
Cómo crear potentes aplicaciones LLM con bases de datos vectoriales + RAG - AI&YOU#55



Estadística/hecho de la semana: 30% de las empresas utilizarán bases de datos vectoriales para fundamentar sus modelos generativos de IA en 2026, frente a 2% en 2023. (Gartner)
LLMs como GPT-4, Claude y Llama 3 se han convertido en potentes herramientas para las empresas que implementan la PLN, demostrando notables capacidades de comprensión y generación de texto similar al humano. Sin embargo, a menudo tienen problemas con el conocimiento del contexto y la precisión, sobre todo cuando se trata de información específica de un dominio.
Por eso, en la edición de esta semana de AI&YOU, exploramos cómo se abordan estos retos a través de tres blogs que hemos publicado:
Combinación de bases de datos vectoriales y RAG para potentes aplicaciones LLM
Las 10 principales ventajas de utilizar una base de datos vectorial de código abierto
Combinación de bases de datos vectoriales y RAG para potentes aplicaciones LLM - AI&YOU #55
Para hacer frente a estos retos, los investigadores y desarrolladores han recurrido a técnicas innovadoras como la Generación Aumentada de Recuperación (RAG) y las bases de datos vectoriales. El GAR mejora los LLM al permitirles acceder y recuperar información relevante de bases de conocimiento externas, mientras que las bases de datos vectoriales ofrecen una solución eficiente y escalable para almacenar y consultar representaciones de datos de alta dimensión.
La sinergia entre las bases de datos vectoriales y el GAR
Las bases de datos vectoriales y la RAG forman una poderosa sinergia que mejora las capacidades de los grandes modelos lingüísticos. En el núcleo de esta sinergia se encuentra el almacenamiento y la recuperación eficaces de las incrustaciones de las bases de conocimiento. Las bases de datos vectoriales están diseñadas para manejar representaciones vectoriales de datos de alta dimensión. Permiten una búsqueda de similitudes rápida y precisa, lo que permite a los LLM recuperar rápidamente información relevante de vastas bases de conocimiento.
