
10 estrategias probadas para reducir los costes de su LLM - AI&YOU #65



La estadística de la semana: El uso de LLM más pequeños como GPT-J en cascada puede reducir el coste total en 80% y mejorar la precisión en 1,5% en comparación con GPT-4. (Dataiku)
A medida que las organizaciones confían cada vez más en los grandes modelos lingüísticos (LLM) para diversas aplicaciones, los costes operativos asociados a su despliegue y mantenimiento pueden descontrolarse rápidamente sin una supervisión y unas estrategias de optimización adecuadas.
Meta también ha lanzado Llama 3.1, que ha dado mucho que hablar últimamente por ser el LLM de código abierto más avanzado hasta la fecha.
En la edición de esta semana de AI&YOU, exploramos las ideas de tres blogs que hemos publicado sobre estos temas:
Comprender las estructuras de precios LLM: Entradas, salidas y ventanas contextuales
Llama 3.1 de Meta: Superando los límites de la IA de código abierto
10 estrategias probadas para reducir los costes de su LLM - AI&YOU #65
Esta entrada de blog explorará diez estrategias probadas para ayudar a su empresa a gestionar eficazmente los costes de LLM, asegurándose de que puede aprovechar todo el potencial de estos modelos a la vez que mantiene la rentabilidad y el control de los gastos.
1. Selección inteligente de modelos
Optimice los costes de su LLM ajustando cuidadosamente la complejidad del modelo a los requisitos de la tarea. No todas las aplicaciones necesitan el modelo más reciente y de mayor tamaño. Para tareas más sencillas, como la clasificación básica o las preguntas y respuestas directas, considere la posibilidad de utilizar modelos preentrenados más pequeños y eficientes. Este enfoque puede suponer un ahorro sustancial sin comprometer el rendimiento.
Por ejemplo, emplear DistilBERT para el análisis de sentimientos en lugar de BERT-Large puede reducir significativamente la sobrecarga computacional y los gastos asociados, manteniendo al mismo tiempo una alta precisión para la tarea específica en cuestión.
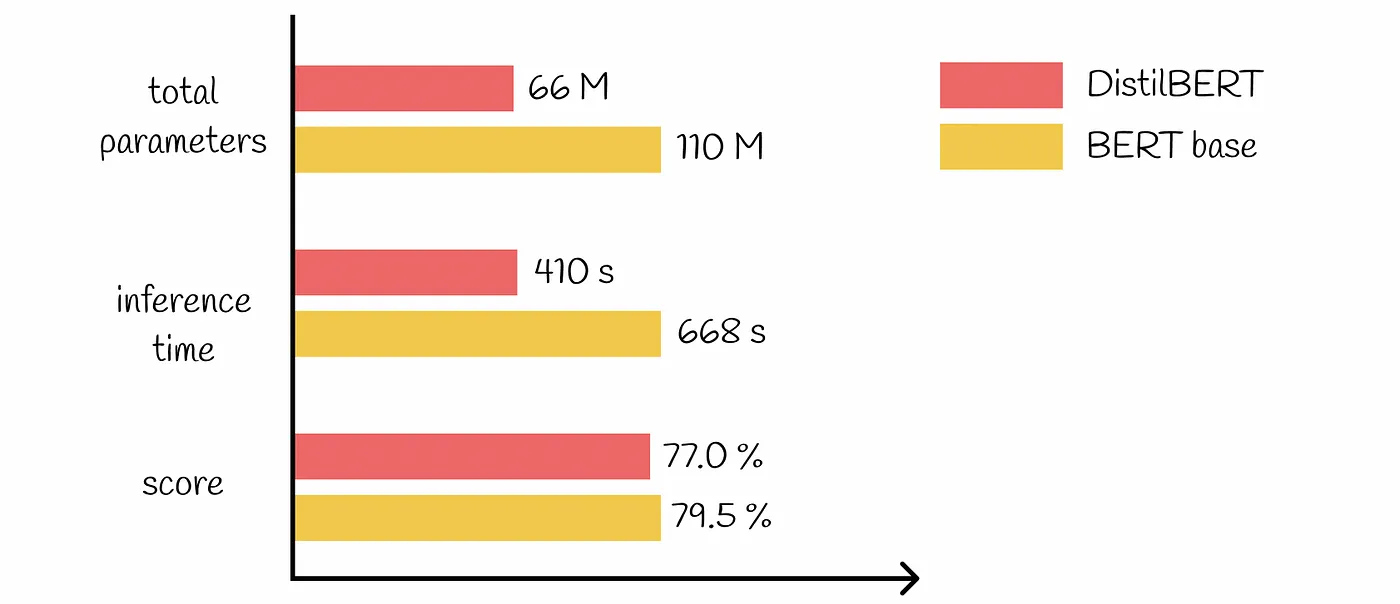
2. Implantar un sólido seguimiento del uso
Obtenga una visión completa de su Uso del LLM implementando mecanismos de seguimiento multinivel. Supervise el uso de tokens, los tiempos de respuesta y las llamadas modelo a nivel de conversación, usuario y empresa. Aproveche los paneles de análisis incorporados de los proveedores de LLM o implante soluciones de seguimiento personalizadas integradas en su infraestructura.
