
Wir müssen die Gedankenkette (CoT) überdenken, die AI&YOU #68 auslöst



Statistik der Woche: Die Nullschuss-CoT-Leistung betrug nur 5,55% für GPT-4-Turbo, 8,51% für Claude-3-Opus und 4,44% für GPT-4. ("Chain of Thoughtlessness?" Papier)
Chain-of-Thought (CoT) Prompting wurde als Durchbruch bei der Erschließung der logischen Fähigkeiten von großen Sprachmodellen (LLMs) gepriesen. Jüngste Forschungsergebnisse haben diese Behauptungen jedoch in Frage gestellt und uns dazu veranlasst, die Technik zu überdenken.
In der diesjährigen Ausgabe von AI&YOU befassen wir uns mit den Erkenntnissen aus drei Blogs, die wir zu diesem Thema veröffentlicht haben:
Wir müssen die Gedankenkette (CoT) überdenken, die AI&YOU #68 auslöst
LLMs zeigen bemerkenswerte Fähigkeiten bei der Verarbeitung und Erzeugung natürlicher Sprache (NLP). Wenn sie jedoch mit komplexen Denkaufgaben konfrontiert werden, können diese Modelle Schwierigkeiten haben, genaue und zuverlässige Ergebnisse zu erzielen. Hier kommt das Chain-of-Thought (CoT) Prompting ins Spiel, eine Technik, die darauf abzielt, die Problemlösungsfähigkeiten von LLMs zu verbessern.
Eine fortgeschrittene schnelles Engineering Technik ist darauf ausgelegt, LLMs durch einen schrittweisen Denkprozess zu führen. Im Gegensatz zu Standard-Prompting-Methoden, die auf direkte Antworten abzielen, ermutigt das CoT-Prompting das Modell, zwischenzeitliche Argumentationsschritte zu generieren, bevor es zu einer endgültigen Antwort kommt.
Im Kern geht es bei der CoT-Eingabeaufforderung darum, die Eingabeaufforderungen so zu strukturieren, dass sie dem Modell eine logische Abfolge von Gedanken entlocken. Durch die Zerlegung komplexer Probleme in kleinere, überschaubare Schritte versucht CoT, LLMs in die Lage zu versetzen, effektiver durch komplizierte Argumentationspfade zu navigieren.
Wie CoT funktioniert
Im Kern führt das CoT-Prompting Sprachmodelle durch eine Reihe von Zwischenschritten, bevor sie zu einer endgültigen Antwort gelangen. Dieser Prozess umfasst in der Regel folgende Schritte:
Problem-Zerlegung: Die komplexe Aufgabe wird in kleinere, überschaubare Schritte aufgeteilt.
Schritt-für-Schritt-Reasoning: Das Modell wird dazu aufgefordert, jeden Schritt explizit zu durchdenken.
Logische Progression: Jeder Schritt baut auf dem vorherigen auf und bildet eine Gedankenkette.
Fazit Zeichnung: Die endgültige Antwort ergibt sich aus den kumulierten Argumentationsschritten.