Al integrar las bases de datos vectoriales con RAG, podemos crear un canal sin fisuras para aumentar las respuestas de los LLM con conocimientos externos. Cuando un LLM recibe una consulta, RAG puede buscar eficientemente en la base de datos vectorial la información más relevante basada en la incrustación de la consulta. Esta información recuperada se utiliza entonces para enriquecer el contexto del LLM, permitiéndole generar respuestas más precisas e informativas en tiempo real.
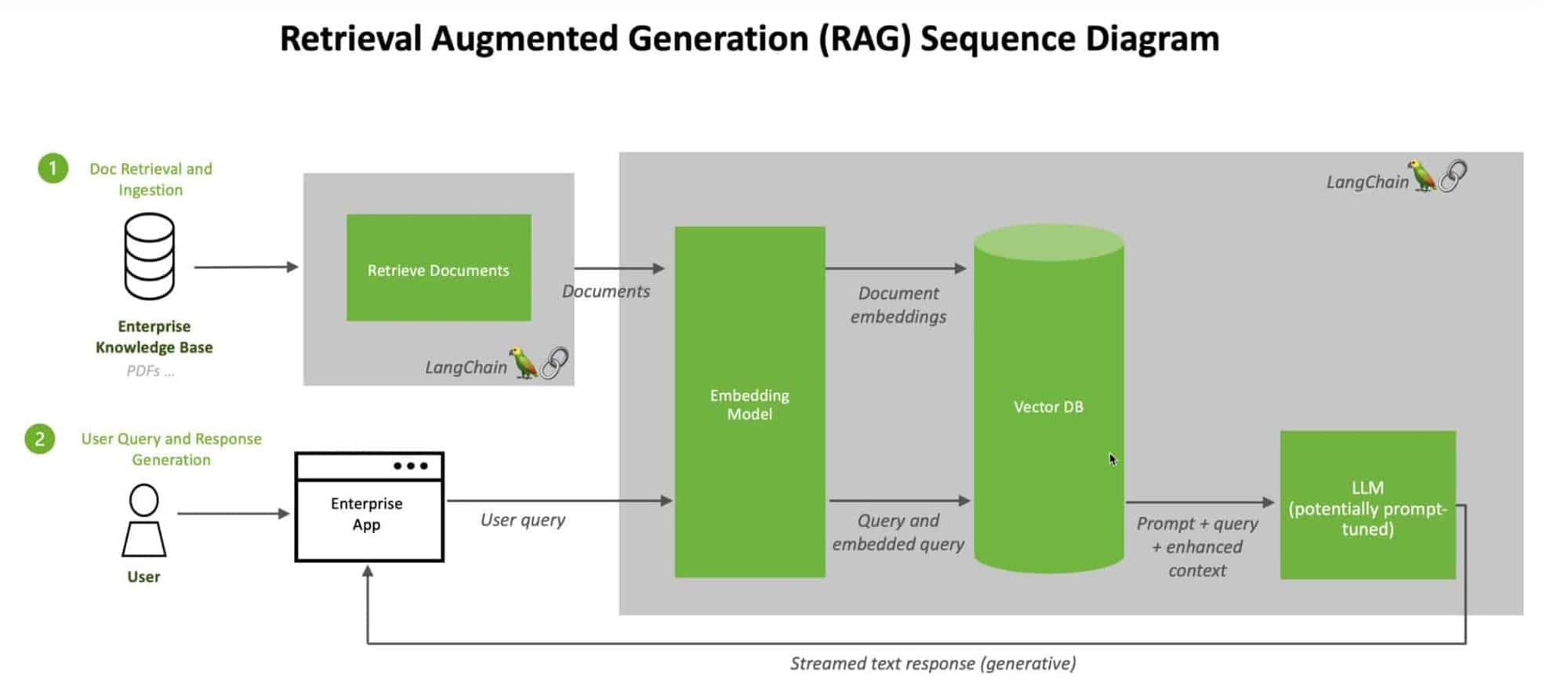
Ventajas de combinar bases de datos vectoriales y GAR
La combinación de bases de datos vectoriales y RAG ofrece varias ventajas significativas para las aplicaciones de modelos lingüísticos de gran tamaño:
Mejora de la precisión y reducción de las alucinaciones
Una de las principales ventajas de combinar bases de datos vectoriales y GAR es la notable mejora de la precisión de las respuestas de los LLM. Al proporcionar a los LLM acceso a conocimientos externos relevantes, la GAR ayuda a reducir la aparición de "alucinaciones", es decir, casos en los que el modelo genera información incoherente o incorrecta. Con la capacidad de recuperar e incorporar información específica del dominio procedente de fuentes fiables, los LLM pueden producir resultados más precisos y fiables.
Escalabilidad y rendimiento
Las bases de datos vectoriales están diseñadas para escalar de forma eficiente, lo que les permite manejar grandes volúmenes de datos de alta dimensión. Esta escalabilidad es crucial cuando se trata de bases de conocimiento extensas que deben buscarse y recuperarse en tiempo real. Al aprovechar la potencia de las bases de datos vectoriales, RAG puede realizar búsquedas de similitud rápidas y eficientes, lo que permite a los LLM generar respuestas rápidamente sin comprometer la calidad de la información recuperada.
Aplicaciones específicas de dominio
La combinación de bases de datos vectoriales y RAG abre nuevas posibilidades para crear aplicaciones LLM específicas de cada dominio. Al curar bases de conocimiento específicas de varios dominios, los LLM pueden adaptarse para proporcionar información precisa y relevante dentro de esos contextos. Esto permite el desarrollo de asistentes de IA especializados, chatbots y sistemas de gestión del conocimiento que pueden satisfacer las necesidades únicas de diferentes industrias y casos de uso.

Aplicación del GAR con bases de datos vectoriales
Para aprovechar la potencia de la combinación de bases de datos vectoriales y GAR, es esencial comprender el proceso de aplicación.
