
Wie man leistungsstarke LLM-Anwendungen mit Vektordatenbanken und RAG erstellt - AI&YOU#55



Statistik/Fakten der Woche: 30% der Unternehmen werden bis 2026 Vektordatenbanken als Grundlage für ihre generativen KI-Modelle verwenden, gegenüber 2% im Jahr 2023. (Gartner)
LLMs wie GPT-4, Claude und Llama 3 haben sich zu leistungsfähigen Werkzeugen für die Implementierung von NLP in Unternehmen entwickelt und zeigen bemerkenswerte Fähigkeiten beim Verstehen und Erzeugen von menschenähnlichem Text. Allerdings haben sie oft Probleme mit der Kontextsensitivität und Genauigkeit, vor allem wenn es um domänenspezifische Informationen geht.
Deshalb gehen wir in dieser Ausgabe von AI&YOU in drei Blogs der Frage nach, wie diese Herausforderungen bewältigt werden:
Kombination von Vektordatenbanken und RAG für leistungsstarke LLM-Anwendungen
Die 10 wichtigsten Vorteile der Verwendung einer Open-Source-Vektordatenbank
Kombination von Vektordatenbanken und RAG für leistungsstarke LLM-Anwendungen - AI&YOU #55
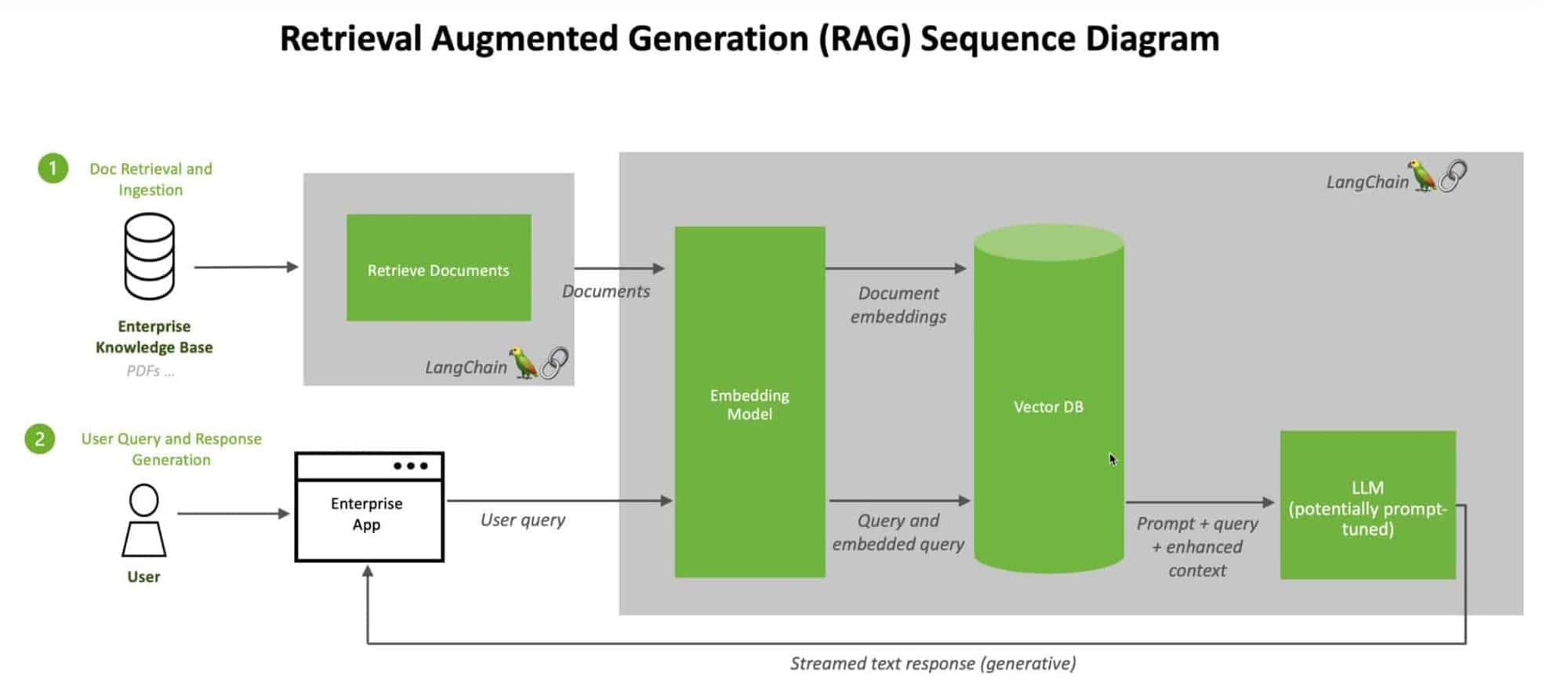
Um diese Herausforderungen zu bewältigen, haben sich Forscher und Entwickler innovativen Techniken wie Retrieval Augmented Generation (RAG) und Vektordatenbanken. RAG verbessert LLMs, indem es ihnen ermöglicht, auf relevante Informationen aus externen Wissensdatenbanken zuzugreifen und diese abzurufen, während Vektordatenbanken eine effiziente und skalierbare Lösung für die Speicherung und Abfrage hochdimensionaler Datendarstellungen bieten.
