
10 estrategias probadas para reducir los costes de su LLM



A medida que las organizaciones confían cada vez más en los grandes modelos lingüísticos (LLM) para diversas aplicaciones, desde los chatbots de atención al cliente hasta la generación de contenidos, el reto de la gestión de costes de los LLM ha pasado a primer plano. Los costes operativos asociados a la implementación y el mantenimiento de los LLM pueden descontrolarse rápidamente sin una supervisión y unas estrategias de optimización adecuadas. Los picos de costes inesperados pueden hacer descarrilar los presupuestos y obstaculizar la adopción generalizada de estas potentes herramientas.
Esta entrada de blog explorará diez estrategias probadas para ayudar a su empresa a gestionar eficazmente los costes de LLM, asegurándose de que puede aprovechar todo el potencial de estos modelos a la vez que mantiene la rentabilidad y el control de los gastos.
Estrategia 1: Selección inteligente de modelos
Una de las estrategias más impactantes para la gestión de costes LLM es seleccionar el modelo adecuado para cada tarea. No todas las aplicaciones requieren los modelos más avanzados y de mayor tamaño disponibles. Al adaptar la complejidad del modelo a los requisitos de la tarea, puede reducir considerablemente los costes sin sacrificar el rendimiento.
Al implementar aplicaciones LLM, es crucial evaluar la complejidad de cada tarea y elegir un modelo que satisfaga esas necesidades específicas. Por ejemplo, las tareas de clasificación sencillas o la respuesta a preguntas básicas pueden no requerir todas las capacidades de GPT-4o u otros modelos de gran tamaño y uso intensivo de recursos.
Existen muchos modelos preentrenados de distintos tamaños y complejidades. Optar por modelos más pequeños y eficientes para tareas sencillas puede suponer un importante ahorro de costes. Por ejemplo, puede utilizar un modelo ligero como DestilBERT para el análisis de sentimientos en lugar de un modelo más complejo como BERT-Grande.
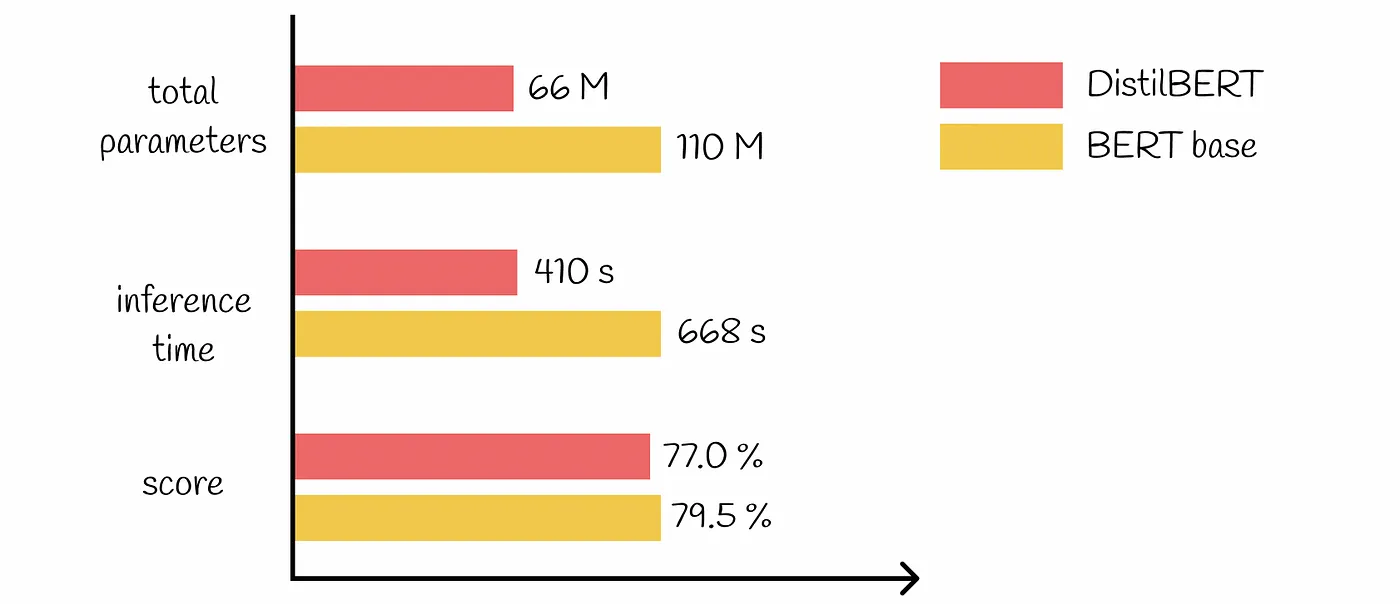
Estrategia 2: Implantar un sólido seguimiento del uso
Una gestión eficaz de los costes de LLM empieza por comprender claramente cómo se utilizan estos modelos en su organización. La implantación de sólidos mecanismos de seguimiento del uso es esencial para identificar áreas de ineficiencia y oportunidades de optimización.