Exploremos los pasos clave para configurar un sistema GAR con una base de datos vectorial:
Indexación y almacenamiento de incrustaciones de bases de conocimiento: El primer paso consiste en convertir los datos de texto de la base de conocimientos en vectores de alta dimensión utilizando modelos de incrustación como BERT, y después indexar y almacenar estas incrustaciones en la base de datos vectorial para una búsqueda y recuperación de similitudes eficientes.
Búsqueda de información relevante en la base de datos de vectores: Cuando un LLM recibe una consulta, el sistema RAG transforma la consulta en una representación vectorial utilizando el mismo modelo de incrustación, y la base de datos vectorial realiza una búsqueda de similitud para recuperar las incrustaciones de la base de conocimientos más relevantes en función de una métrica de similitud elegida.
Integración de la información recuperada en las respuestas del LLM: La información relevante recuperada de la base de datos vectorial se integra en el proceso de generación de respuestas del LLM, ya sea concatenándola con la consulta original o utilizando técnicas como los mecanismos de atención, lo que permite al LLM generar respuestas más precisas e informativas basadas en el contexto aumentado.
Elegir la base de datos vectorial adecuada para su aplicación: La selección de la base de datos vectorial adecuada es crucial, teniendo en cuenta factores como la escalabilidad, el rendimiento, la facilidad de uso y la compatibilidad con su pila tecnológica existente, así como sus requisitos específicos, como el tamaño de la base de conocimientos, el volumen de consultas y la latencia de respuesta deseada.
Buenas prácticas y consideraciones
Para garantizar el éxito de su implantación de la GAR con bases de datos vectoriales, hay varias prácticas recomendadas y consideraciones a tener en cuenta.
Optimización de la incrustación de bases de conocimiento para la recuperación:
La calidad de la incrustación de la base de conocimientos es crucial, por lo que es necesario experimentar con distintos modelos y técnicas de incrustación, perfeccionarla con datos específicos del ámbito y actualizarla y ampliarla periódicamente a medida que se dispone de nueva información para mantener su pertinencia y precisión.
Equilibrio entre velocidad de recuperación y precisión:
Existe un equilibrio entre velocidad de recuperación y precisión, lo que requiere técnicas como la búsqueda aproximada del vecino más próximo para acelerar la recuperación manteniendo una precisión aceptable, así como el almacenamiento en caché de las incrustaciones a las que se accede con más frecuencia y la aplicación de estrategias de equilibrio de carga para optimizar el rendimiento.
Garantizar la seguridad y privacidad de los datos:
Establecer un almacenamiento seguro de los datos, controles de acceso y técnicas de cifrado como el cifrado homomórfico es esencial para impedir el acceso no autorizado y proteger los datos sensibles de las bases de conocimiento incrustadas, respetando al mismo tiempo la normativa pertinente sobre protección de datos.
Supervisión y mantenimiento del sistema:
La supervisión continua de parámetros como la latencia de las consultas, la precisión de las recuperaciones y la utilización de recursos, la implantación de mecanismos automatizados de supervisión y alerta, y el establecimiento de un sólido programa de mantenimiento, que incluya copias de seguridad, actualizaciones y ajustes de rendimiento, son vitales para garantizar el rendimiento y la fiabilidad a largo plazo del sistema GAR.
Aproveche la potencia de las bases de datos vectoriales y RAG en su empresa
A medida que la IA sigue dando forma a nuestro futuro, es crucial que su empresa se mantenga a la vanguardia de estos avances tecnológicos. Explorando e implementando técnicas de vanguardia como las bases de datos vectoriales y RAG, puede liberar todo el potencial de los grandes modelos lingüísticos y crear sistemas de IA más inteligentes, adaptables y que proporcionen un mayor retorno de la inversión.