Die Synergie zwischen Vektordatenbanken und RAG
Vektordatenbanken und RAG bilden eine leistungsstarke Synergie, die die Möglichkeiten großer Sprachmodelle erweitert. Der Kern dieser Synergie liegt in der effizienten Speicherung und Abfrage von Wissensbasiseinbettungen. Vektordatenbanken sind für die Verarbeitung hochdimensionaler Vektordarstellungen von Daten ausgelegt. Sie ermöglichen eine schnelle und genaue Ähnlichkeitssuche, so dass LLMs schnell relevante Informationen aus umfangreichen Wissensdatenbanken abrufen können.
Durch die Integration von Vektordatenbanken mit RAG können wir eine nahtlose Pipeline zur Ergänzung von LLM-Antworten mit externem Wissen schaffen. Wenn ein LLM eine Anfrage erhält, kann RAG die Vektordatenbank effizient durchsuchen, um die relevantesten Informationen basierend auf der Einbettung der Anfrage zu finden. Diese abgerufenen Informationen werden dann zur Anreicherung des LLM-Kontextes verwendet, so dass er genauere und informativere Antworten in Echtzeit generieren kann.
Vorteile der Kombination von Vektordatenbanken und RAG
Die Kombination von Vektordatenbanken und RAG bietet mehrere bedeutende Vorteile für große Sprachmodellanwendungen:
Verbesserte Genauigkeit und weniger Halluzinationen
Einer der Hauptvorteile der Kombination von Vektordatenbanken und RAG ist die deutliche Verbesserung der Genauigkeit der LLM-Antworten. Indem RAG LLMs Zugang zu relevantem externem Wissen verschafft, hilft es, das Auftreten von "Halluzinationen" zu reduzieren - Fälle, in denen das Modell inkonsistente oder faktisch falsche Informationen generiert. Mit der Fähigkeit, domänenspezifische Informationen aus zuverlässigen Quellen abzurufen und einzubeziehen, können LLMs genauere und vertrauenswürdigere Ergebnisse produzieren.
Skalierbarkeit und Leistung
Vektordatenbanken sind so konzipiert, dass sie effizient skalieren und große Mengen an hochdimensionalen Daten verarbeiten können. Diese Skalierbarkeit ist entscheidend für den Umgang mit umfangreichen Wissensdatenbanken, die in Echtzeit durchsucht und abgerufen werden müssen. Durch die Nutzung der Leistungsfähigkeit von Vektordatenbanken kann RAG schnelle und effiziente Ähnlichkeitssuchen durchführen, die es LLMs ermöglichen, schnell Antworten zu generieren, ohne die Qualität der abgerufenen Informationen zu beeinträchtigen.
Ermöglichung domänenspezifischer Anwendungen
Die Kombination von Vektordatenbanken und RAG eröffnet neue Möglichkeiten für den Aufbau domänenspezifischer LLM-Anwendungen. Durch die Kuratierung von Wissensdatenbanken, die für verschiedene Bereiche spezifisch sind, können LLMs so zugeschnitten werden, dass sie genaue und relevante Informationen in diesen Kontexten liefern. Dies ermöglicht die Entwicklung von spezialisierten KI-Assistenten, Chatbots und Wissensmanagementsystemen, die auf die besonderen Bedürfnisse verschiedener Branchen und Anwendungsfälle eingehen können.