Arten von CoT Prompting
Das Prompting der Gedankenkette kann auf verschiedene Weise umgesetzt werden, wobei zwei Haupttypen hervorstechen:
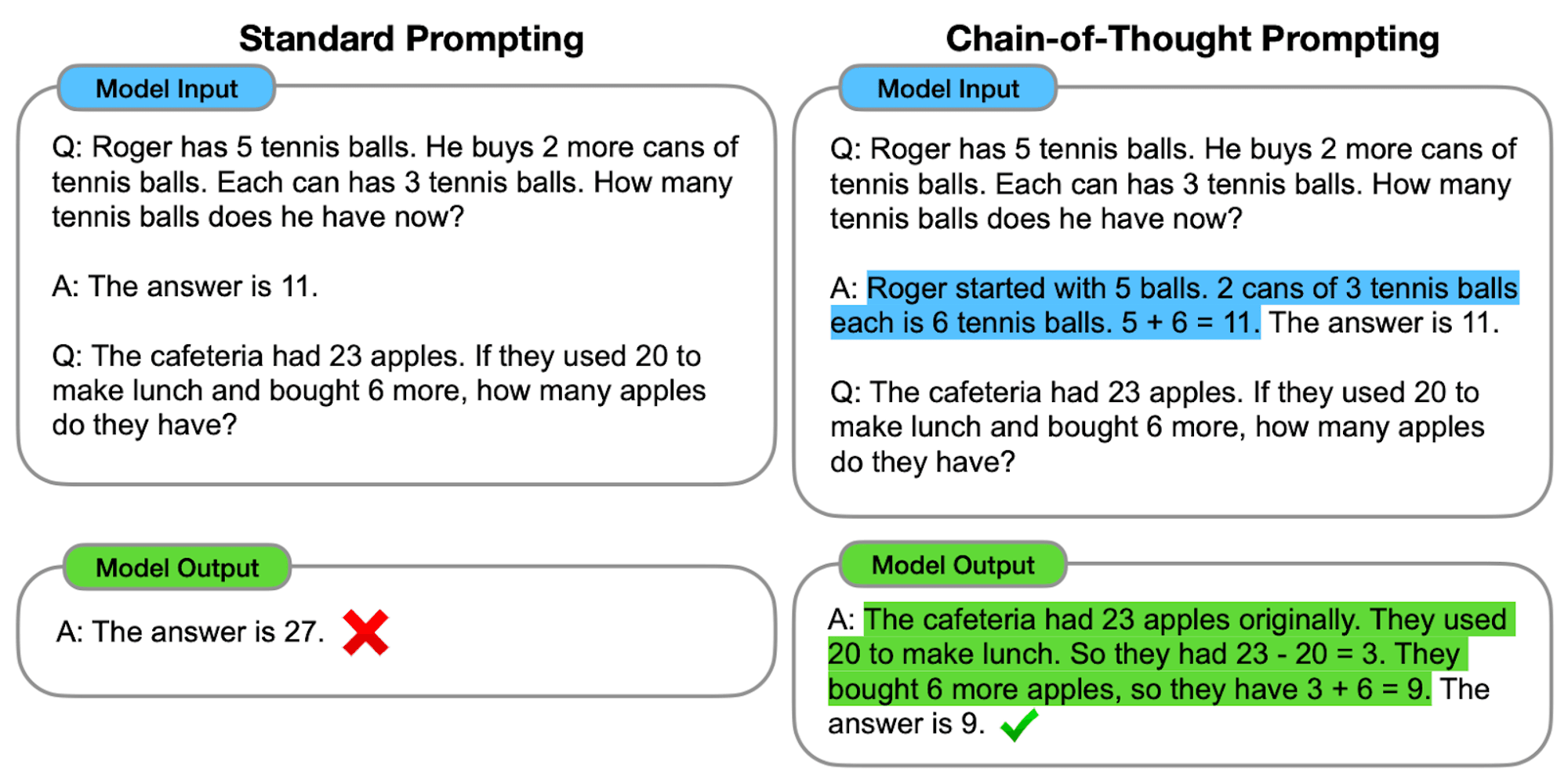
Null-Schuss CoT: Die Zero-Shot CoT erfordert keine aufgabenspezifischen Beispiele. Stattdessen wird eine einfache Aufforderung wie "Gehen wir das Schritt für Schritt an" verwendet, um