
AI Research Paper Breakdown für ChainPoll: Eine hocheffiziente Methode zur Erkennung von LLM-Halluzinationen



In diesem Artikel werden wir eine wichtige Forschungsarbeit aufschlüsseln, die sich mit einer der dringendsten Herausforderungen für große Sprachmodelle (LLMs) befasst: Halluzinationen. Das Papier mit dem Titel "ChainPoll: Eine hocheffiziente Methode zur Erkennung von LLM-Halluzinationenstellt einen neuartigen Ansatz vor, um diese von der KI erzeugten Ungenauigkeiten zu erkennen und abzumildern.
In dem von Forschern der Galileo Technologies Inc. verfassten ChainPoll-Papier wird eine neue Methode zur Erkennung von Halluzinationen in LLM-Ausgaben vorgestellt. Diese Methode mit dem Namen ChainPoll übertrifft bestehende Alternativen sowohl in der Genauigkeit als auch in der Effizienz. Darüber hinaus wird RealHall vorgestellt, eine sorgfältig kuratierte Reihe von Benchmark-Datensätzen, die entwickelt wurde, um Halluzinationserkennungsmetriken effektiver als bisherige Benchmarks zu bewerten.
Halluzinationen in LLMs beziehen sich auf Fälle, in denen diese KI-Modelle Text generieren, der sachlich falsch, unsinnig oder ohne Bezug zu den Eingabedaten ist. Da LLMs zunehmend in verschiedene Anwendungen integriert werden, von Chatbots bis hin zu Tools zur Erstellung von Inhalten, wächst das Risiko der Verbreitung von Fehlinformationen durch diese Halluzinationen exponentiell. Dieses Problem stellt eine große Herausforderung für die Zuverlässigkeit und Vertrauenswürdigkeit von KI-generierten Inhalten dar.
Die Fähigkeit, Halluzinationen genau zu erkennen und abzuschwächen, ist entscheidend für den verantwortungsvollen Einsatz von KI-Systemen. Diese Forschung bietet eine robustere Methode zur Erkennung dieser Fehler, die zu einer verbesserten Zuverlässigkeit von KI-generierten Inhalten, einem größeren Vertrauen der Nutzer in KI-Anwendungen und einem geringeren Risiko der Verbreitung von Fehlinformationen durch KI-Systeme führen kann. Indem das Problem der Halluzinationen angegangen wird, ebnet diese Forschung den Weg für zuverlässigere und vertrauenswürdigere KI-Anwendungen in verschiedenen Branchen.

Hintergrund und Problemstellung
Die Erkennung von Halluzinationen in LLM-Ausgaben ist aufgrund mehrerer Faktoren eine komplexe Aufgabe. Die schiere Menge an Text, die LLMs erzeugen können, in Kombination mit der oft subtilen Natur von Halluzinationen, macht es schwierig, sie von korrekten Informationen zu unterscheiden. Darüber hinaus erschweren die kontextabhängige Natur vieler Halluzinationen und das Fehlen einer umfassenden "Grundwahrheit", anhand derer alle generierten Inhalte überprüft werden können, den Erkennungsprozess zusätzlich.
Vor der Veröffentlichung der ChainPoll-Studie stießen die bestehenden Methoden zur Erkennung von Halluzinationen auf mehrere Einschränkungen. Vielen mangelte es an Effektivität bei verschiedenen Aufgaben und in verschiedenen Bereichen, während andere für Echtzeitanwendungen zu rechenintensiv waren. Einige Methoden waren von bestimmten Modellarchitekturen oder Trainingsdaten abhängig, und die meisten hatten Schwierigkeiten, zwischen verschiedenen Arten von Halluzinationen zu unterscheiden, z. B. zwischen sachlichen und kontextuellen Fehlern.