Para tener una visión completa de su Uso del LLMes crucial realizar un seguimiento de las métricas a varios niveles:
Nivel de conversación: Supervise el uso de tokens, los tiempos de respuesta y las llamadas de modelos para interacciones individuales.
Nivel de usuario: Analice los patrones de uso de los modelos en los distintos usuarios o departamentos.
A nivel de empresa: Agregue los datos para comprender el consumo y las tendencias generales del LLM.
Existen varias herramientas y plataformas que ayudan a realizar un seguimiento eficaz del uso del LLM. Entre ellas se incluyen:
Cuadros de mando analíticos integrados proporcionados por los proveedores de servicios LLM
Herramientas de supervisión de terceros diseñadas específicamente para aplicaciones de IA y ML
Soluciones de seguimiento a medida integradas en su infraestructura actual
Al analizar los datos de uso, puede descubrir información valiosa que conduzca a estrategias de reducción de costes. Por ejemplo, puede descubrir que determinados departamentos utilizan en exceso modelos más caros para tareas que podrían realizarse con alternativas de menor coste. O puede identificar patrones de consultas redundantes que podrían abordarse mediante el almacenamiento en caché u otras técnicas de optimización.
Estrategia 3: Optimizar la ingeniería de avisos
Ingeniería rápida es un aspecto crítico del trabajo con LLMs, y puede tener un impacto significativo tanto en el rendimiento como en el coste. Si optimiza sus avisos, podrá reducir el uso de tokens y mejorar la eficiencia de sus aplicaciones LLM.
Para minimizar el número de llamadas a la API y reducir los costes asociados:
Utilice instrucciones claras y específicas en sus indicaciones
Implementar el tratamiento de errores para resolver problemas comunes sin requerir consultas LLM adicionales.
Utilizar plantillas de avisos que hayan demostrado su eficacia para tareas específicas.
La forma de estructurar las solicitudes puede afectar significativamente al número de fichas procesadas por el modelo. Algunas de las mejores prácticas son:
Ser conciso y evitar el contexto innecesario
Utilizar técnicas de formato, como viñetas o listas numeradas, para organizar la información de forma eficaz.
Aprovechamiento de las funciones integradas o de los parámetros proporcionados por el servicio LLM para controlar la longitud y el formato de la salida.
Mediante la aplicación de estas técnicas de optimización rápida, puede reducir sustancialmente el uso de tokens y, en consecuencia, los costes asociados a sus aplicaciones LLM.
Estrategia 4: Aprovechar el ajuste fino para la especialización
El ajuste fino de modelos preentrenados para tareas específicas es una potente técnica de gestión de costes LLM. Al adaptar los modelos a sus necesidades específicas, puede lograr un mejor rendimiento con modelos más pequeños y eficientes, lo que se traduce en un importante ahorro de costes.
En lugar de confiar únicamente en grandes LLM de uso general, considere la posibilidad de ajustar modelos más pequeños para tareas especializadas. Este enfoque le permite aprovechar los conocimientos de los modelos preentrenados al tiempo que los optimiza para su caso de uso específico.
Aunque el ajuste requiere una inversión inicial, puede suponer un ahorro sustancial a largo plazo. Los modelos perfeccionados suelen requerir menos tokens para obtener los mismos o mejores resultados, lo que reduce los costes de inferencia. También pueden requerir menos reintentos o correcciones debido a la mejora de la precisión, lo que reduce aún más los costes. Además, los modelos especializados suelen ser más pequeños, lo que reduce la carga computacional y los gastos asociados.
Para maximizar los beneficios del ajuste fino, empiece con un modelo preentrenado más pequeño como base. Utilice datos específicos de alta calidad para el ajuste y evalúe periódicamente el rendimiento y la rentabilidad del modelo. Este proceso de optimización continua garantiza que los modelos ajustados sigan aportando valor y manteniendo los costes bajo control.