Implementierung von RAG mit Vektordatenbanken
Um die Vorteile der Kombination von Vektordatenbanken und RAG nutzen zu können, ist es wichtig, den Implementierungsprozess zu verstehen.
Im Folgenden werden die wichtigsten Schritte beim Aufbau eines RAG-Systems mit einer Vektordatenbank erläutert:
Indizierung und Speicherung von Wissensbasiseinbettungen: Der erste Schritt besteht darin, die Textdaten aus der Wissensbasis mit Hilfe von Einbettungsmodellen wie BERT in hochdimensionale Vektoren umzuwandeln und diese Einbettungen dann zu indizieren und in der Vektordatenbank zu speichern, um eine effiziente Ähnlichkeitssuche und -abfrage zu ermöglichen.
Abfrage der Vektordatenbank nach relevanten Informationen: Wenn ein LLM eine Anfrage erhält, wandelt das RAG-System die Anfrage in eine Vektordarstellung um, indem es dasselbe Einbettungsmodell verwendet, und die Vektordatenbank führt eine Ähnlichkeitssuche durch, um die relevantesten Einbettungen der Wissensbasis auf der Grundlage einer gewählten Ähnlichkeitsmetrik zu finden.
Integration von abgerufenen Informationen in LLM-Antworten: Die relevanten Informationen, die aus der Vektordatenbank abgerufen werden, werden in den Antwortgenerierungsprozess des LLM integriert, entweder durch Verkettung mit der ursprünglichen Anfrage oder durch Techniken wie Aufmerksamkeitsmechanismen, die es dem LLM ermöglichen, genauere und informativere Antworten auf der Grundlage des erweiterten Kontexts zu generieren.
Auswahl der richtigen Vektordatenbank für Ihre Anwendung: Die Auswahl der geeigneten Vektordatenbank ist von entscheidender Bedeutung, wobei Faktoren wie Skalierbarkeit, Leistung, Benutzerfreundlichkeit und Kompatibilität mit Ihrem vorhandenen Technologie-Stack sowie Ihre spezifischen Anforderungen wie die Größe der Wissensdatenbank, das Abfragevolumen und die gewünschte Antwortlatenz berücksichtigt werden müssen.
Bewährte Praktiken und Überlegungen
Um den Erfolg Ihrer RAG-Implementierung mit Vektordatenbanken zu gewährleisten, sind einige bewährte Verfahren und Überlegungen zu beachten.
Optimierung der Einbettung von Wissensdatenbanken für das Retrieval:
Die Qualität der Einbettungen der Wissensbasis ist von entscheidender Bedeutung und erfordert das Experimentieren mit verschiedenen Einbettungsmodellen und -techniken, die Feinabstimmung mit domänenspezifischen Daten und die regelmäßige Aktualisierung und Erweiterung der Einbettungen, wenn neue Informationen verfügbar werden, um Relevanz und Genauigkeit zu erhalten.
Gleichgewicht zwischen Abrufgeschwindigkeit und Genauigkeit:
Es gibt einen Kompromiss zwischen Abrufgeschwindigkeit und Genauigkeit, der Techniken wie die ungefähre Suche nach dem nächsten Nachbarn erforderlich macht, um den Abruf zu beschleunigen und gleichzeitig eine akzeptable Genauigkeit beizubehalten.
Gewährleistung von Datensicherheit und Datenschutz:
Die Einrichtung einer sicheren Datenspeicherung, Zugriffskontrollen und Verschlüsselungstechniken wie die homomorphe Verschlüsselung sind unerlässlich, um unbefugten Zugriff zu verhindern und sensible Daten in den Wissensdatenbank-Embeddings zu schützen, während gleichzeitig die einschlägigen Datenschutzbestimmungen eingehalten werden.
Überwachung und Wartung des Systems:
Die kontinuierliche Überwachung von Metriken wie Abfragelatenz, Abrufgenauigkeit und Ressourcennutzung, die Implementierung automatischer Überwachungs- und Warnmechanismen und die Erstellung eines robusten Wartungsplans, einschließlich Backups, Updates und Leistungsoptimierung, sind entscheidend für die Gewährleistung der langfristigen Leistung und Zuverlässigkeit des RAG-Systems.