Esta visión granular le permite identificar ineficiencias, como departamentos que utilizan en exceso modelos caros para tareas sencillas o patrones de consultas redundantes. El análisis de estos datos permite descubrir valiosas estrategias de reducción de costes y optimizar el consumo global de LLM.
3. Optimizar la ingeniería Prompt
Perfeccione sus técnicas de ingeniería de avisos para reducir significativamente el uso de tokens y mejorar la eficiencia de LLM. Elabore instrucciones claras y concisas en sus avisos, implemente la gestión de errores para resolver problemas comunes sin consultas adicionales y utilice plantillas de avisos probadas para tareas específicas. Estructure sus avisos de manera eficiente evitando el contexto innecesario, utilizando técnicas de formato como viñetas y aprovechando las funciones integradas para controlar la longitud de la salida.
Estas optimizaciones pueden reducir sustancialmente el consumo de tokens y los costes asociados, manteniendo o incluso mejorando la calidad de los resultados de su LLM.
4. Aprovechar el ajuste fino para la especialización
Utilice el poder del ajuste fino para crear modelos más pequeños y eficientes adaptados a sus necesidades específicas. Aunque requiere una inversión inicial, este enfoque puede suponer importantes ahorros a largo plazo. Los modelos ajustados suelen requerir menos tokens para lograr resultados iguales o mejores, lo que reduce los costes de inferencia y la necesidad de reintentos o correcciones.
Empiece con un modelo preentrenado más pequeño, utilice datos específicos de dominio de alta calidad para el ajuste fino y evalúe periódicamente el rendimiento y la rentabilidad. Esta optimización continua garantiza que sus modelos sigan aportando valor al tiempo que se mantienen controlados los costes operativos.
5. Explore opciones gratuitas y de bajo coste
Aproveche las opciones de LLM gratuitas o de bajo coste, especialmente durante las fases de desarrollo y pruebas, para reducir significativamente los gastos sin comprometer la calidad. Estas alternativas son especialmente valiosas para la creación de prototipos, la formación de desarrolladores y los servicios no críticos o de cara al interior.
Sin embargo, evalúe cuidadosamente las ventajas y desventajas, teniendo en cuenta la privacidad de los datos, las implicaciones para la seguridad y las posibles limitaciones en las capacidades o la personalización. Evalúe la escalabilidad a largo plazo y las vías de migración para asegurarse de que las medidas de ahorro se ajustan a los planes de crecimiento futuro y no se convierten en obstáculos.
