las bases de datos vectoriales. Al representar las preferencias de los usuarios, los comportamientos y las características de los artículos como vectores, los LLM pueden generar recomendaciones muy específicas, sugerencias de contenidos y resultados específicos para cada usuario. Esto se consigue calculando la similitud entre los vectores del usuario y del artículo.
Por último, las bases de datos vectoriales pueden utilizarse para la gestión del conocimiento y la organización de contenidos. Las empresas pueden aprovechar las bases de datos vectoriales para organizar y gestionar grandes volúmenes de datos no estructurados, como documentos, informes y contenidos multimedia. Al agrupar vectores similares, las empresas pueden categorizar y etiquetar automáticamente los contenidos, facilitando su descubrimiento y navegación.
Cómo elegir la base de datos vectorial que mejor se adapte a sus necesidades
Seleccionar la base de datos vectorial adecuada es crucial para el éxito de las aplicaciones de IA de su empresa. Al evaluar las distintas soluciones de bases de datos vectoriales, tenga en cuenta las ventajas y desventajas de las opciones de código abierto y las propietarias. Las bases de datos vectoriales de código abierto ofrecen flexibilidad, personalización y rentabilidad. Cuentan con comunidades activas, actualizaciones periódicas y una amplia documentación. Por otro lado, las soluciones propietarias, a menudo proporcionadas por plataformas en la nube o proveedores especializados, ofrecen servicios gestionados, asistencia de nivel empresarial e integración perfecta con otras herramientas de su ecosistema. Sin embargo, pueden conllevar costes más elevados y riesgos de dependencia del proveedor.
La escalabilidad y el rendimiento son factores críticos a la hora de elegir una base de datos vectorial. Evalúe la capacidad de la base de datos para manejar la escala de sus datos, tanto en términos de capacidad de almacenamiento como de rendimiento de la consulta. Busque soluciones que puedan procesar eficazmente millones o miles de millones de vectores de alta dimensión. Tenga en cuenta los algoritmos de indexación y búsqueda de la base de datos, como la búsqueda aproximada del vecino más próximo (RNA), que puede acelerar considerablemente la búsqueda de similitudes en grandes conjuntos de datos. Además, evalúe las opciones de escalabilidad horizontal y vertical de la base de datos para asegurarse de que puede crecer con sus datos y su base de usuarios.
La facilidad de integración es otra consideración importante. Investiga hasta qué punto la base de datos vectorial se integra con tu pila tecnológica actual, incluidos los marcos LLMy aplicaciones posteriores. Busque bases de datos que ofrezcan API, SDK y conectores para los lenguajes de programación y marcos de trabajo más populares, lo que facilitará la integración y el mantenimiento por parte de su equipo de desarrollo.
Por último, dé prioridad a las bases de datos vectoriales con comunidades activas, documentación completa y canales de soporte receptivos. Una comunidad sólida garantiza el acceso a la ayuda oportuna, la corrección de errores y la actualización de funciones. Evalúe el ecosistema de herramientas, complementos e integraciones de la base de datos, ya que un ecosistema rico puede acelerar el desarrollo, proporcionar funciones adicionales y facilitar la integración con otros sistemas empresariales.

