
튜토리얼: 처음부터 스페인어용 ELECTRA를 사전 교육하는 방법
튜토리얼: 처음부터 스페인어용 ELECTRA를 사전 교육하는 방법
Skim AI의 머신러닝 연구원 크리스 트란이 처음 게시했습니다.소개
이 글에서는 Transformer 사전 훈련 방법 제품군의 또 다른 구성원인 ELECTRA를 스페인어용으로 사전 훈련하여 자연어 처리 벤치마크에서 최첨단 결과를 얻는 방법에 대해 설명합니다. 다양한 사용 사례를 위한 스페인어용 맞춤형 BERT 언어 모델 훈련에 대한 시리즈 중 3부입니다:
1. 소개
ICLR 2020에서, ELECTRA: 텍스트 인코더를 생성기가 아닌 판별기로 사전 훈련하기라는 새로운 자기 지도 언어 표현 학습 방법을 소개했습니다. 일렉트라는 트랜스포머 사전 훈련 방법 계열의 또 다른 멤버로, 이전 멤버인 BERT, GPT-2, RoBERTa는 자연어 처리 벤치마크에서 많은 최첨단 결과를 달성한 바 있습니다.
다른 마스크 언어 모델링 방법과 달리, ELECTRA는 대체 토큰 감지를 통해 샘플 효율성이 높은 사전 학습 작업을 수행합니다. 소규모의 경우, 단일 GPU에서 4일 동안 ELECTRA-small을 훈련하여 성능을 향상시킬 수 있습니다. GPT(Radford et al., 2018) (30배 더 많은 컴퓨팅을 사용하여 훈련됨) GLUE 벤치마크에서. 대규모에서는 ELECTRA-large가 다음을 능가합니다. ALBERT(Lan et al., 2019) 를 통해 SQuAD 2.0을 위한 새로운 최첨단 기술을 선보입니다.

ELECTRA는 마스킹 언어 모델 사전 학습 방식보다 지속적으로 뛰어난 성능을 발휘합니다.
{: .text-center}
2. 방법
다음과 같은 마스크드 언어 모델링 사전 학습 방법 BERT(Devlin 외, 2019) 일부 토큰(일반적으로 입력의 15%)을 다음과 같이 대체하여 입력을 손상시킵니다. [마스크] 를 입력한 다음 모델을 학습시켜 원래 토큰을 재구성합니다.
마스킹 대신 ELECTRA는 일부 토큰을 축소된 마스킹 언어 모델 출력의 샘플로 대체하여 입력을 손상시킵니다. 그런 다음 각 토큰이 원본인지 대체품인지 예측하기 위해 판별 모델을 학습시킵니다. 사전 훈련 후에는 생성기를 버리고 판별기를 다운스트림 작업에서 미세 조정합니다.
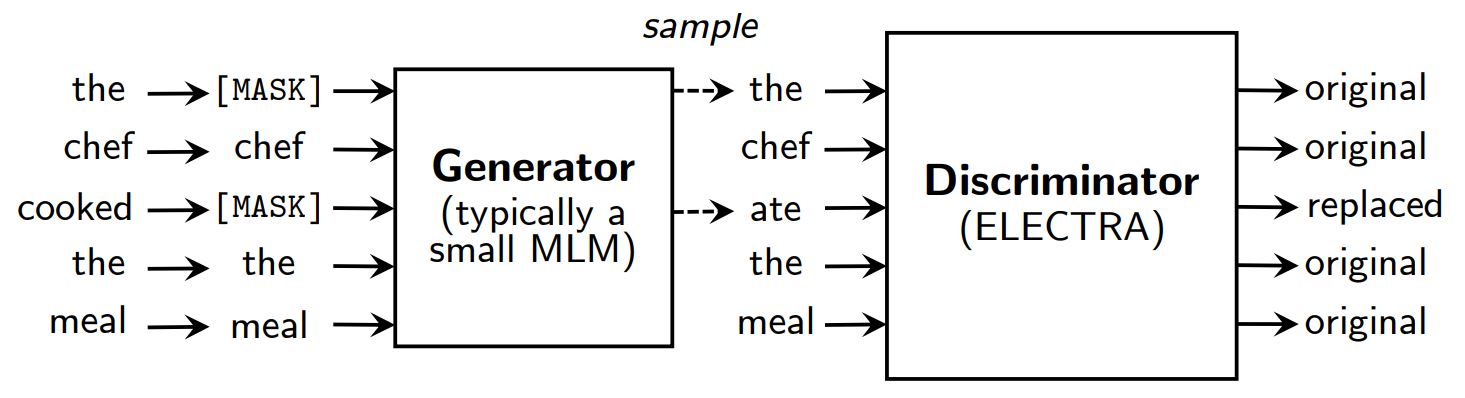
ELECTRA에 대한 개요입니다.