6. Optimizar la gestión de ventanas contextuales
Gestione eficazmente las ventanas de contexto para controlar los costes y mantener al mismo tiempo la calidad de los resultados. Aplique tamaños de contexto dinámicos basados en la complejidad de la tarea, utilice técnicas de resumen para condensar la información relevante y emplee enfoques de ventanas deslizantes para documentos o conversaciones largos. Analice periódicamente la relación entre el tamaño del contexto y la calidad del resultado, ajustando las ventanas en función de los requisitos específicos de la tarea.
Considere un enfoque escalonado, utilizando contextos más grandes sólo cuando sea necesario. Esta gestión estratégica de las ventanas de contexto puede reducir significativamente el uso de tokens y los costes asociados sin sacrificar las capacidades de comprensión de sus aplicaciones LLM.
7. Implantar sistemas multiagente
Aumentar la eficiencia y la rentabilidad implementando arquitecturas LLM multiagente. Este enfoque implica la colaboración de varios agentes de IA para resolver problemas complejos, lo que permite optimizar la asignación de recursos y reducir la dependencia de modelos caros a gran escala.
Los sistemas multiagente permiten el despliegue selectivo de modelos, lo que mejora la eficacia general del sistema y los tiempos de respuesta, al tiempo que reduce el uso de tokens. Para mantener la rentabilidad, implante mecanismos de depuración sólidos, como el registro de las comunicaciones entre agentes y el análisis de los patrones de uso de tokens.
Al optimizar la división del trabajo entre los agentes, puede minimizar el consumo innecesario de tokens y maximizar los beneficios de la gestión de tareas distribuidas.
8. Utilizar las herramientas de formato de salida
Aproveche las herramientas de formato de salida para garantizar un uso eficiente de los tokens y minimizar las necesidades de procesamiento adicionales. Implemente salidas de funciones forzadas para especificar formatos de respuesta exactos, reduciendo la variabilidad y el desperdicio de tokens. Este enfoque disminuye la probabilidad de salidas mal formadas y la necesidad de realizar llamadas a la API para aclaraciones.
Considere el uso de salidas JSON por su representación compacta de datos estructurados, fácil análisis sintáctico y uso reducido de tokens en comparación con las respuestas en lenguaje natural. Al agilizar sus flujos de trabajo LLM con estas herramientas de formateo, puede optimizar significativamente el uso de tokens y reducir los costes operativos, manteniendo al mismo tiempo resultados de alta calidad.
9. Integrar herramientas que no sean LLM
Complemente sus aplicaciones LLM con herramientas que no sean LLM para optimizar costes y eficacia. Incorpore secuencias de comandos Python o enfoques de programación tradicionales para tareas que no requieren todas las capacidades de un LLM, como el procesamiento sencillo de datos o la toma de decisiones basada en reglas.
A la hora de diseñar flujos de trabajo, equilibre cuidadosamente el LLM y las herramientas convencionales en función de la complejidad de la tarea, la precisión requerida y el posible ahorro de costes. Realice análisis exhaustivos de rentabilidad teniendo en cuenta factores como los costes de desarrollo, el tiempo de procesamiento, la precisión y la escalabilidad a largo plazo. Este enfoque híbrido suele dar los mejores resultados en términos de rendimiento y rentabilidad.
10. Auditoría y optimización periódicas
Implemente un sistema sólido de auditoría y optimización periódicas para garantizar una gestión continua de los costes de LLM. Supervise y analice constantemente el uso de su LLM para identificar ineficiencias, como consultas redundantes o ventanas de contexto excesivas. Utilice herramientas de seguimiento y análisis para perfeccionar sus estrategias de LLM y eliminar el consumo innecesario de tokens.
Fomente una cultura de conciencia de costes dentro de su organización, animando a los equipos a considerar activamente las implicaciones de costes de su uso de LLM y a buscar oportunidades de optimización. Al hacer de la rentabilidad una responsabilidad compartida, puedes maximizar el valor de tus inversiones en IA al tiempo que mantienes los gastos bajo control a largo plazo.