Darüber hinaus spiegeln die zur Bewertung dieser Methoden verwendeten Benchmarks häufig nicht die wahren Herausforderungen wider, die sich den modernsten LLMs in realen Anwendungen stellen. Viele basierten auf älteren, schwächeren Modellen oder konzentrierten sich auf enge, spezifische Aufgaben, die nicht die gesamte Bandbreite der LLM-Fähigkeiten und potenziellen Halluzinationen repräsentierten.
Um diese Probleme anzugehen, verfolgten die Forscher der ChainPoll-Studie einen zweigleisigen Ansatz:
Entwicklung einer neuen, wirksameren Methode zur Erkennung von Halluzinationen (ChainPoll)
Schaffung einer relevanteren und anspruchsvolleren Benchmark-Suite (RealHall)
Mit diesem umfassenden Ansatz sollte nicht nur die Erkennung von Halluzinationen verbessert, sondern auch ein robusterer Rahmen für die Bewertung und den Vergleich verschiedener Erkennungsmethoden geschaffen werden.
Die wichtigsten Beiträge des Papiers
Das ChainPoll-Papier liefert drei primäre Beiträge zum Bereich der KI-Forschung und -Entwicklung, die sich jeweils mit einem kritischen Aspekt der Herausforderung der Halluzinationserkennung befassen.
Erstens wird ChainPoll vorgestellteine neuartige Methodik zur Erkennung von Halluzinationen. ChainPoll nutzt die Leistung der LLMs selbst, um Halluzinationen zu identifizieren, und verwendet eine sorgfältig entwickelte Prompting-Technik und eine Aggregationsmethode, um die Genauigkeit und Zuverlässigkeit zu verbessern. Es nutzt die Gedankenkette, um detailliertere und systematischere Erklärungen zu erhalten, führt mehrere Iterationen des Erkennungsprozesses durch, um die Zuverlässigkeit zu erhöhen, und passt sich sowohl an Halluzinationen in offenen als auch in geschlossenen Bereichen an.
Zweitens erkannten die Autoren die Grenzen der bestehenden Benchmarks und entwickelten RealHalleine neue Reihe von Benchmark-Datensätzen. RealHall wurde entwickelt, um eine realistischere und anspruchsvollere Bewertung von Methoden zur Erkennung von Halluzinationen zu ermöglichen. Sie umfasst vier sorgfältig ausgewählte Datensätze, die selbst für modernste LLMs eine Herausforderung darstellen, konzentriert sich auf Aufgaben, die für LLM-Anwendungen in der realen Welt relevant sind, und deckt sowohl Halluzinationsszenarien in offenen als auch in geschlossenen Bereichen ab.
Schließlich bietet das Papier einen gründlichen Vergleich von ChainPoll mit einer breiten Palette von bestehenden Methoden zur Erkennung von Halluzinationen. Diese umfassende Bewertung verwendet die neu entwickelte RealHall-Benchmark-Suite, umfasst sowohl etablierte Messgrößen als auch jüngste Innovationen in diesem Bereich und berücksichtigt Faktoren wie Genauigkeit, Effizienz und Kosteneffizienz. Anhand dieser Bewertung zeigt das Papier die überlegene Leistung von ChainPoll bei verschiedenen Aufgaben und Halluzinationstypen.
Mit diesen drei wichtigen Beiträgen bringt das ChainPoll-Papier nicht nur den Stand der Technik bei der Erkennung von Halluzinationen voran, sondern bietet auch einen robusteren Rahmen für künftige Forschung und Entwicklung in diesem kritischen Bereich der KI-Sicherheit und -Zuverlässigkeit.
Ein Blick auf die ChainPoll-Methodik
Im Kern nutzt ChainPoll die Fähigkeiten großer Sprachmodelle selbst, um Halluzinationen in KI-generiertem Text zu identifizieren. Dieser Ansatz zeichnet sich durch seine Einfachheit, Effektivität und Anpassungsfähigkeit für verschiedene Arten von Halluzinationen aus.
Wie ChainPoll funktioniert
Die ChainPoll-Methode beruht auf einem einfachen, aber leistungsfähigen Prinzip. Sie verwendet ein LLM (in den Experimenten der Arbeit speziell GPT-3.5-Turbo), um zu bewerten, ob eine gegebene Textvervollständigung Halluzinationen enthält.