Nutzen Sie die Leistungsfähigkeit von Vektordatenbanken und RAG in Ihrem Unternehmen
Da KI unsere Zukunft prägt, ist es für Ihr Unternehmen von entscheidender Bedeutung, bei diesen technologischen Fortschritten an der Spitze zu stehen. Durch die Erforschung und Implementierung modernster Techniken wie Vektordatenbanken und RAG können Sie das Potenzial großer Sprachmodelle voll ausschöpfen und KI-Systeme schaffen, die intelligenter und anpassungsfähiger sind und einen höheren ROI bieten.
Die 10 wichtigsten Vorteile der Verwendung einer Open-Source-Vektordatenbank
Unter den Vektordatenbanklösungen bieten Open-Source-Vektordatenbanken eine überzeugende Kombination aus Flexibilität, Skalierbarkeit und Kosteneffizienz. Durch die Nutzung der kollektiven Kraft der Open-Source-Gemeinschaft definieren diese spezialisierten Vektordatenbanken die Art und Weise, wie Unternehmen an die Datenverwaltung und -analyse herangehen, neu.
In dieser Woche haben wir in unserem Blog auch die 10 wichtigsten Vorteile einer Open-Source-Vektordatenbank vorgestellt:
Skalierbarkeit und Kosteneffizienz ermöglichen ein nahtloses Wachstum ohne hohe Kosten, wodurch die Bindung an einen bestimmten Anbieter vermieden und eine budgetfreundliche Lösung bereitgestellt wird.
🔸 Flexibilität und Anpassungsfähigkeit ermöglichen die Anpassung der Datenbank an spezifische Bedürfnisse, die Änderung von Funktionen und die Integration mit bestehenden Systemen.
🔸 Der effiziente Umgang mit unstrukturierten Daten nutzt Techniken wie NLP und Vektoreinbettungen für eine effektive Speicherung, Suche und Analyse.
Die leistungsstarke vektorielle Ähnlichkeitssuche erleichtert die genaue Suche auf der Grundlage semantischer Ähnlichkeit und ermöglicht so Anwendungen wie personalisierte Empfehlungen und intelligente Inhaltssuche.
Die Integration in Open-Source-Ökosysteme gewährleistet die Interoperabilität mit ergänzenden Tools und Frameworks, wodurch die Produktivität gesteigert und die Zusammenarbeit gefördert wird.
Robuste Sicherheits- und Datenschutzmaßnahmen legen den Schwerpunkt auf Transparenz, Verschlüsselung, Zugangskontrolle und die Einhaltung von Compliance-Standards.
🔸 Hohe Leistung und effizientes Datenmanagement sorgen für blitzschnelle Abfrageausführung und Vielseitigkeit bei unterschiedlichen Workloads.
Die Kompatibilität mit fortschrittlicher Analytik und maschinellem Lernen ermöglicht die nahtlose Integration mit modernsten Techniken und Frameworks.
Die zukunftssichere und skalierbare Architektur ermöglicht ein nahtloses Wachstum und die Anpassung an neue Technologien und sich verändernde Datenanforderungen.
Community-gesteuerte Innovation und Unterstützung fördern die kontinuierliche Verbesserung, den Wissensaustausch und unschätzbare Ressourcen für die Nutzung dieser leistungsstarken Werkzeuge.
Die 5 besten Vektordatenbanken für Ihr Unternehmen
Neben den wichtigsten Vorteilen haben wir diese Woche auch einen Blog über die 5 besten Vektordatenbanken für Ihr Unternehmen veröffentlicht:
1. Chroma
Chroma wurde für die nahtlose Integration mit Modellen und Frameworks für maschinelles Lernen entwickelt und vereinfacht die Entwicklung von KI-gestützten Anwendungen. Es bietet effiziente Vektorspeicherung, Abruf, Ähnlichkeitssuche, Echtzeit-Indizierung und Metadatenspeicherung. Sie unterstützt verschiedene Abstandsmetriken und Indizierungsalgorithmen für optimale Leistung in Anwendungsfällen wie semantische Suche, Empfehlungen und Anomalieerkennung.