Comprender las estructuras de precios LLM: Entradas, salidas y ventanas contextuales
Para las estrategias empresariales de IA, comprender las estructuras de precios de los LLM es crucial para una gestión eficaz de los costes. Los costes operativos asociados a los LLM pueden aumentar rápidamente sin una supervisión adecuada, lo que puede dar lugar a picos de costes inesperados que pueden desbaratar los presupuestos y obstaculizar la adopción generalizada.
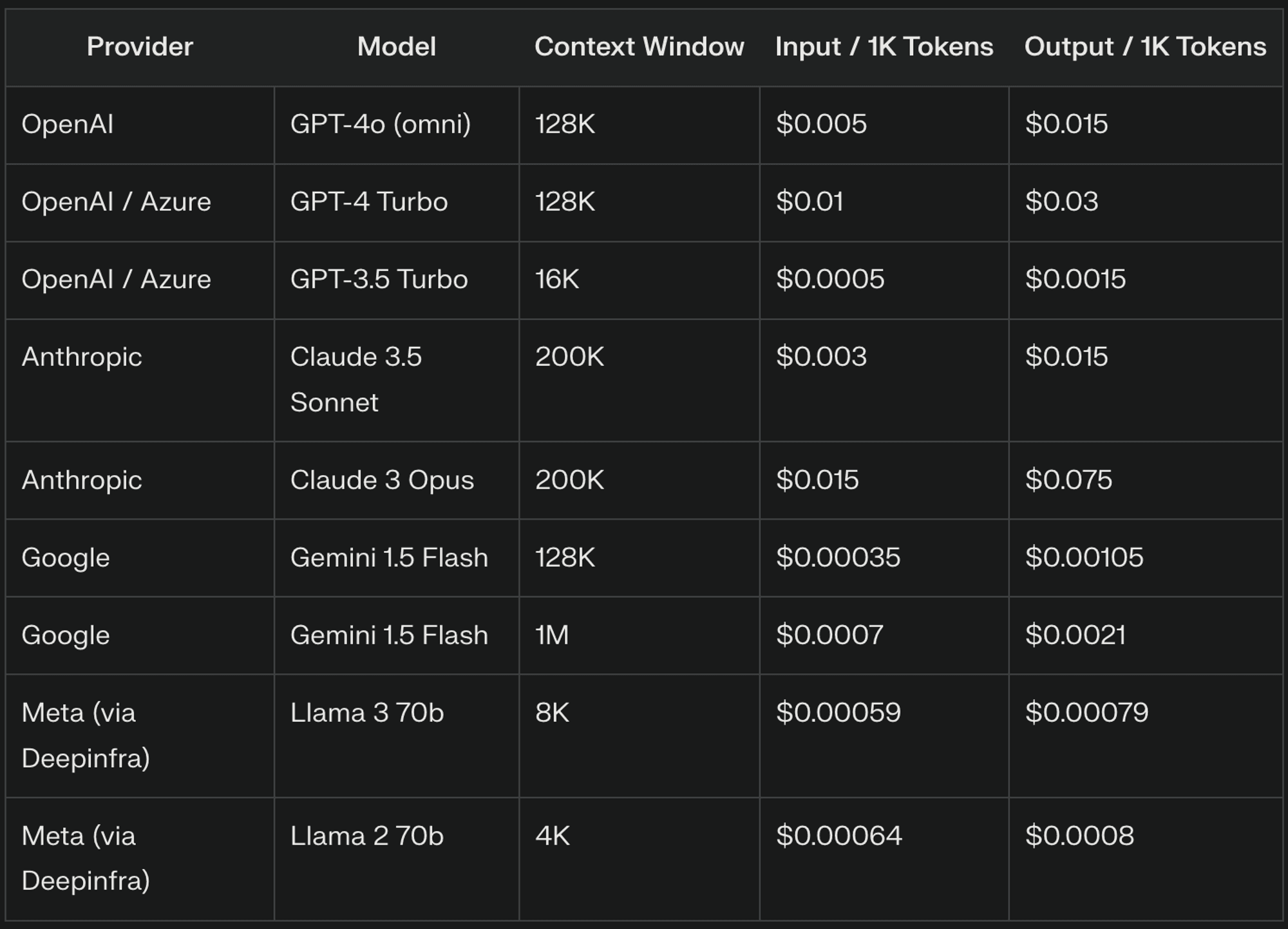
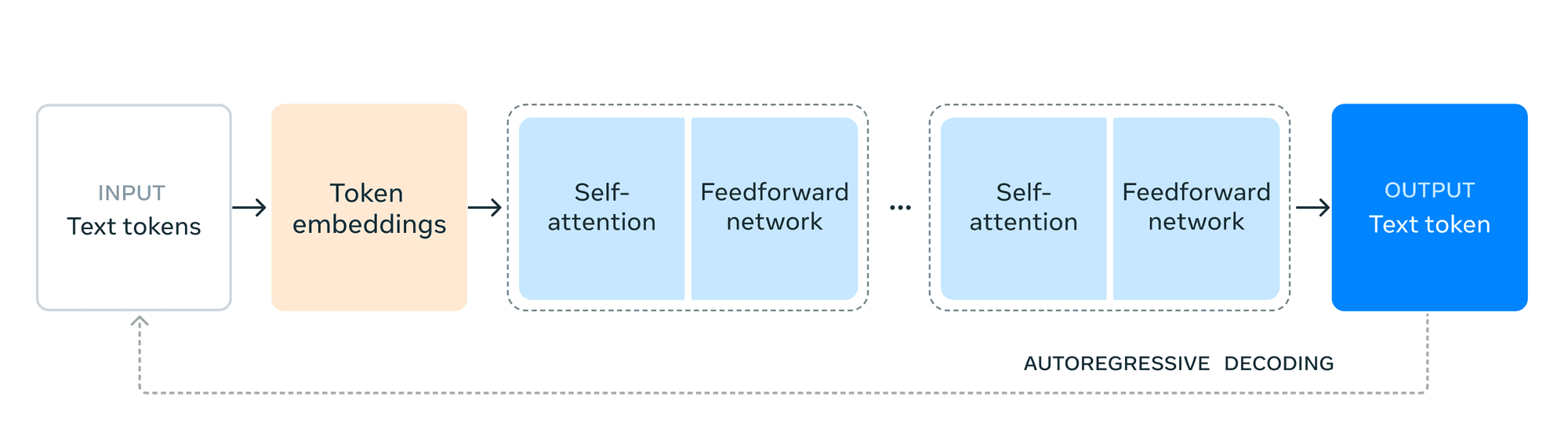
Los precios de los LLM suelen girar en torno a tres componentes principales: fichas de entrada, fichas de salida y ventanas contextuales. Cada uno de estos elementos desempeña un papel importante a la hora de determinar el coste global de utilizar LLM en sus aplicaciones
Fichas de Entrada: Qué son y cómo se cobran
Los tokens de entrada son las unidades fundamentales del texto procesado por los LLM, que suelen corresponder a partes de palabras. Por ejemplo, "The quick brown fox" podría tokenizarse como ["The", "quick", "bro", "wn", "fox"], lo que daría como resultado 5 tokens de entrada. Los proveedores de LLM suelen cobrar por los tokens de entrada una tarifa por cada mil tokens, con precios que varían significativamente entre proveedores y versiones de modelos.
Para optimizar el uso de fichas de entrada y reducir costes, tenga en cuenta estas estrategias:
Elabore indicaciones concisas: Concéntrese en instrucciones claras y directas.
Utilice una codificación eficiente: Elija métodos que representen el texto con menos tokens.