Las 10 principales ventajas de utilizar una base de datos vectorial de código abierto
Entre las soluciones de bases de datos vectoriales, las de código abierto ofrecen una atractiva combinación de flexibilidad, escalabilidad y rentabilidad. Al aprovechar el poder colectivo de la comunidad de código abierto, estas bases de datos vectoriales especializadas están redefiniendo la forma en que las organizaciones abordan la gestión y el análisis de datos.
Esta semana, nuestro blog también ha analizado las 10 principales ventajas de utilizar una base de datos vectorial de código abierto:
La escalabilidad y la rentabilidad permiten un crecimiento continuo sin costes elevados, eliminando la dependencia de un proveedor y ofreciendo una solución económica.
La flexibilidad y la personalización permiten adaptar la base de datos a necesidades específicas, modificar su funcionalidad e integrarla con sistemas existentes.
El tratamiento eficaz de los datos no estructurados aprovecha técnicas como la PNL y la incrustación de vectores para el almacenamiento, la búsqueda y el análisis efectivos.
La potente búsqueda por similitud vectorial facilita una recuperación precisa basada en la similitud semántica, lo que permite aplicaciones como las recomendaciones personalizadas y el descubrimiento inteligente de contenidos.
La integración con ecosistemas de código abierto garantiza la interoperabilidad con herramientas y marcos complementarios, mejorando la productividad y fomentando la colaboración.
Las sólidas medidas de seguridad y privacidad de los datos dan prioridad a la transparencia, el cifrado, el control de acceso y el cumplimiento de las normas.
El alto rendimiento y la gestión eficaz de los datos ofrecen una ejecución de consultas rapidísima y versatilidad para diversas cargas de trabajo.
La compatibilidad con la analítica avanzada y el aprendizaje automático permite una integración perfecta con técnicas y marcos de vanguardia.
Su arquitectura escalable y preparada para el futuro permite un crecimiento y una adaptación continuos a las nuevas tecnologías y a la evolución de las necesidades de datos.
La innovación y el apoyo impulsados por la comunidad fomentan la mejora continua, el intercambio de conocimientos y recursos inestimables para aprovechar estas potentes herramientas.
Las 5 mejores bases de datos vectoriales para su empresa
Además de las principales ventajas, esta semana también hemos publicado un blog sobre las 5 mejores bases de datos vectoriales para su empresa:
1. Croma
Chroma está diseñado para integrarse sin problemas con modelos y marcos de aprendizaje automático, lo que simplifica el proceso de creación de aplicaciones basadas en IA. Ofrece almacenamiento vectorial eficiente, recuperación, búsqueda por similitud, indexación en tiempo real y almacenamiento de metadatos. Admite varias métricas de distancia y algoritmos de indexación para un rendimiento óptimo en casos de uso como la búsqueda semántica, las recomendaciones y la detección de anomalías.

2. Piña
Pinecone es una base de datos vectorial sin servidor totalmente gestionada que prioriza el alto rendimiento y la facilidad de uso. Combina algoritmos avanzados de búsqueda vectorial con filtrado e infraestructura distribuida para una búsqueda vectorial rápida y fiable a escala. Se integra a la perfección con marcos de aprendizaje automático y fuentes de datos para aplicaciones como búsqueda semántica, recomendaciones, detección de anomalías y respuesta a preguntas.