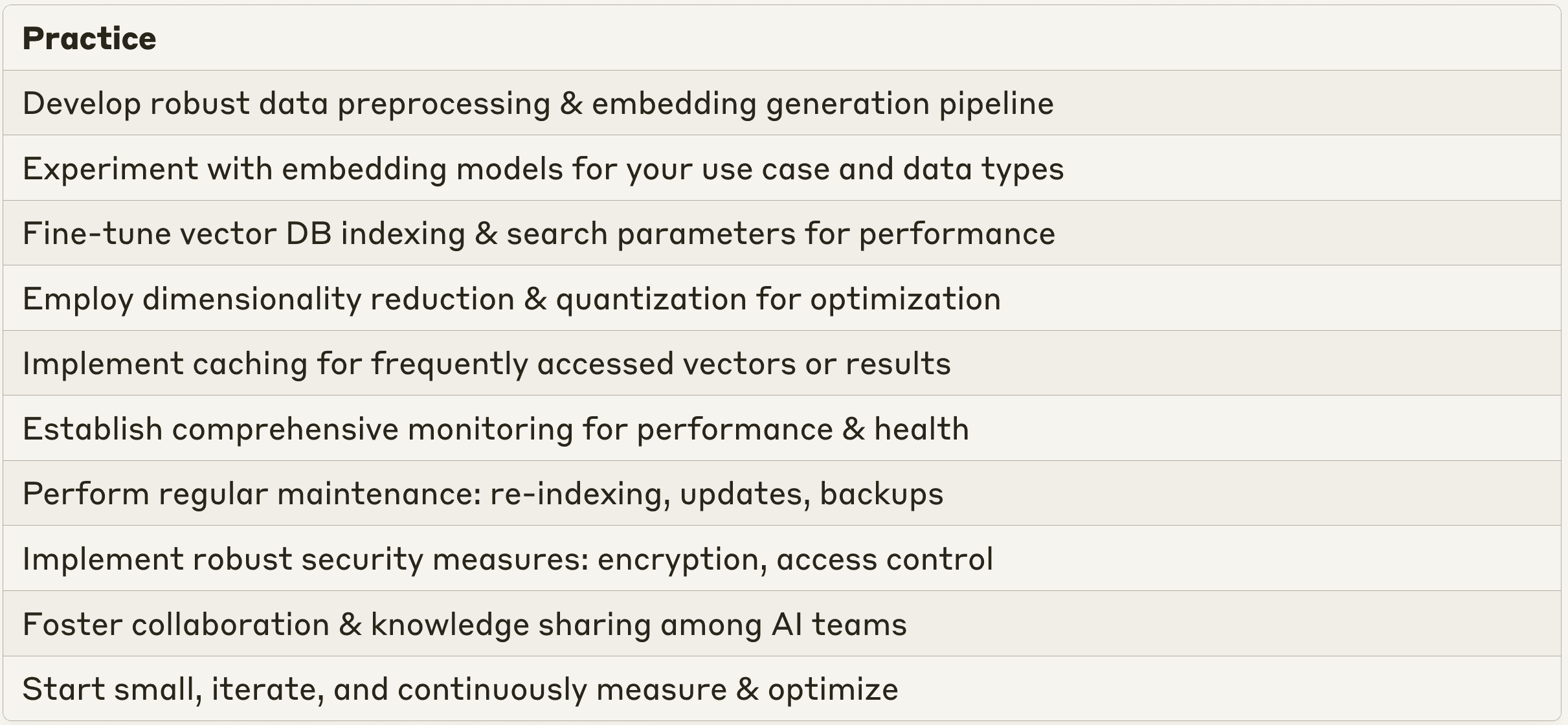
Mejores prácticas para integrar bases de datos vectoriales con sus aplicaciones LLM
Para garantizar una implementación eficaz y sin problemas de las bases de datos vectoriales en las aplicaciones de IA de su empresa, deben seguirse varias prácticas recomendadas. En primer lugar, desarrolle una sólida canalización de preprocesamiento de datos para limpiar, normalizar y transformar sus datos brutos en un formato adecuado para la generación de incrustación vectorial. Experimente con diferentes modelos y técnicas de incrustación para encontrar el enfoque más adecuado para su caso de uso y tipos de datos específicos. Ajuste los modelos de incrustación preentrenados en sus datos específicos de dominio para capturar la semántica y las relaciones únicas dentro del contexto de su empresa. Implementar comprobaciones de calidad de datos y pasos de validación para garantizar la coherencia y fiabilidad de sus incrustaciones vectoriales.
La optimización de las consultas y el ajuste del rendimiento son esenciales para un uso eficiente de las bases de datos vectoriales. Ajuste los parámetros de indexación y búsqueda de su base de datos vectorial, como el número de vecinos más próximos, el radio de búsqueda o los algoritmos de agrupación, para lograr un equilibrio entre velocidad de consulta y precisión. Utilice técnicas como la reducción de la dimensionalidad para reducir el tamaño de los vectores sin perder su información semántica, lo que mejorará la eficiencia del almacenamiento y el rendimiento de las consultas. Utilizar métodos de cuantificación, como la cuantificación de productos o la compresión de vectores, para optimizar aún más el almacenamiento y la recuperación de vectores. Implemente mecanismos de caché para almacenar en memoria los vectores o resultados de búsqueda a los que se accede con frecuencia, reduciendo así la latencia de las consultas repetidas.