2. Kiefernzapfen
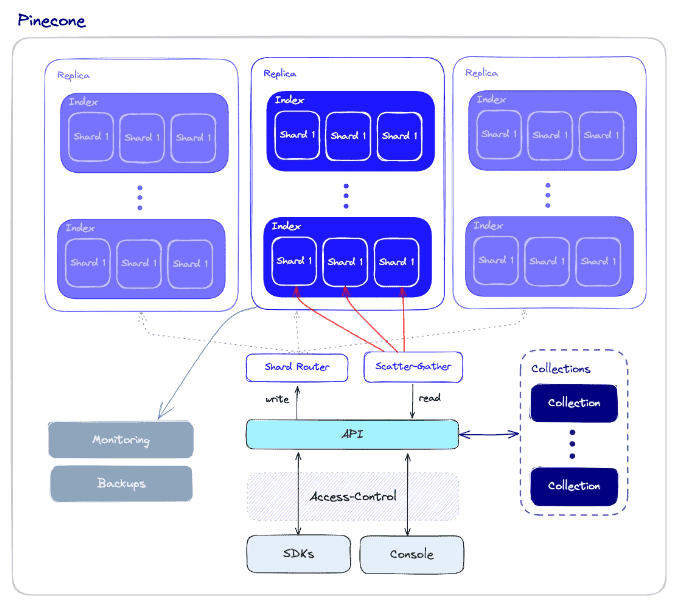
Pinecone ist eine vollständig verwaltete, serverlose Vektordatenbank, bei der hohe Leistung und Benutzerfreundlichkeit im Vordergrund stehen. Sie kombiniert fortschrittliche Vektorsuchalgorithmen mit Filterung und verteilter Infrastruktur für eine schnelle, zuverlässige Vektorsuche im großen Maßstab. Pinecone lässt sich nahtlos mit Frameworks für maschinelles Lernen und Datenquellen für Anwendungen wie semantische Suche, Empfehlungen, Anomalieerkennung und Fragenbeantwortung integrieren.
3. Qdrant
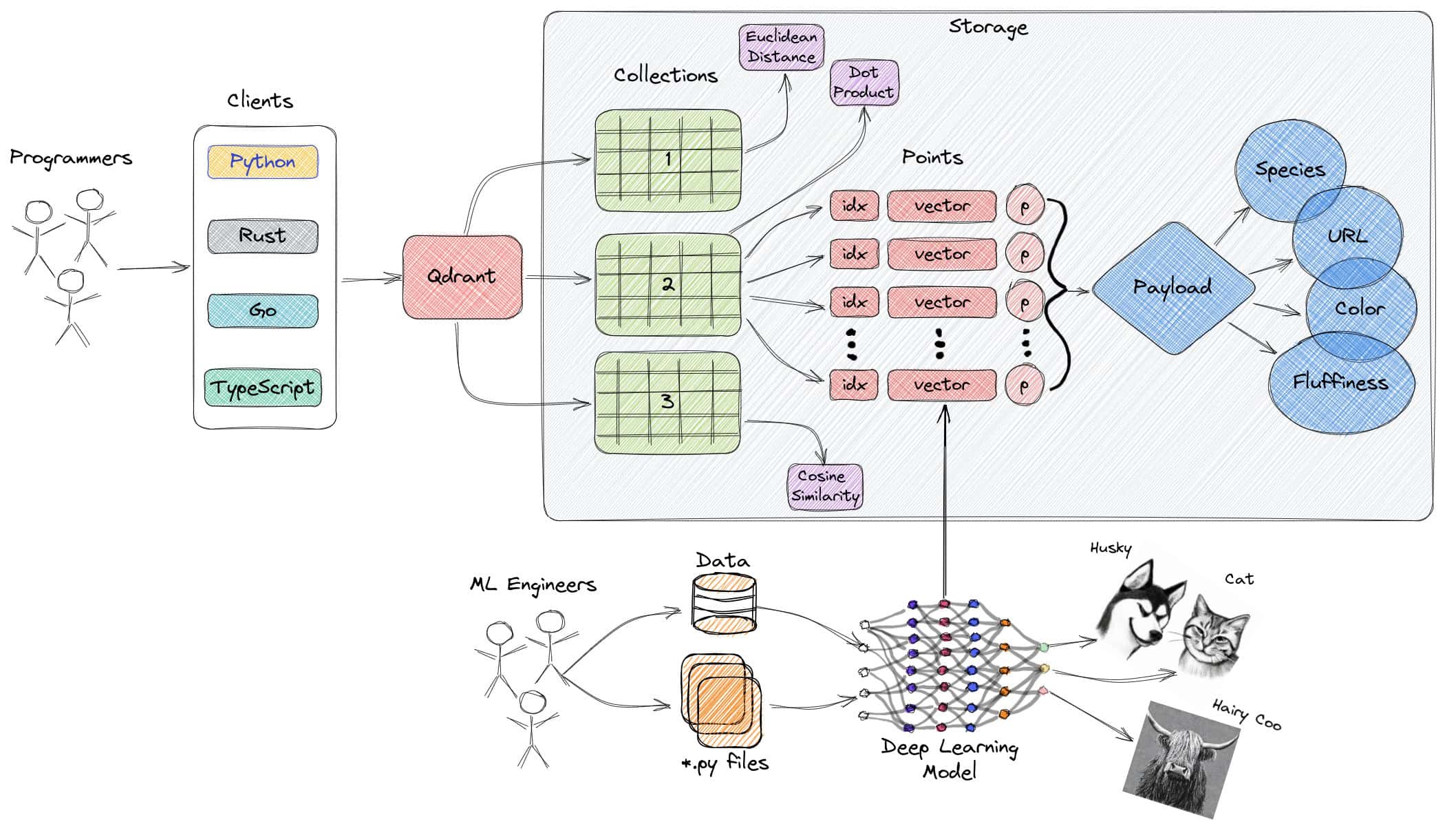
Qdrant ist eine in Rust geschriebene quelloffene, schnelle und skalierbare Suchmaschine für Vektorähnlichkeit. Sie bietet eine bequeme API zum Speichern, Suchen und Verwalten von Vektoren mit Metadaten und ermöglicht so produktionsreife Anwendungen zum Abgleichen, Suchen, Empfehlen und mehr. Zu den Funktionen gehören Echtzeit-Updates, erweiterte Filterung, verteilte Indizes und Cloud-native Bereitstellungsoptionen.
4. Weaviate
Weaviate ist eine Open-Source-Vektordatenbank, bei der Geschwindigkeit, Skalierbarkeit und Benutzerfreundlichkeit im Vordergrund stehen. Sie ermöglicht die Speicherung von Objekten und Vektoren und kombiniert Vektorsuche mit strukturierter Filterung. Sie bietet eine GraphQL-basierte API, CRUD-Operationen, horizontale Skalierung und Cloud-native Bereitstellung. Enthält Module für NLP-Aufgaben, automatische Schemakonfiguration und benutzerdefinierte Vektorisierung.
5. Milvus
Milvus ist eine Open-Source-Vektordatenbank, die für die Verwaltung von Einbettungen, Ähnlichkeitssuche und skalierbare KI-Anwendungen entwickelt wurde. Sie bietet Unterstützung für heterogene Datenverarbeitung, zuverlässige Speicherung, umfassende Metriken und eine Cloud-native Architektur. Sie bietet eine flexible API für Indizes, Abstandsmetriken und Abfragetypen und kann mit benutzerdefinierten Plugins auf Milliarden von Vektoren skaliert werden.