Estrategia 5: Explorar opciones gratuitas y de bajo coste
Para muchas empresas, sobre todo durante las fases de desarrollo y prueba, el aprovechamiento del opciones LLM gratuitas o de bajo coste pueden reducir significativamente los gastos sin comprometer la calidad. Estas opciones son especialmente valiosas para crear prototipos de nuevas aplicaciones LLM, formar a desarrolladores en la implementación de LLM y ejecutar servicios no críticos o internos.
Sin embargo, aunque las opciones gratuitas pueden reducir drásticamente los costes, es crucial tener en cuenta las contrapartidas. Deben evaluarse cuidadosamente las implicaciones para la privacidad y la seguridad de los datos, especialmente cuando se trata de información sensible. Además, hay que ser consciente de las posibles limitaciones en las capacidades del modelo o las opciones de personalización. Considere la escalabilidad a largo plazo y las vías de migración para asegurarse de que sus medidas de ahorro no se convierten en obstáculos para el crecimiento futuro.
Estrategia 6: Optimizar la gestión de ventanas contextuales
El tamaño de la ventana de contexto en los LLM puede influir significativamente tanto en el rendimiento como en los costes. La gestión eficaz de las ventanas de contexto es crucial para controlar los gastos y mantener al mismo tiempo la calidad de los resultados. Las ventanas de contexto más grandes permiten una comprensión más exhaustiva, pero tienen un coste más elevado debido al mayor uso de tokens por consulta y a los mayores requisitos computacionales.
Para optimizar el uso de la ventana contextual, considere la posibilidad de aplicar un dimensionamiento dinámico del contexto basado en la complejidad de la tarea. Utilice técnicas de resumen para condensar la información relevante y enfoques de ventanas deslizantes para documentos o conversaciones largos. Estos métodos pueden ayudarle a encontrar el punto óptimo entre comprensión y rentabilidad.
Analice periódicamente la relación entre el tamaño del contexto y la calidad del resultado para afinar su enfoque. Ajuste las ventanas de contexto en función de los requisitos específicos de la tarea y considere la posibilidad de aplicar un enfoque escalonado, utilizando contextos más grandes sólo cuando sea necesario. Si gestiona cuidadosamente sus ventanas de contexto, podrá reducir significativamente el uso de tokens y los costes asociados sin sacrificar la calidad de los resultados de su LLM.
Estrategia 7: Implantar sistemas multiagente
Los sistemas multiagente ofrecen un potente enfoque para mejorar la eficiencia y la rentabilidad de las aplicaciones LLM. Al distribuir las tareas entre agentes especializados, las empresas pueden optimizar la asignación de recursos y reducir los costes generales del LLM.
Las arquitecturas LLM multiagente implican múltiples Agentes de IA trabajar en colaboración para resolver problemas complejos. Este enfoque puede incluir agentes especializados para diferentes aspectos de una tarea, estructuras jerárquicas con agentes supervisores y trabajadores, o resolución de problemas en colaboración entre múltiples LLM. Al implantar estos sistemas, las organizaciones pueden reducir su dependencia de modelos caros y a gran escala para cada tarea.
Las ventajas económicas de la gestión distribuida de tareas son significativas. Los sistemas multiagente permiten:
Asignación optimizada de recursos en función de la complejidad de las tareas
Mejora de la eficacia general del sistema y de los tiempos de respuesta
Reducción del uso de fichas mediante la implantación de modelos específicos
Sin embargo, para mantener la rentabilidad en los sistemas multiagente, es crucial implantar mecanismos de depuración robustos. Esto incluye el registro y la supervisión de las comunicaciones entre agentes, el análisis de los patrones de uso de tokens para identificar intercambios redundantes y la optimización de la división del trabajo entre agentes para minimizar el consumo innecesario de tokens.
Estrategia 8: Utilizar herramientas de formato de salida
Un formato de salida adecuado es un factor clave en la gestión de costes de LLM. Al garantizar un uso eficiente de los tokens y minimizar la necesidad de procesamiento adicional, las empresas pueden reducir significativamente sus costes operativos.
Estas herramientas ofrecen potentes capacidades para forzar las salidas de las funciones, lo que permite a los desarrolladores especificar formatos exactos para las respuestas LLM. Este enfoque reduce la variabilidad de los resultados y minimiza el desperdicio de fichas al garantizar que el modelo genera sólo la información necesaria.