Implantar plantillas de avisos: Desarrollar estructuras optimizadas para tareas comunes.
Aproveche las técnicas de compresión: Reduzca el tamaño de la entrada sin perder información crítica.
Fichas de salida: Entender los costes
Los tokens de salida representan el texto generado por el LLM en respuesta a su entrada. El número de tokens de salida puede variar significativamente en función de la tarea y de la configuración del modelo. Los proveedores de LLM suelen cobrar más por los tokens de salida que por los de entrada debido a la complejidad computacional de la generación de texto.
Para optimizar el uso de fichas de salida y controlar los costes:
Establezca límites claros de longitud de salida en sus avisos o llamadas a la API.
Utilice el "aprendizaje de pocos disparos" para guiar al modelo hacia respuestas concisas.
Aplique el posprocesamiento para recortar el contenido innecesario.
Considere la posibilidad de almacenar en caché información solicitada con frecuencia.
Utilice las herramientas de formato de salida para garantizar un uso eficaz de los tokens.
Ventanas contextuales: El factor de coste oculto
Las ventanas de contexto determinan la cantidad de texto previo que el LLM tiene en cuenta al generar una respuesta, lo que resulta crucial para mantener la coherencia y hacer referencia a información anterior. Las ventanas de contexto más grandes aumentan el número de tokens de entrada procesados, lo que conlleva mayores costes. Por ejemplo, una ventana de contexto de 8.000 tokens podría cobrar por 7.000 tokens en una conversación, mientras que una ventana de 4.000 tokens sólo cobraría por 3.000.
Para optimizar el uso de la ventana contextual:
Implementar un dimensionamiento dinámico del contexto basado en los requisitos de la tarea.
Utiliza técnicas de resumen para condensar la información relevante.
Emplear enfoques de ventanas deslizantes para documentos largos.
Considere modelos más pequeños y especializados para tareas con necesidades de contexto limitadas.
Analice periódicamente la relación entre el tamaño del contexto y la calidad de los resultados.
Gestionando cuidadosamente estos componentes de las estructuras de precios LLM, las empresas pueden reducir los costes operativos manteniendo la calidad de sus aplicaciones de IA.
Lo esencial
Comprender las estructuras de precios LLM es esencial para una gestión eficaz de los costes en las aplicaciones empresariales de IA. Al comprender los matices de los tokens de entrada, los tokens de salida y las ventanas de contexto, las organizaciones pueden tomar decisiones informadas sobre la selección de modelos y los patrones de uso. La aplicación de técnicas estratégicas de gestión de costes, como la optimización del uso de tokens y el aprovechamiento del almacenamiento en caché, puede suponer un ahorro significativo.
Llama 3.1 de Meta: Superando los límites de la IA de código abierto
En una reciente gran noticia, Meta ha anunciado Llama 3.1su modelo de grandes lenguajes de código abierto más avanzado hasta la fecha. Este lanzamiento marca un hito importante en la democratización de la tecnología de IA, ya que puede salvar la brecha entre los modelos de código abierto y los propietarios.
Llama 3.1 se basa en sus predecesores con varios avances clave:
Mayor tamaño del modelo: La introducción del modelo de parámetros 405B amplía las posibilidades de la IA de código abierto.
Longitud de contexto ampliada: De 4K tokens en Llama 2 a 128K en Llama 3.1, lo que permite una comprensión más compleja y matizada de textos más largos.
Capacidad multilingüe: La mayor compatibilidad lingüística permite aplicaciones más diversas en distintas regiones y casos de uso.
Mejora del razonamiento y de las tareas especializadas: Mayor rendimiento en áreas como el razonamiento matemático y la generación de código.
Cuando se compara con modelos de código cerrado como GPT-4 y Claude 3.5 Sonnet, Llama 3.1 405B no tiene nada que envidiar en varios benchmarks. Este nivel de rendimiento en un modelo de código abierto no tiene precedentes.