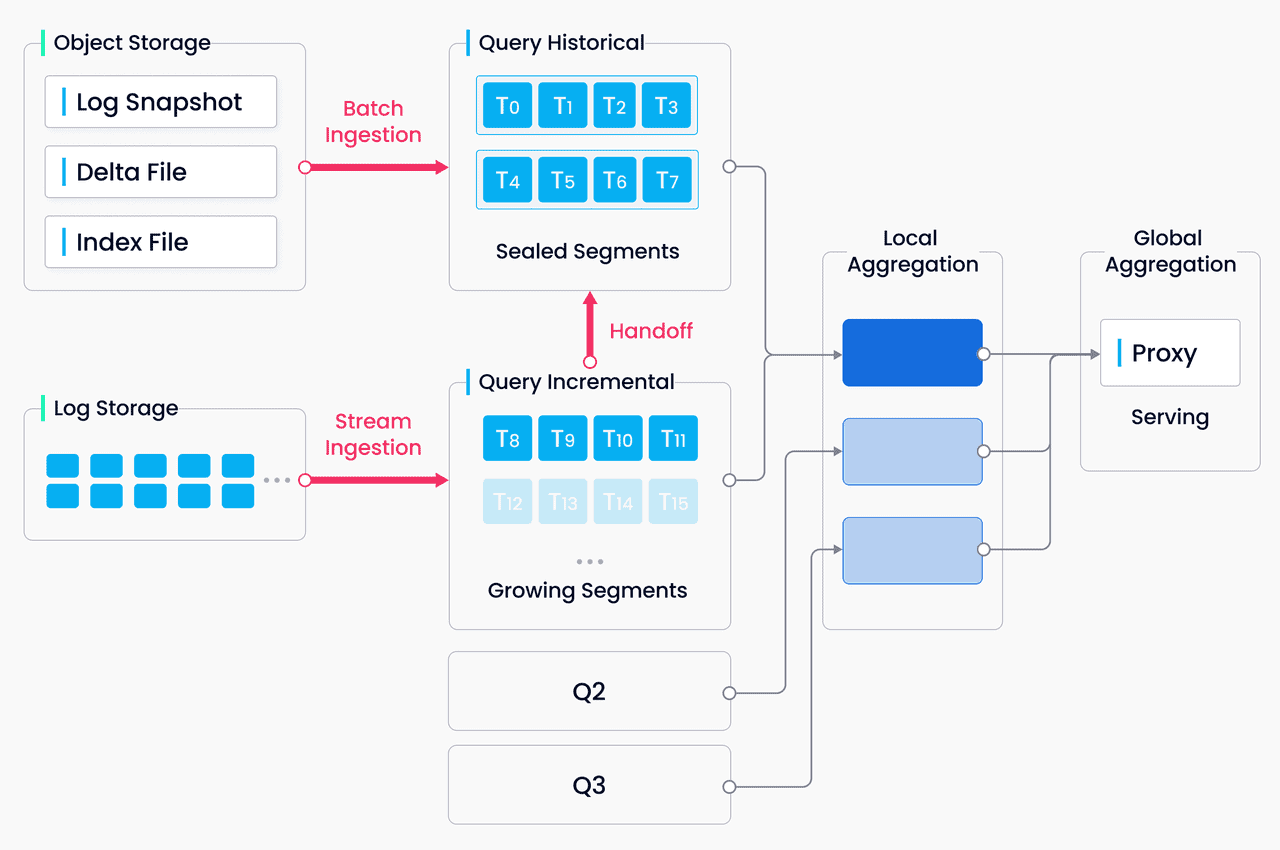
Auswahl der richtigen Vektordatenbank für Ihr Unternehmen
Ganz gleich, ob Sie eine semantische Suchmaschine, ein Empfehlungssystem oder eine andere KI-gestützte Anwendung entwickeln, Vektordatenbanken bilden die Grundlage für die Ausschöpfung des vollen Potenzials von Modellen für maschinelles Lernen. Diese Datenbanken ermöglichen eine schnelle Ähnlichkeitssuche, fortschrittliche Filterung und eine nahtlose Integration in gängige Frameworks. So können sich Entwickler auf die Entwicklung innovativer Lösungen konzentrieren, ohne sich um die zugrunde liegende Komplexität der Verwaltung von Vektordaten kümmern zu müssen.
Für noch mehr Inhalte zum Thema KI für Unternehmen, einschließlich Infografiken, Statistiken, Anleitungen, Artikeln und Videos, folgen Sie Skim AI auf LinkedIn
Sie sind Gründer, CEO, Risikokapitalgeber oder Investor und suchen nach fachkundiger KI-Beratung oder Due-Diligence-Dienstleistungen? Holen Sie sich die Beratung, die Sie brauchen, um fundierte Entscheidungen über die KI-Produktstrategie Ihres Unternehmens oder Investitionsmöglichkeiten zu treffen.
Wir bauen maßgeschneiderte AI-Lösungen für mit Risikokapital und privatem Beteiligungskapital finanzierte Unternehmen in den folgenden Branchen: Medizintechnik, Nachrichten/Content-Aggregation, Film- und Fotoproduktion, Bildungstechnologie, Rechtstechnologie, Fintech und Kryptowährungen.