Der Prozess umfasst drei wichtige Schritte:
Zunächst fordert das System den LLM auf, das Vorhandensein von Halluzinationen im Zieltext zu bewerten, wobei ein sorgfältig ausgearbeitetes Aufforderung.
Anschließend wird dieser Vorgang mehrmals, in der Regel fünfmal, wiederholt, um die Zuverlässigkeit zu gewährleisten.
Schließlich berechnet das System eine Punktzahl, indem es die Anzahl der "Ja"-Antworten (die das Vorhandensein von Halluzinationen anzeigen) durch die Gesamtzahl der Antworten teilt.
Dieser Ansatz ermöglicht es ChainPoll, die Sprachverständnisfähigkeiten von LLMs zu nutzen und gleichzeitig individuelle Bewertungsfehler durch Aggregation zu minimieren.
Die Rolle der Gedankenkettenanregung
Eine entscheidende Neuerung in ChainPoll ist die Verwendung der Gedankenkette (Chain of Thought, CoT) als Aufforderung. Diese Technik ermutigt das LLM, eine schrittweise Erklärung seiner Überlegungen abzugeben, wenn es feststellt, ob ein Text Halluzinationen enthält. Die Autoren fanden heraus, dass eine sorgfältig ausgearbeitete "detaillierte CoT"-Aufforderung dem Modell durchweg systematischere und zuverlässigere Erklärungen entlockte.
Durch die Einbeziehung von CoT verbessert ChainPoll nicht nur die Genauigkeit der Erkennung von Halluzinationen, sondern bietet auch wertvolle Einblicke in den Entscheidungsprozess des Modells. Diese Transparenz kann entscheidend sein, um zu verstehen, warum bestimmte Texte als Halluzinationen enthaltend gekennzeichnet werden, was in Zukunft bei der Entwicklung robusterer LLMs helfen könnte.
Unterscheidung zwischen Halluzinationen im offenen und im geschlossenen Bereich
Eine der Stärken von ChainPoll ist die Fähigkeit, sowohl Halluzinationen im offenen als auch im geschlossenen Bereich zu erfassen. Halluzinationen mit offenem Bereich beziehen sich auf falsche Behauptungen über die Welt im Allgemeinen, während Halluzinationen mit geschlossenem Bereich Unstimmigkeiten mit einem bestimmten Referenztext oder Kontext beinhalten.
Um mit diesen verschiedenen Arten von Halluzinationen umzugehen, entwickelten die Autoren zwei Varianten von ChainPoll: ChainPoll-Korrektheit für Halluzinationen in offenen Bereichen und ChainPoll-Adherence für Halluzinationen im geschlossenen Bereich. Diese Varianten unterscheiden sich in erster Linie durch ihre Prompting-Strategie, die es dem System ermöglicht, sich an unterschiedliche Bewertungskontexte anzupassen, während die Kernmethodik von ChainPoll beibehalten wird.
Die RealHall Benchmark Suite
Die Autoren erkannten die Grenzen bestehender Benchmarks und entwickelten RealHall, eine neue Benchmark-Suite, die eine realistischere und anspruchsvollere Bewertung von Methoden zur Erkennung von Halluzinationen ermöglicht.
Kriterien für die Auswahl von Datensätzen (Herausforderung, Realismus, Aufgabenvielfalt)
Die Gründung von RealHall wurde von drei Grundprinzipien geleitet:
Herausforderung: Die Datensätze dürften selbst für modernste LLMs erhebliche Schwierigkeiten bereiten, so dass der Benchmark auch bei verbesserten Modellen relevant bleibt.
Realismus: Die Aufgaben sollten die realen Anwendungen von LLMs genau widerspiegeln, damit die Benchmark-Ergebnisse besser auf praktische Szenarien anwendbar sind.