La reducción de la variabilidad en los resultados de LLM tiene un impacto directo en los costes asociados. Las respuestas coherentes y bien estructuradas disminuyen la probabilidad de que los resultados estén mal formados o sean inutilizables, lo que a su vez reduce la necesidad de realizar llamadas adicionales a la API para aclarar o reformatear la información.
La implementación de salidas JSON puede resultar especialmente eficaz en términos de eficiencia. JSON ofrece una representación compacta de datos estructurados, fácil análisis sintáctico e integración con varios sistemas, y un uso reducido de tokens en comparación con las respuestas en lenguaje natural. Aprovechando estas herramientas de formato de salida, las empresas pueden agilizar sus flujos de trabajo LLM y optimizar el uso de tokens.
Estrategia 9: Integrar herramientas ajenas al MLP
Aunque los LLM son potentes, no siempre son la solución más rentable para todas las tareas. La integración deHerramientas LLM en sus flujos de trabajo puede reducir significativamente los costes operativos, manteniendo al mismo tiempo unos resultados de alta calidad.
La incorporación de scripts de Python para gestionar tareas específicas que no requieren todas las capacidades de un LLM puede suponer un importante ahorro de costes. Por ejemplo, el procesamiento de datos sencillos o la toma de decisiones basada en reglas a menudo pueden gestionarse de forma más eficiente mediante enfoques de programación tradicionales.
A la hora de equilibrar el LLM y las herramientas tradicionales en los flujos de trabajo, hay que tener en cuenta la complejidad de la tarea, la precisión requerida y el posible ahorro de costes. Un enfoque híbrido que aproveche los puntos fuertes tanto de los LLM como de las herramientas convencionales suele dar los mejores resultados en términos de rendimiento y rentabilidad.
Es crucial realizar un análisis exhaustivo de costes y beneficios de los enfoques híbridos. Este análisis debe tener en cuenta factores como:
Costes de desarrollo y mantenimiento de herramientas personalizadas
Tiempo de procesamiento y recursos necesarios
Precisión y fiabilidad de los resultados
Escalabilidad y flexibilidad a largo plazo
Estrategia 10: Auditoría y optimización periódicas
Establecer técnicas de gestión de costes de LLM es un proceso continuo que requiere una vigilancia y optimización constantes. La auditoría periódica del uso y los costes de su LLM es crucial para identificar ineficiencias y aplicar mejoras para el control de costes.
Nunca se insistirá lo suficiente en la importancia de la gestión y reducción continuas de los costes. A medida que sus aplicaciones LLM evolucionen y se amplíen, surgirán nuevos retos y oportunidades de optimización. Si supervisa y analiza constantemente el uso de su LLM, podrá anticiparse a posibles sobrecostes y asegurarse de que sus inversiones en IA ofrecen el máximo valor.
Para identificar los tokens desperdiciados, aplique herramientas sólidas de seguimiento y análisis. Busque patrones de consultas redundantes, ventanas de contexto excesivas o diseños ineficientes de los avisos. Utilice estos datos para perfeccionar sus estrategias de LLM y eliminar el consumo innecesario de tokens.
Por último, fomentar una cultura de conciencia de costes dentro de su organización es clave para el éxito a largo plazo en la gestión eficiente de recursos LLM. Anime a los equipos a considerar las implicaciones de coste de su uso del LLM y a buscar activamente oportunidades de optimización y control de gastos. Al hacer de la rentabilidad una responsabilidad compartida, puede asegurarse de que su empresa aprovecha todas las ventajas de la tecnología LLM al tiempo que mantiene los gastos bajo control.
Lo esencial
A medida que los grandes modelos lingüísticos siguen influyendo en las aplicaciones empresariales de IA, el dominio de la gestión de costes de los LLM se convierte en un factor crucial para el éxito a largo plazo. Mediante la implementación de las diez estrategias descritas en este artículo, desde la selección inteligente de modelos hasta la auditoría y optimización periódicas, su organización puede reducir significativamente los costes de los LLM y, al mismo tiempo, mantener o incluso mejorar el rendimiento. Recuerde que la gestión eficaz de los costes es un proceso continuo que requiere supervisión, análisis y adaptación constantes. Fomentando una cultura de conciencia de costes y aprovechando las herramientas y técnicas adecuadas, puede aprovechar todo el potencial de los LLM y mantener los costes operativos bajo control, garantizando que sus inversiones en IA aporten el máximo valor a su empresa.
No dude en ponerse en contacto con nosotros para obtener más información sobre la gestión de costes del LLM.