das Modell zu ermutigen, seinen Denkprozess aufzuschlüsseln. ****
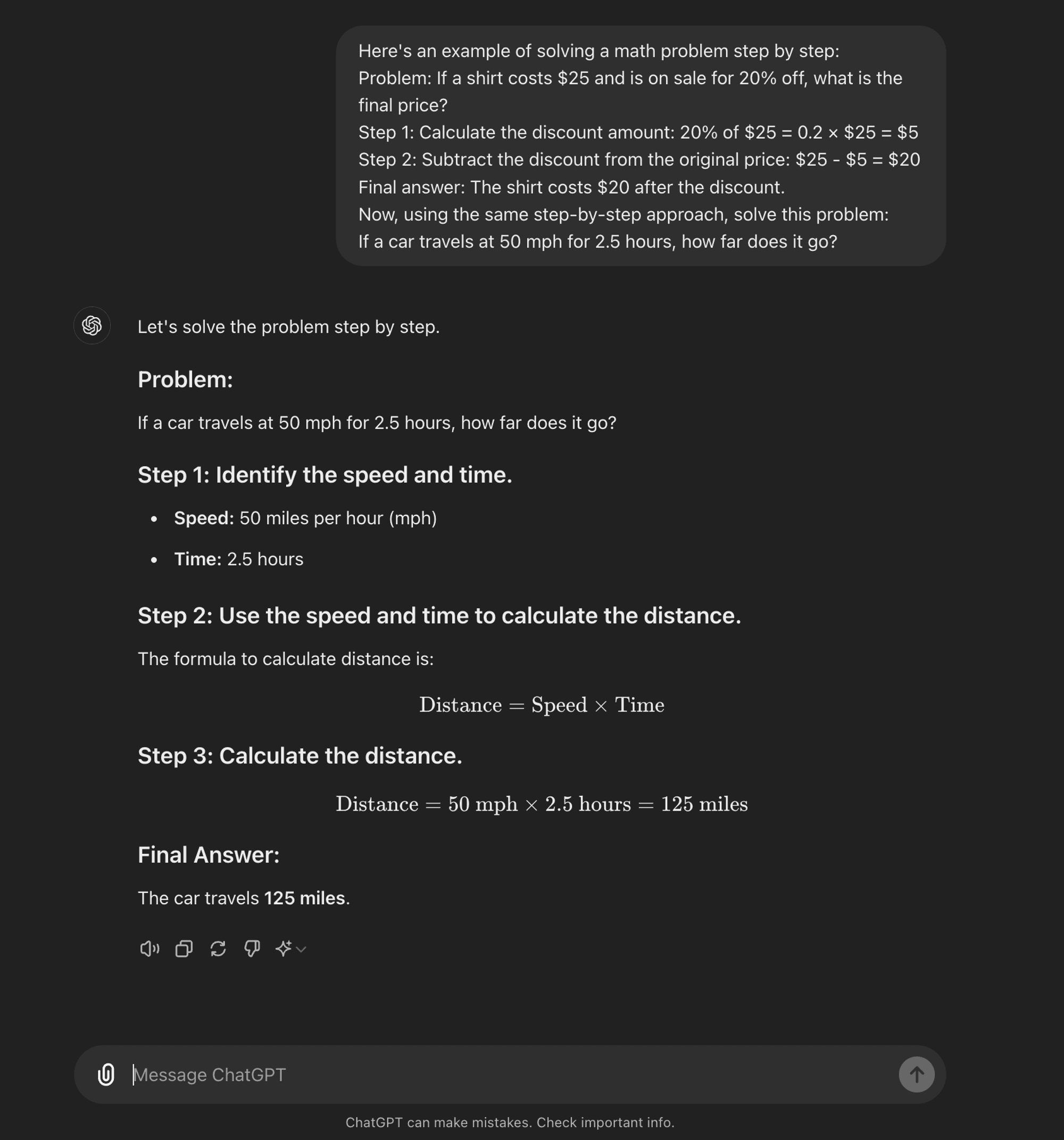
Wenige Schüsse CoT: Beim Few-shot CoT wird dem Modell eine kleine Anzahl von Beispielen zur Verfügung gestellt, die den gewünschten Denkprozess veranschaulichen. Diese Beispiele dienen als Vorlage für das Modell, wenn es neue, unbekannte Probleme angeht.