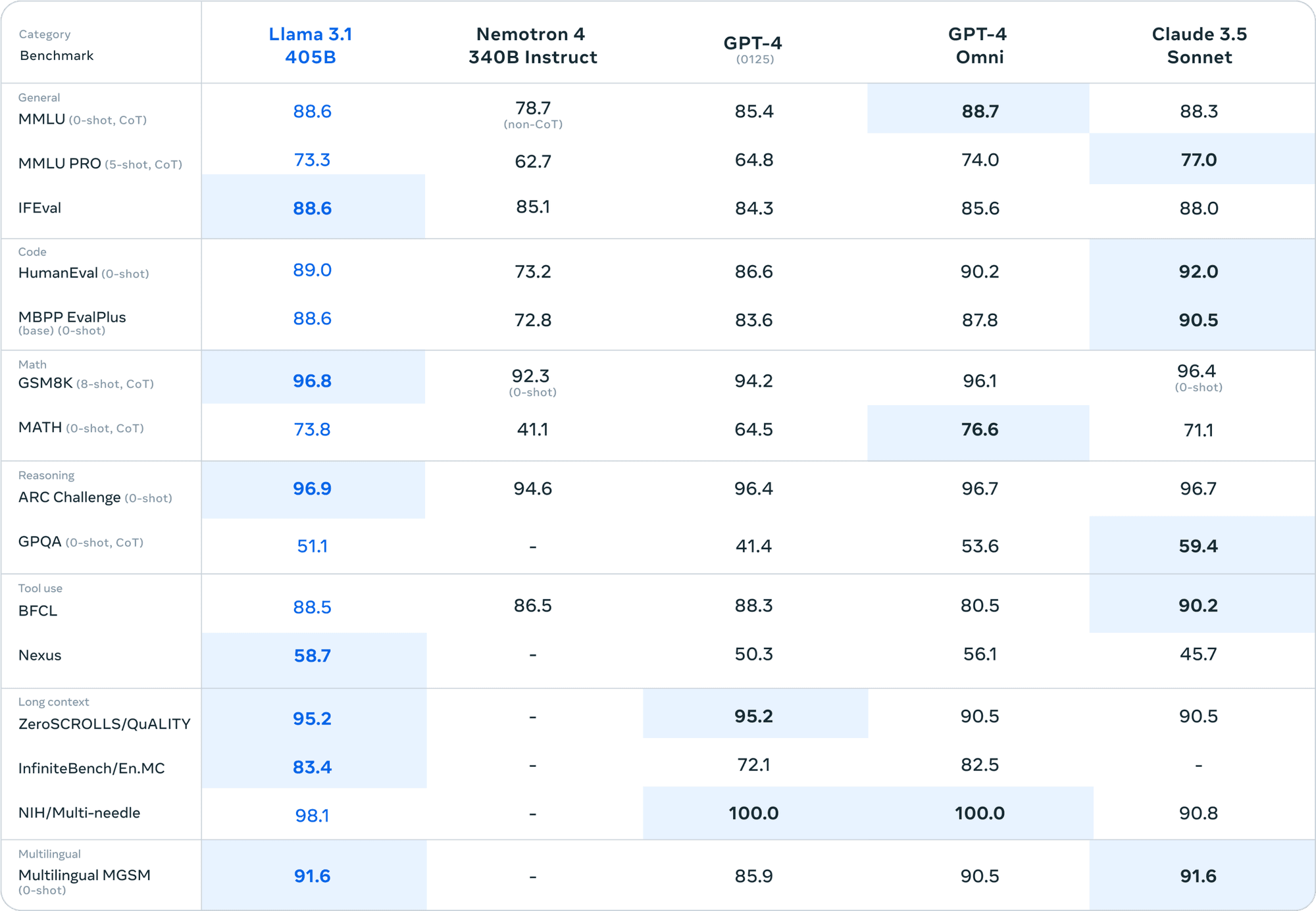
Especificaciones técnicas de Llama 3.1
Entrando en los detalles técnicos, Llama 3.1 ofrece una gama de tamaños de modelo para adaptarse a diferentes necesidades y recursos computacionales:
Modelo de parámetros 8B: Adecuado para aplicaciones ligeras y dispositivos de borde.