Aufgabe Diversität: Die Suite sollte ein breites Spektrum von LLM-Fähigkeiten abdecken und eine umfassende Bewertung von Methoden zur Erkennung von Halluzinationen ermöglichen.
Diese Kriterien führten zur Auswahl von vier Datensätzen, die zusammen ein robustes Testfeld für Methoden zur Erkennung von Halluzinationen bieten.
Überblick über die vier Datensätze in RealHall
RealHall umfasst zwei Paare von Datensätzen, die jeweils einen anderen Aspekt der Halluzinationserkennung behandeln:
RealHall geschlossen: Dieses Paar umfasst den COVID-QA mit Retrieval-Datensatz und den DROP-Datensatz. Diese konzentrieren sich auf Halluzinationen in geschlossenen Bereichen und testen die Fähigkeit eines Modells, mit den bereitgestellten Referenztexten konsistent zu bleiben.
RealHall Open: Dieses Paar besteht aus dem Open Assistant prompts-Datensatz und dem TriviaQA-Datensatz. Diese zielen auf Halluzinationen in offenen Bereichen ab und bewerten die Fähigkeit eines Modells, falsche Aussagen über die Welt zu vermeiden.
Jeder Datensatz in RealHall wurde aufgrund seiner einzigartigen Herausforderungen und seiner Relevanz für reale LLM-Anwendungen ausgewählt. Zum Beispiel ahmt der COVID-QA-Datensatz Abruf-erweiterte Generierungsszenarien nach, während DROP diskrete Argumentationsfähigkeiten testet.
Wie RealHall die Grenzen früherer Benchmarks überwindet
RealHall stellt in mehrfacher Hinsicht eine erhebliche Verbesserung gegenüber früheren Benchmarks dar. Erstens werden neuere und leistungsfähigere LLMs zur Generierung von Antworten verwendet, wodurch sichergestellt wird, dass die erkannten Halluzinationen repräsentativ für diejenigen sind, die von aktuellen State-of-the-Art-Modellen erzeugt werden. Damit wird ein häufiges Problem älterer Benchmarks behoben, bei denen veraltete Modelle verwendet wurden, die leicht erkennbare Halluzinationen erzeugten.
Zweitens bedeutet der Fokus von RealHall auf Aufgabenvielfalt und Realismus, dass er eine umfassendere und praktisch relevante Bewertung von Halluzinationserkennungsmethoden bietet. Dies steht im Gegensatz zu vielen früheren Benchmarks, die sich auf enge, spezifische Aufgaben oder künstliche Szenarien konzentrierten.
Schließlich ermöglicht RealHall durch die Einbeziehung von Aufgaben mit offener und geschlossener Domäne eine nuanciertere Bewertung von Halluzinationserkennungsmethoden. Dies ist besonders wichtig, da viele LLM-Anwendungen in der realen Welt beide Arten der Halluzinationserkennung erfordern.
Durch diese Verbesserungen bietet RealHall einen strengeren und relevanteren Maßstab für die Bewertung von Methoden zur Erkennung von Halluzinationen und setzt damit einen neuen Standard in diesem Bereich.