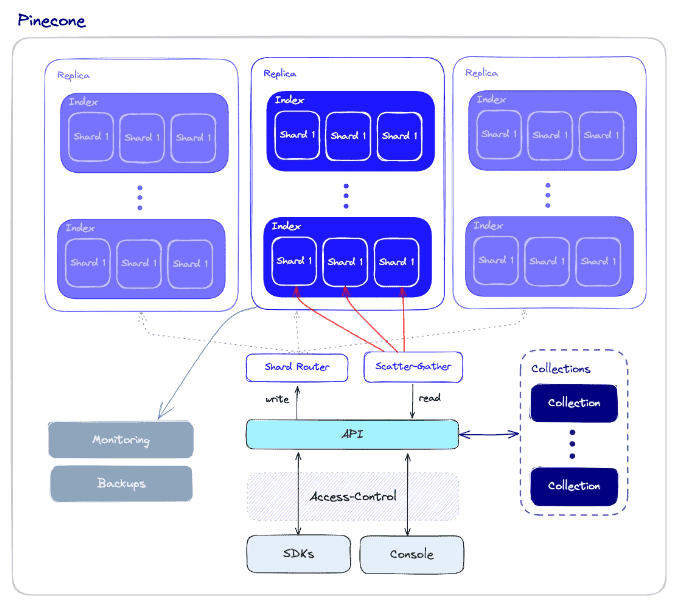
3. Qdrant
Qdrant es un motor de búsqueda de similitud vectorial de código abierto, de alta velocidad y escalable escrito en Rust. Proporciona una API práctica para almacenar, buscar y gestionar vectores con metadatos, lo que permite aplicaciones listas para la producción para hacer coincidir, buscar, recomendar y mucho más. Entre sus características se incluyen actualizaciones en tiempo real, filtrado avanzado, índices distribuidos y opciones de despliegue nativo en la nube.
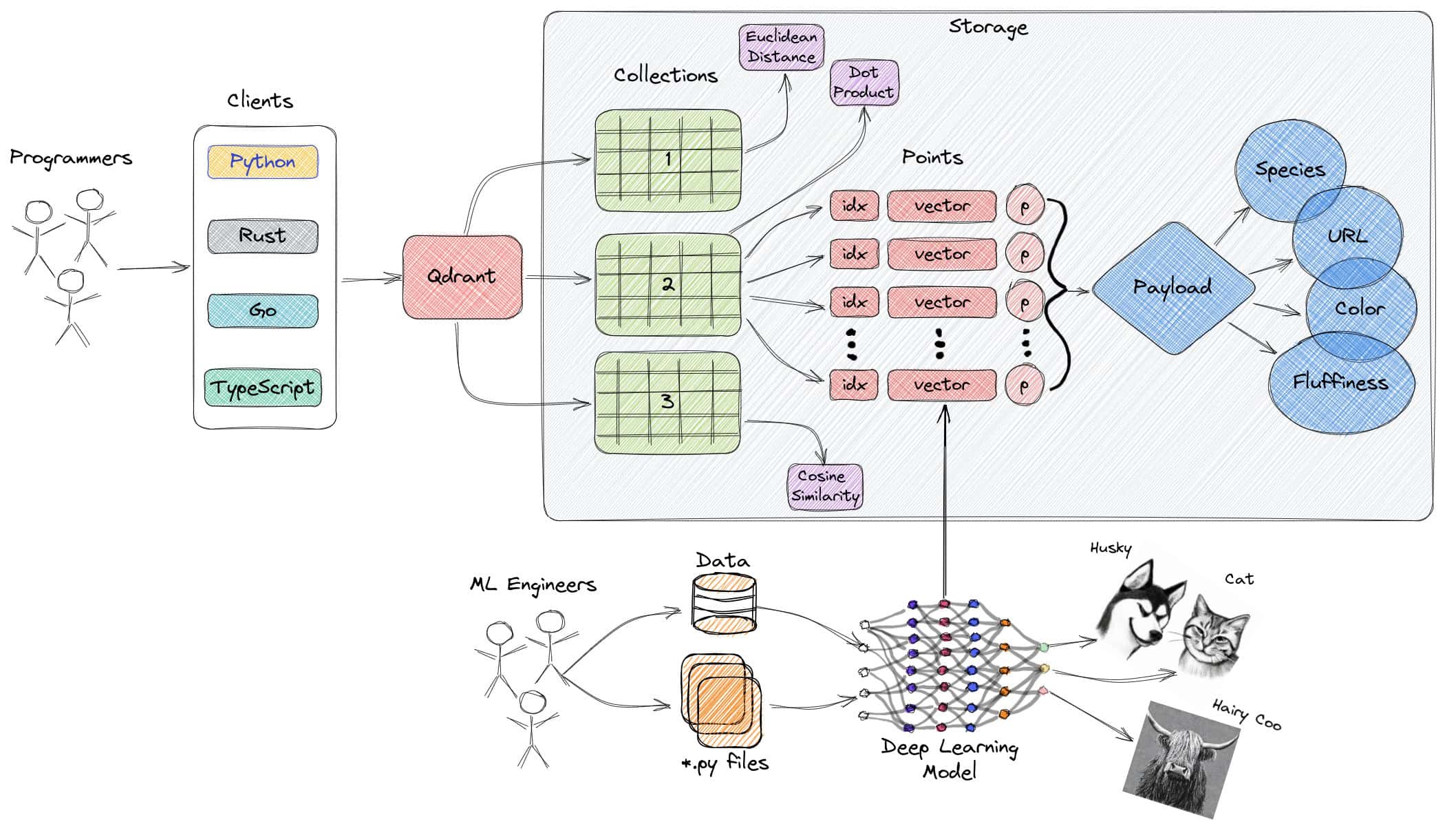
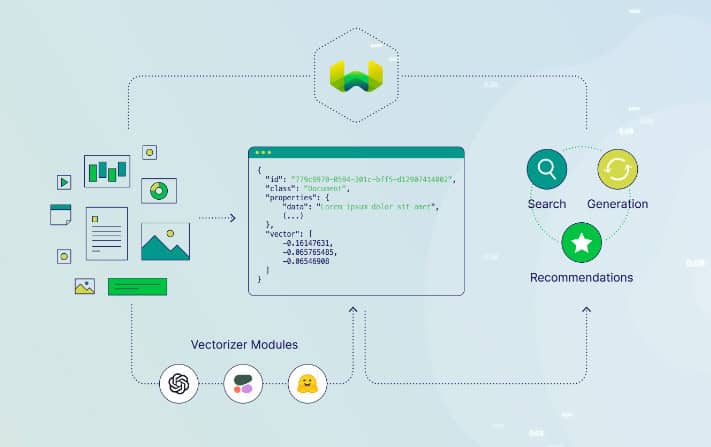
4. Weaviate
Weaviate es una base de datos vectorial de código abierto que prioriza la velocidad, la escalabilidad y la facilidad de uso. Permite almacenar tanto objetos como vectores, combinando la búsqueda vectorial con el filtrado estructurado. Ofrece una API basada en GraphQL, operaciones CRUD, escalado horizontal y despliegue nativo en la nube. Incorpora módulos para tareas NLP, configuración automática de esquemas y vectorización personalizada.
5. Milvus
Milvus es una base de datos vectorial de código abierto diseñada para la gestión de incrustaciones, la búsqueda de similitudes y las aplicaciones de IA escalables. Ofrece soporte informático heterogéneo, fiabilidad de almacenamiento, métricas completas y una arquitectura nativa en la nube. Proporciona una API flexible para índices, métricas de distancia y tipos de consulta, y puede escalar a miles de millones de vectores con plugins personalizados.