Modelo de parámetros 70B: Un equilibrio entre los requisitos de rendimiento y recursos.
Modelo de parámetros 405B: El modelo insignia, que supera los límites de las capacidades de la IA de código abierto.
La metodología de entrenamiento de Llama 3.1 se basó en un enorme conjunto de datos de más de 15 billones de tokens, significativamente mayor que el de sus predecesores.
Arquitectónicamente, Llama 3.1 mantiene un modelo de transformador de sólo decodificador, priorizando la estabilidad del entrenamiento sobre enfoques más experimentales como la mezcla de expertos.
Sin embargo, Meta ha implementado varias optimizaciones para permitir un entrenamiento y una inferencia eficientes a esta escala sin precedentes:
Infraestructura de formación ampliable: Utilización de más de 16.000 GPU H100 para entrenar el modelo 405B.
Procedimiento iterativo de post-entrenamiento: Emplear el ajuste fino supervisado y la optimización directa de preferencias para mejorar capacidades específicas.
Técnicas de cuantificación: Reducción del modelo de 16 bits a 8 bits numéricos para una inferencia más eficaz, lo que permite la implantación en nodos de un solo servidor.
Capacidades revolucionarias
Llama 3.1 introduce varias funciones revolucionarias que la distinguen en el panorama de la IA:
Contexto ampliado Longitud: El salto a una ventana contextual de 128K cambia las reglas del juego. Esta capacidad ampliada permite a Llama 3.1 procesar y comprender fragmentos de texto mucho más largos:
Soporte multilingüe: La compatibilidad de Llama 3.1 con ocho idiomas amplía significativamente su aplicabilidad global.
Razonamiento avanzado y uso de herramientas: El modelo demuestra una capacidad de razonamiento sofisticada y la capacidad de utilizar herramientas externas con eficacia.
Generación de código y destreza matemática: Llama 3.1 muestra notables habilidades en dominios técnicos:
Generación de código funcional de alta calidad en varios lenguajes de programación
Resolver problemas matemáticos complejos con precisión
Asistencia en el diseño y optimización de algoritmos
La promesa y el potencial de Llama 3.1
El lanzamiento de Llama 3.1 por parte de Meta marca un momento crucial en el panorama de la IA, ya que democratiza el acceso a capacidades de IA de vanguardia. Al ofrecer un modelo de 405B parámetros con un rendimiento de última generación, soporte multilingüe y una longitud de contexto ampliada, todo ello dentro de un marco de código abierto, Meta ha establecido un nuevo estándar para una IA accesible y potente. Este paso no sólo desafía el dominio de los modelos de código cerrado, sino que también allana el camino para una innovación y colaboración sin precedentes en la comunidad de la IA.
¡Gracias por tomarse el tiempo de leer AI & YOU!
Para obtener más contenido sobre IA empresarial, como infografías, estadísticas, guías prácticas, artículos y vídeos, siga a Skim AI en LinkedIn
¿Es usted fundador, director general, inversor o capitalista de riesgo y busca servicios de asesoramiento sobre IA, desarrollo fraccionado de IA o diligencia debida? Obtenga la orientación que necesita para tomar decisiones informadas sobre la estrategia de productos de IA y las oportunidades de inversión de su empresa.
Creamos soluciones de IA personalizadas para empresas respaldadas por capital riesgo y capital privado en los siguientes sectores: Tecnología Médica, Noticias/Agregación de Contenidos, Producción de Cine y Fotografía, Tecnología Educativa, Tecnología Legal, Fintech y Criptomoneda.