Null-Schuss CoT
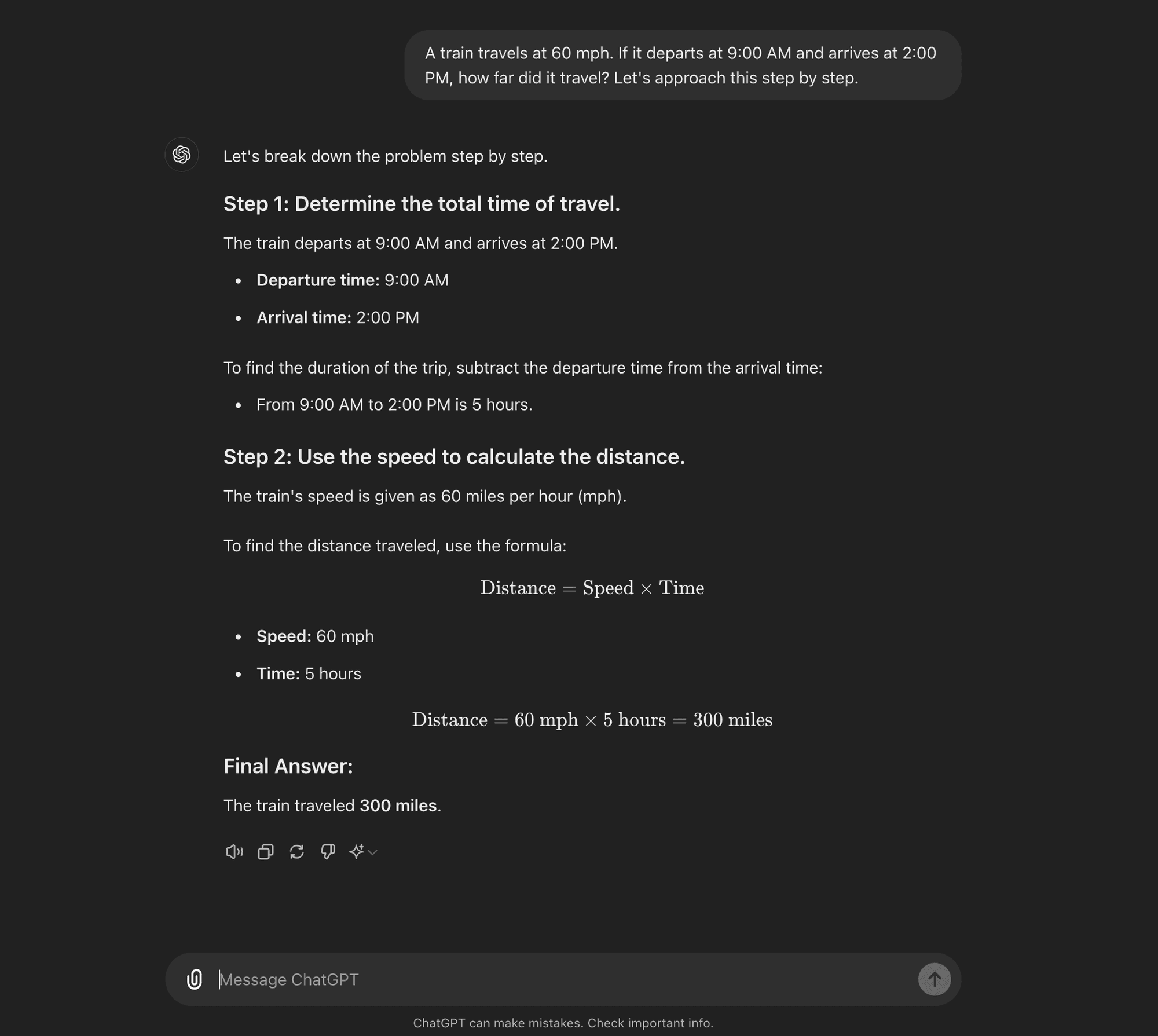
Wenige Schüsse CoT
AI Research Paper Breakdown: "Kette der Gedankenlosigkeit?"
Da Sie nun wissen, was CoT-Prompting ist, können wir uns mit einigen neueren Forschungsergebnissen befassen, die einige seiner Vorteile in Frage stellen und einen Einblick geben, wann es tatsächlich nützlich ist.
Das Forschungspapier mit dem Titel "Kette der Rücksichtslosigkeit? Eine Analyse der CoT in der Planung," bietet eine kritische Untersuchung der Effektivität und Verallgemeinerbarkeit von CoT-Prompting. Für KI-Praktiker ist es von entscheidender Bedeutung, diese Ergebnisse und ihre Auswirkungen auf die Entwicklung von KI-Anwendungen zu verstehen, die ausgefeilte Argumentationsfähigkeiten erfordern.