Experimentelle Ergebnisse und Analyse
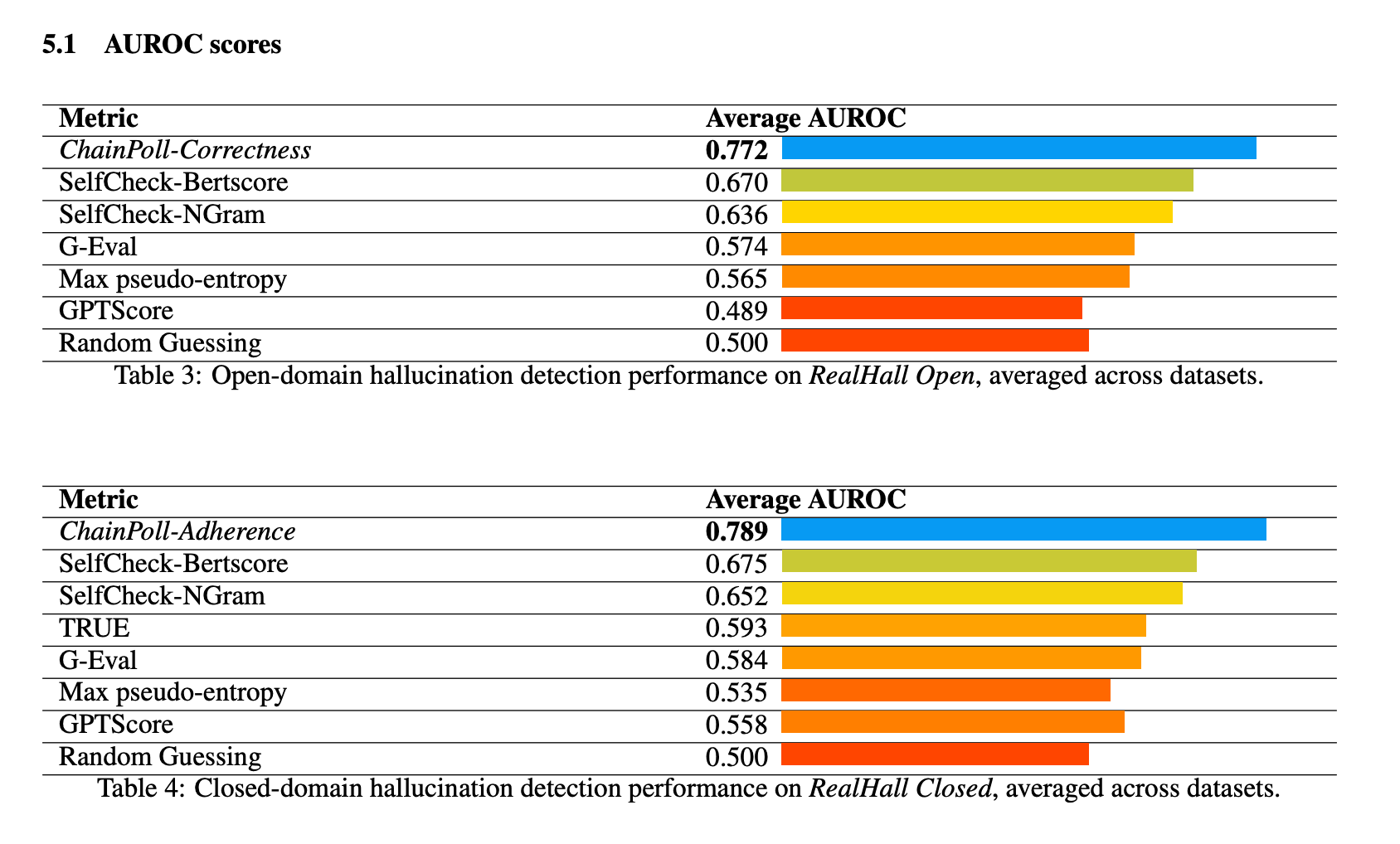
ChainPoll zeigte bei allen Benchmarks der RealHall-Suite eine hervorragende Leistung. Es erreichte einen AUROC-Wert (Area Under the Receiver Operating Characteristic curve) von 0,781 und übertraf damit die nächstbeste Methode, SelfCheck-BertScore, mit einem Wert von 0,673 deutlich. Diese erhebliche Verbesserung gegenüber 10% stellt einen bedeutenden Sprung in der Fähigkeit zur Erkennung von Halluzinationen dar.
Andere getestete Methoden waren SelfCheck-NGram, G-Eval und GPTScore, die alle deutlich schlechter abschnitten als ChainPoll. Interessanterweise schnitten einige Methoden, die sich in früheren Studien als vielversprechend erwiesen hatten, wie GPTScore, bei den anspruchsvolleren und vielfältigeren RealHall-Benchmarks schlecht ab.