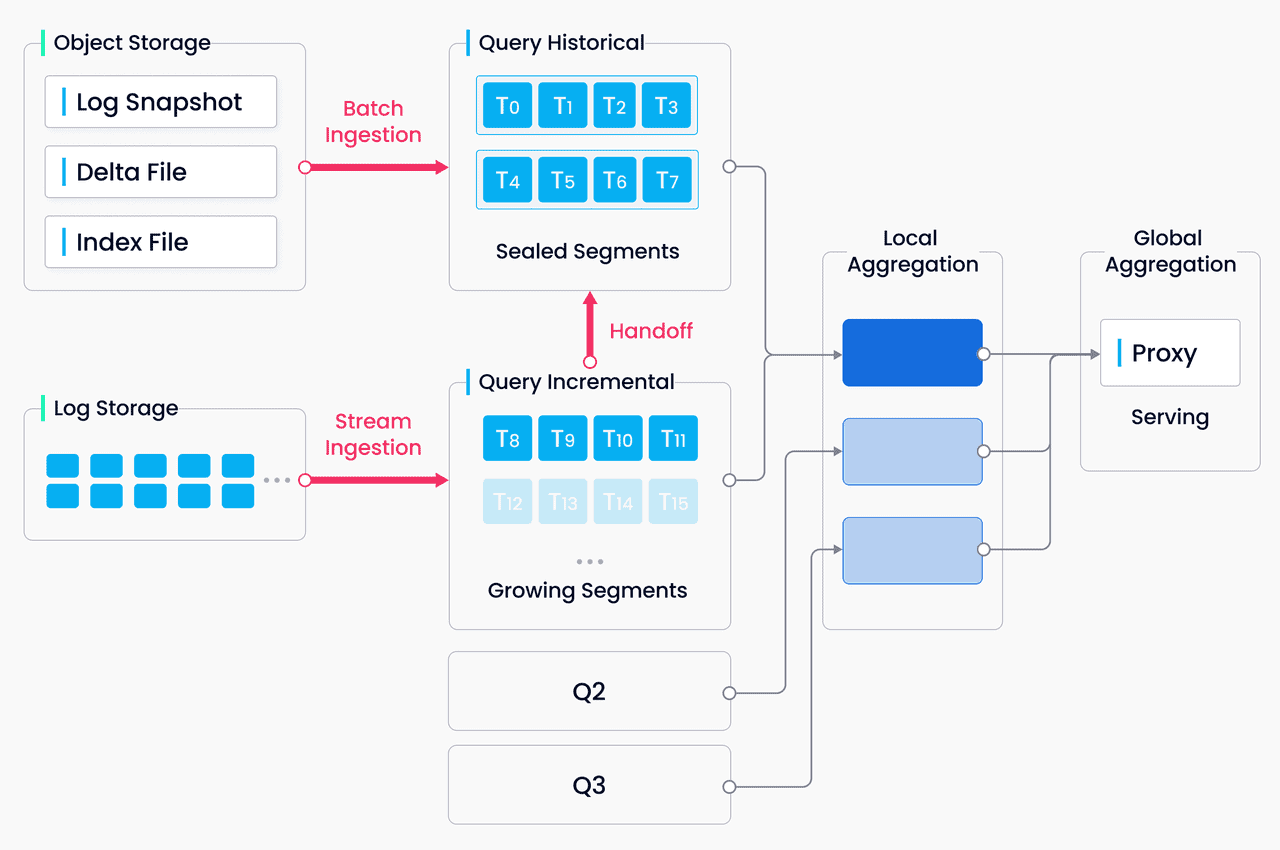
Elección de la base de datos vectorial adecuada para su empresa
Tanto si está creando un motor de búsqueda semántica, un sistema de recomendación o cualquier otra aplicación basada en IA, las bases de datos vectoriales proporcionan la base para liberar todo el potencial de los modelos de aprendizaje automático. Al permitir la búsqueda rápida de similitudes, el filtrado avanzado y la integración perfecta con marcos de trabajo populares, estas bases de datos permiten a los desarrolladores centrarse en la creación de soluciones innovadoras sin preocuparse por las complejidades subyacentes de la gestión de datos vectoriales.
Para obtener más contenido sobre IA empresarial, como infografías, estadísticas, guías prácticas, artículos y vídeos, siga a Skim AI en LinkedIn
¿Es usted fundador, consejero delegado, inversor o capitalista de riesgo y busca servicios expertos de asesoramiento o diligencia debida en IA? Obtenga la orientación que necesita para tomar decisiones informadas sobre la estrategia de productos de IA de su empresa o las oportunidades de inversión.
Construimos Soluciones de IA para empresas respaldadas por capital riesgo y capital privado en los siguientes sectores: Tecnología médica, noticias/agregación de contenidos, producción cinematográfica y fotográfica, tecnología educativa, tecnología jurídica, fintech y criptomoneda.