Die Forscher wählten eine klassische Planungsdomäne namens Blocksworld als primäres Testfeld. In Blocksworld besteht die Aufgabe darin, eine Reihe von Blöcken von einer Ausgangskonfiguration zu einer Zielkonfiguration umzuordnen, indem eine Reihe von Bewegungsaktionen durchgeführt wird. Diese Domäne eignet sich ideal zum Testen von Denk- und Planungsfähigkeiten, denn:
Es ermöglicht die Generierung von Problemen mit unterschiedlicher Komplexität
Sie hat klare, algorithmisch überprüfbare Lösungen
Es ist unwahrscheinlich, dass sie in den LLM-Trainingsdaten stark vertreten ist.
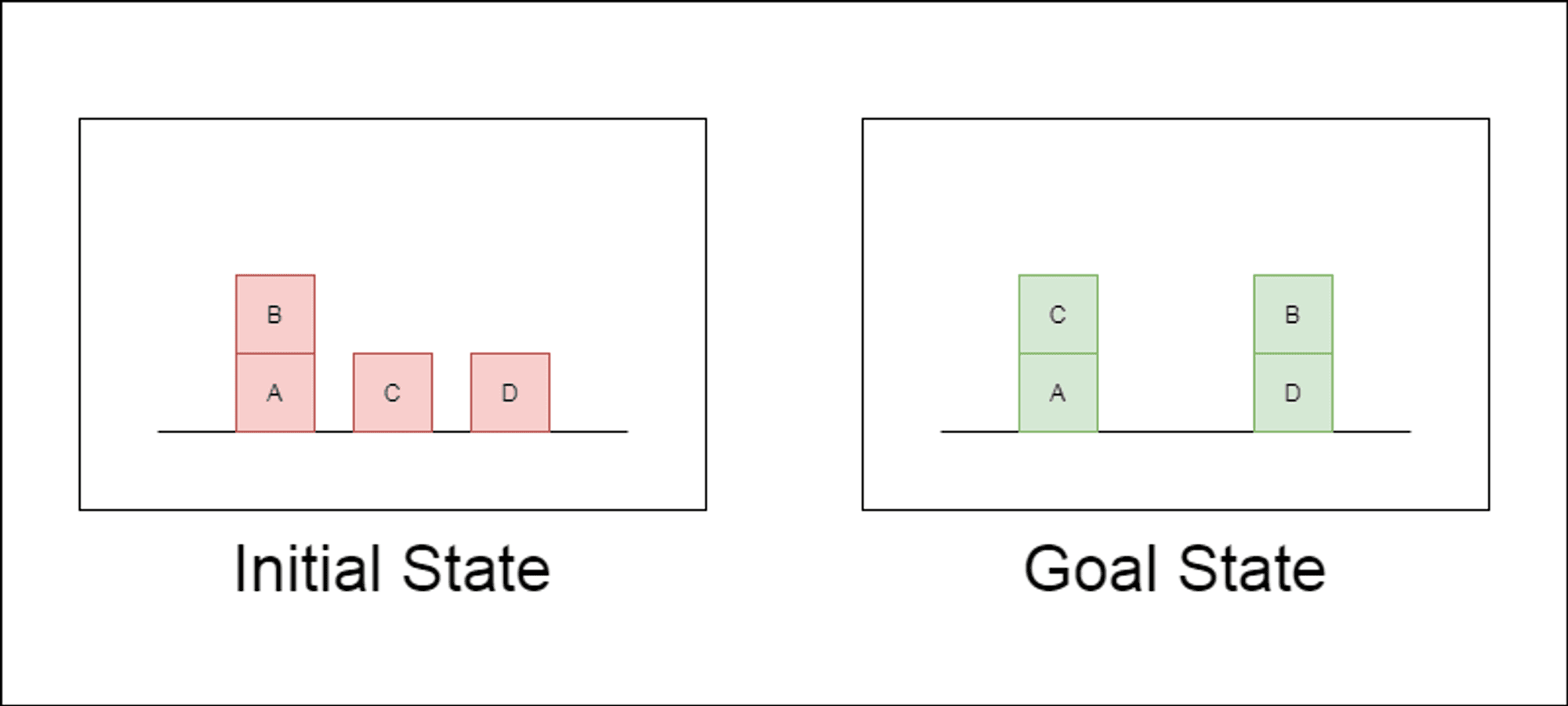
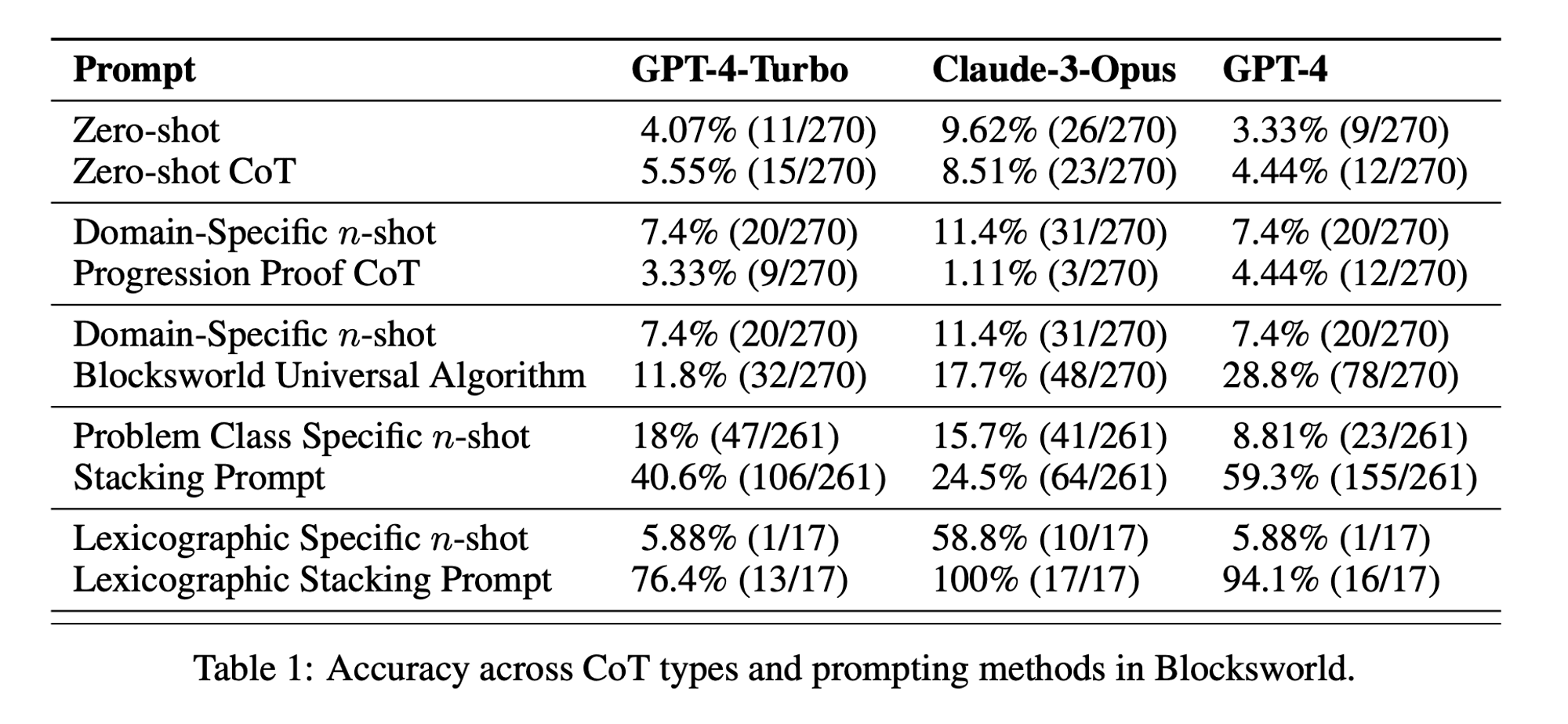
In der Studie wurden drei moderne LLMs untersucht: GPT-4, Claude-3-Opus und GPT-4-Turbo. Diese Modelle wurden mit Aufforderungen unterschiedlicher Spezifität getestet:
Null-Schuss Gedankenkette (Universal): Es genügt, der Aufforderung "Denken wir Schritt für Schritt" hinzuzufügen.