La supervisión y el mantenimiento son cruciales para garantizar el buen funcionamiento de su base de datos de vectores. Establezca un sistema de supervisión exhaustivo para realizar un seguimiento del rendimiento, la disponibilidad y la salud de su base de datos vectorial. Supervise métricas clave como la latencia de las consultas, el rendimiento y las tasas de error. Establezca alertas y notificaciones para identificar y abordar de forma proactiva cualquier cuello de botella en el rendimiento, limitación de recursos o anomalía. Realice tareas de mantenimiento periódicas, como reindexación, actualizaciones de datos y copias de seguridad, para garantizar la integridad y frescura de sus datos vectoriales. Evalúe y optimice continuamente el rendimiento de su base de datos vectorial basándose en patrones de uso reales y en los comentarios de los usuarios. Modifique sus estrategias de indexación, algoritmos de búsqueda y configuraciones de hardware según sea necesario.
La seguridad y el control de acceso son primordiales cuando se trata de datos empresariales sensibles. Implemente medidas de seguridad sólidas para proteger la confidencialidad, integridad y disponibilidad de sus datos vectoriales. Aplique mecanismos de cifrado, autenticación y control de acceso para salvaguardar la información confidencial. Defina políticas de acceso y permisos granulares para garantizar que sólo los usuarios y aplicaciones autorizados puedan acceder a la base de datos vectorial y manipularla. Audite y revise regularmente los registros de acceso para detectar y prevenir intentos de acceso no autorizados o actividades sospechosas.
Por último, fomentar una cultura de colaboración e intercambio de conocimientos entre sus equipos de IA es esencial para el éxito de la implantación de bases de datos vectoriales. Fomente el intercambio de mejores prácticas, lecciones aprendidas e ideas innovadoras relacionadas con las bases de datos vectoriales y las aplicaciones LLM. Establezca foros internos, talleres o hackathons para promover la experimentación, el desarrollo de habilidades y la colaboración interfuncional en torno a las tecnologías de bases de datos vectoriales. Participar en comunidades externas, conferencias y eventos del sector para mantenerse informado sobre los últimos avances, casos de uso y mejores prácticas en bases de datos vectoriales e IA empresarial.
Si sigue estas prácticas recomendadas y tiene en cuenta los requisitos específicos de su empresa, podrá implantar con éxito bases de datos vectoriales y liberar todo el potencial de sus aplicaciones LLM. Recuerde empezar poco a poco, iterar con frecuencia y medir y optimizar continuamente el rendimiento de su base de datos vectorial para garantizar que ofrece el máximo valor a su empresa.
El futuro de las bases de datos vectoriales en la IA empresarial
A medida que la tecnología de bases de datos vectoriales siga avanzando, podemos esperar ver una plétora de aplicaciones nuevas e innovadoras en la IA empresarial:
Creación de contenidos personalizados: Los LLM basados en bases de datos vectoriales pueden generar contenidos altamente personalizados, como artículos, informes y materiales de marketing, adaptados a las preferencias y el contexto de cada usuario.
Procesamiento inteligente de documentos: Las bases de datos vectoriales pueden permitir la clasificación, indexación y extracción automáticas de información clave a partir de grandes volúmenes de documentos no estructurados, agilizando los flujos de trabajo y mejorando los procesos de toma de decisiones.
Asistentes de IA multilingües: Al incorporar incrustaciones vectoriales de varios idiomas, las empresas pueden desarrollar asistentes de IA capaces de entender y responder a los usuarios en su lengua materna, rompiendo las barreras lingüísticas y mejorando la colaboración global.
Mantenimiento predictivo y detección de anomalías: Las bases de datos vectoriales pueden ayudar a identificar patrones y anomalías en los datos de los sensores y los registros de los equipos, lo que permite realizar un mantenimiento proactivo y reducir el tiempo de inactividad en entornos industriales.
A medida que el panorama de la IA empresarial sigue evolucionando a un ritmo acelerado, es crucial que las empresas se mantengan informadas sobre los últimos avances en tecnología de bases de datos vectoriales y LLM. Al mantenerse al día de las nuevas técnicas, herramientas y mejores prácticas, las empresas pueden garantizar que sus aplicaciones de IA sigan siendo competitivas y ofrezcan el máximo valor a sus usuarios.
Al adoptar el futuro de las bases de datos vectoriales y los LLM, las empresas pueden desbloquear nuevos niveles de eficiencia, precisión y conocimiento en sus aplicaciones de IA, impulsando en última instancia el crecimiento y el éxito del negocio en los próximos años.