Die Leistung von ChainPoll war sowohl bei Aufgaben zur Erkennung von Halluzinationen im offenen als auch im geschlossenen Bereich konstant gut. Bei Aufgaben im offenen Bereich (unter Verwendung von ChainPoll-Correctness) erreichte es einen durchschnittlichen AUROC von 0,772, während es bei Aufgaben im geschlossenen Bereich (unter Verwendung von ChainPoll-Adherence) 0,789 erzielte.
Die Methode erwies sich als besonders stark bei anspruchsvollen Datensätzen wie DROP, die diskrete Schlussfolgerungen erfordern.
Neben seiner überragenden Genauigkeit erwies sich ChainPoll auch als effizienter und kostengünstiger als viele konkurrierende Methoden. Es erzielt seine Ergebnisse, während es nur 1/4 so viel LLM-Inferenz benötigt wie die nächstbeste Methode, SelfCheck-BertScore. Außerdem erfordert ChainPoll keine zusätzlichen Modelle wie BERT, was den Rechenaufwand weiter reduziert.
Diese Effizienz ist für praktische Anwendungen von entscheidender Bedeutung, da sie die Erkennung von Halluzinationen in Echtzeit in Produktionsumgebungen ermöglicht, ohne dass dabei unerschwingliche Kosten oder Latenzzeiten entstehen.
Implikationen und zukünftige Arbeiten
ChainPoll stellt einen bedeutenden Fortschritt auf dem Gebiet der Erkennung von Halluzinationen bei LLMs dar. Sein Erfolg zeigt das Potenzial der Verwendung von LLMs selbst als Werkzeuge zur Verbesserung der KI-Sicherheit und -Zuverlässigkeit. Dieser Ansatz eröffnet neue Wege für die Erforschung selbstverbessernder und selbstüberprüfender KI-Systeme.
Aufgrund seiner Effizienz und Genauigkeit eignet sich ChainPoll für die Integration in eine breite Palette von KI-Anwendungen. Es könnte verwendet werden, um die Zuverlässigkeit von Chatbots zu erhöhen, die Genauigkeit von KI-generierten Inhalten in Bereichen wie Journalismus oder technischer Redaktion zu verbessern und die Vertrauenswürdigkeit von KI-Assistenten in kritischen Bereichen wie dem Gesundheits- oder Finanzwesen zu erhöhen.
Obwohl ChainPoll beeindruckende Ergebnisse zeigt, gibt es noch Raum für weitere Forschung und Verbesserungen. Zukünftige Arbeiten könnten erforscht werden:
Anpassung von ChainPoll an eine breitere Palette von LLMs und Sprachaufgaben
Untersuchung von Möglichkeiten zur weiteren Verbesserung der Effizienz ohne Abstriche bei der Genauigkeit
Erforschung des Potenzials von ChainPoll für andere Arten von KI-generierten Inhalten als Text
Entwicklung von Methoden, um Halluzinationen nicht nur zu erkennen, sondern auch in Echtzeit zu korrigieren oder zu verhindern
Das ChainPoll-Papier leistet durch die Einführung einer neuartigen Methode zur Erkennung von Halluzinationen und eines robusteren Bewertungsmaßstabs einen wichtigen Beitrag zum Bereich der KI-Sicherheit und -Zuverlässigkeit. Durch den Nachweis einer überlegenen Leistung bei der Erkennung von Halluzinationen sowohl im offenen als auch im geschlossenen Bereich ebnet ChainPoll den Weg für vertrauenswürdigere KI-Systeme. Da LLMs eine immer wichtigere Rolle in verschiedenen Anwendungen spielen, ist die Fähigkeit, Halluzinationen genau zu erkennen und zu entschärfen, von entscheidender Bedeutung. Diese Forschungsarbeit erweitert nicht nur unsere derzeitigen Fähigkeiten, sondern eröffnet auch neue Wege für die zukünftige Erforschung und Entwicklung im kritischen Bereich der KI-Halluzinationserkennung.