Fortschrittsnachweis (speziell für PDDL): Eine allgemeine Erläuterung der Korrektheit von Plänen mit Beispielen.
Blocksworld Universal Algorithmus: Demonstration eines allgemeinen Algorithmus zur Lösung beliebiger Blocksworld-Probleme.
Aufforderung zum Stapeln: Konzentration auf eine bestimmte Unterklasse von Blocksworld-Problemen (Tisch-zu-Stapel).
Lexikografische Stapelung: Weitere Eingrenzung auf eine bestimmte syntaktische Form des Zielzustandes.
Durch das Testen dieser Aufforderungen an immer komplexeren Problemen wollten die Forscher herausfinden, wie gut LLMs das in den Beispielen demonstrierte Denken verallgemeinern können.
Wesentliche Ergebnisse enthüllt
Die Ergebnisse dieser Studie stellen viele der vorherrschenden Annahmen über CoT-Prompting in Frage:
Begrenzte Wirksamkeit des CoT: Entgegen früherer Behauptungen zeigte das CoT-Prompting nur dann signifikante Leistungsverbesserungen, wenn die bereitgestellten Beispiele dem Abfrageproblem extrem ähnlich waren. Sobald die Probleme vom exakten Format der Beispiele abwichen, sank die Leistung drastisch.
Rasche Verschlechterung der Leistung: Mit zunehmender Komplexität der Probleme (gemessen an der Anzahl der beteiligten Blöcke) nahm die Genauigkeit aller Modelle drastisch ab, unabhängig von der verwendeten CoT-Aufforderung. Dies deutet darauf hin, dass LLMs Schwierigkeiten haben, das in einfachen Beispielen gezeigte logische Denken auf komplexere Szenarien zu übertragen.
Unwirksamkeit von allgemeinen Aufforderungen: Überraschenderweise schnitten allgemeinere CoT-Aufforderungen oft schlechter ab als Standardaufforderungen ohne Argumentationsbeispiele. Dies widerspricht der Vorstellung, dass CoT LLMs hilft, verallgemeinerbare Problemlösungsstrategien zu lernen.
Kompromiss bei der Spezifität: Die Studie ergab, dass mit hochspezifischen Aufforderungen eine hohe Genauigkeit erreicht werden kann, allerdings nur bei einer sehr kleinen Teilmenge von Problemen. Dies zeigt, dass es einen starken Kompromiss zwischen Leistungssteigerung und Anwendbarkeit der Aufforderung gibt.
Fehlen eines echten algorithmischen Lernens: Die Ergebnisse deuten stark darauf hin, dass LLMs nicht lernen, allgemeine algorithmische Verfahren aus den CoT-Beispielen anzuwenden. Stattdessen scheinen sie sich auf Mustervergleiche zu verlassen, die bei neuartigen oder komplexeren Problemen schnell versagen.
Diese Ergebnisse haben erhebliche Auswirkungen für KI-Praktiker und Unternehmen, die CoT-Prompting in ihren Anwendungen nutzen wollen. Sie deuten darauf hin, dass CoT zwar die Leistung in bestimmten engen Szenarien steigern kann, aber möglicherweise nicht das Allheilmittel für komplexe Denkaufgaben ist, auf das viele gehofft hatten.
Auswirkungen auf die KI-Entwicklung
Die Ergebnisse dieser Studie haben erhebliche Auswirkungen auf die KI-Entwicklung, insbesondere für Unternehmen, die an Anwendungen arbeiten, die komplexe Denk- oder Planungsfunktionen erfordern:
Neubewertung der CoT-Wirksamkeit: KI-Entwickler sollten vorsichtig sein, wenn es darum geht, sich bei Aufgaben, die echtes algorithmisches Denken oder die Verallgemeinerung auf neue Szenarien erfordern, auf CoT zu verlassen.
Beschränkungen der derzeitigen LLMs: Für Anwendungen, die eine solide Planung oder eine mehrstufige Problemlösung erfordern, können alternative Ansätze erforderlich sein.
Die Kosten einer prompten Entwicklung: Während hochspezifische CoT-Prompts gute Ergebnisse für enge Problemgruppen liefern können, kann der menschliche Aufwand, der für die Erstellung dieser Prompts erforderlich ist, die Vorteile überwiegen, insbesondere angesichts ihrer begrenzten Verallgemeinerbarkeit.
Bewertungsmetriken überdenken: Wenn man sich ausschließlich auf statische Testsätze verlässt, kann die tatsächliche Denkfähigkeit eines Modells überschätzt werden.
Die Kluft zwischen Wahrnehmung und Realität: Es besteht eine erhebliche Diskrepanz zwischen den wahrgenommenen Argumentationsfähigkeiten von LLMs (die im populären Diskurs oft anthropomorphisiert werden) und ihren tatsächlichen Fähigkeiten, wie in dieser Studie gezeigt wurde.
Empfehlungen für AI-Praktiker:
Bewertung: Implementierung verschiedener Testverfahren, um die tatsächliche Generalisierung über verschiedene Problemkomplexe hinweg zu bewerten.
CoT-Verwendung: Wenden Sie die Gedankenkette mit Bedacht an und erkennen Sie ihre Grenzen bei der Verallgemeinerung.
Hybride Lösungen: Erwägen Sie die Kombination von LLMs mit traditionellen Algorithmen für komplexe Schlussfolgerungsaufgaben.
Transparenz: Die Grenzen des KI-Systems sollten klar kommuniziert werden, insbesondere bei Denk- und Planungsaufgaben.
Schwerpunkt F&E: Investitionen in die Forschung zur Verbesserung der echten Denkfähigkeiten von KI-Systemen.
Feinabstimmung: Ziehen Sie eine bereichsspezifische Feinabstimmung in Betracht, aber seien Sie sich der möglichen Grenzen der Verallgemeinerbarkeit bewusst.
Für KI-Praktiker und Unternehmen zeigen diese Ergebnisse, wie wichtig es ist, LLM-Stärken mit spezialisierten Schlussfolgerungsansätzen zu kombinieren, bei Bedarf in domänenspezifische Lösungen zu investieren und die Grenzen von KI-Systemen transparent zu machen. In Zukunft muss sich die KI-Gemeinschaft auf die Entwicklung neuer Architekturen und Trainingsmethoden konzentrieren, die die Lücke zwischen Mustererkennung und echtem algorithmischen Denken schließen können.
Die 10 besten Prompting-Techniken für LLMs
In dieser Woche untersuchen wir zehn der leistungsfähigsten und gängigsten Prompting-Techniken und geben Einblicke in ihre Anwendungen und besten Praktiken.

Gut konzipierte Eingabeaufforderungen können die Leistung eines LLM erheblich verbessern und genauere, relevantere und kreativere Ergebnisse ermöglichen. Egal, ob Sie ein erfahrener KI-Entwickler sind oder gerade erst mit LLMs beginnen, diese Techniken werden Ihnen helfen, das volle Potenzial von KI-Modellen zu erschließen.
Schauen Sie sich den vollständigen Blog an, um mehr über jedes einzelne Produkt zu erfahren.
Danke, dass Sie sich die Zeit genommen haben, AI & YOU zu lesen!
Für noch mehr Inhalte zum Thema KI für Unternehmen, einschließlich Infografiken, Statistiken, Anleitungen, Artikeln und Videos, folgen Sie Skim AI auf LinkedIn
Sie sind Gründer, CEO, Risikokapitalgeber oder Investor und suchen KI-Beratung, fraktionierte KI-Entwicklung oder Due-Diligence-Dienstleistungen? Holen Sie sich die Beratung, die Sie brauchen, um fundierte Entscheidungen über die KI-Produktstrategie Ihres Unternehmens und Investitionsmöglichkeiten zu treffen.
Wir entwickeln maßgeschneiderte KI-Lösungen für von Venture Capital und Private Equity unterstützte Unternehmen in den folgenden Branchen: Medizintechnik, Nachrichten/Content-Aggregation, Film- und Fotoproduktion, Bildungstechnologie, Rechtstechnologie, Fintech und Kryptowährungen.