{: .text-center}
GAN과 같은 생성기와 감별기가 있지만, ELECTRA는 손상된 토큰을 생성하는 생성기가 감별기를 속이도록 훈련되는 것이 아니라 최대한의 확률로 훈련된다는 점에서 적대적이지 않습니다.
ELECTRA가 왜 그렇게 효율적인가요?
새로운 교육 목표를 통해 ELECTRA는 다음과 같은 강력한 모델에 필적하는 성능을 달성할 수 있습니다. RoBERTa(Liu 외, (2019)) 는 더 많은 파라미터를 가지고 있으며 훈련에 4배 더 많은 컴퓨팅이 필요합니다. 이 논문에서는 ELECTRA의 효율성에 실제로 기여하는 요소를 파악하기 위해 분석을 수행했습니다. 주요 결과는 다음과 같습니다:
- ELECTRA는 일부 토큰이 아닌 모든 입력 토큰에 대해 손실을 정의함으로써 큰 이점을 누리고 있습니다. 좀 더 구체적으로 설명하자면, ELECTRA에서는 판별기가 입력된 모든 토큰을 예측하는 반면, BERT에서는 제너레이터가 입력된 15% 마스크 토큰만 예측합니다.
- 사전 학습 단계에서 모델이 다음을 보기 때문에 BERT의 성능이 약간 저하됩니다.
[마스크]토큰을 사용할 수 있지만, 미세 조정 단계에서는 그렇지 않습니다.
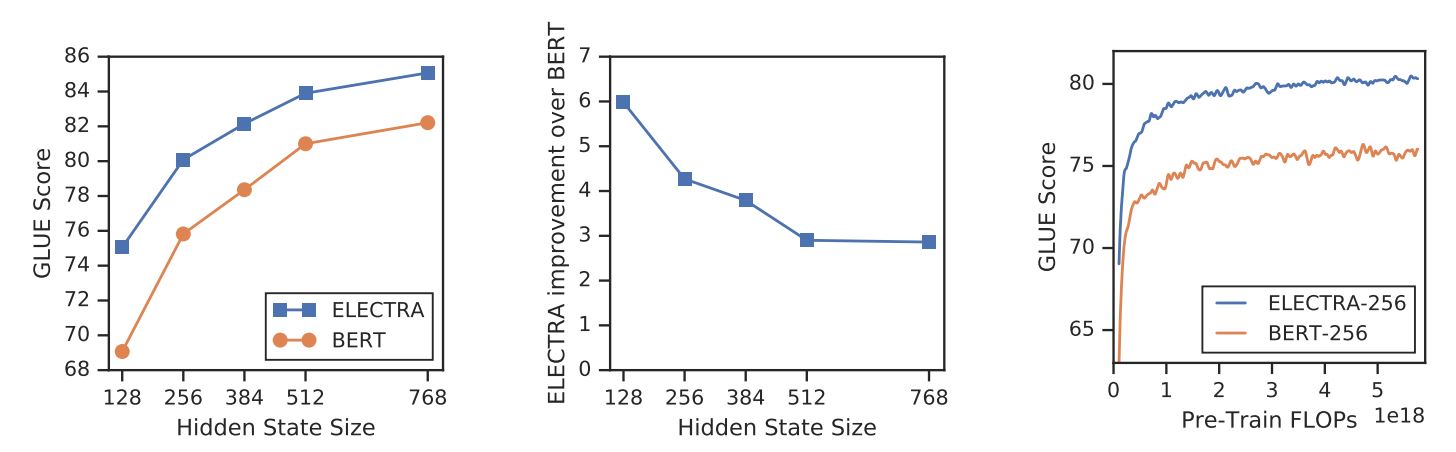
일렉트라와 버트
{: .text-center}
3. ELECTRA 사전 교육
이 섹션에서는 ELECTRA의 작성자가 제공한 스크립트를 사용하여 TensorFlow로 ELECTRA를 처음부터 학습합니다. 구글-연구/일렉트라. 그런 다음 모델을 파이토치의 체크포인트로 변환하고, 허깅 페이스의 트랜스포머 라이브러리.
설정
!pip install tensorflow==1.15
!pip install transformers==2.8.0
!.git clone https://github.com/google-research/electra.git
import os
import json
트랜스포머에서 오토토큰라이저를 가져옵니다.
데이터
오픈서브타이틀에서 검색한 스페인어 영화 자막 데이터셋으로 ELECTRA를 사전 훈련합니다. 이 데이터 세트의 크기는 5.4GB이며 프레젠테이션을 위해 약 30MB의 작은 하위 집합으로 훈련할 것입니다.
DATA_DIR = "./data" #@param {type: "문자열"}
TRAIN_SIZE = 1000000 #@param {유형:"정수"}
MODEL_NAME = "electra-spanish" #@param {type: "문자열"}
# 스페인어 영화 자막 데이터 세트 다운로드 및 압축 풀기
os.path.exists(DATA_DIR)가 아닌 경우:
!.mkdir -p $DATA_DIR
!.wget "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz" -O $DATA_DIR/OpenSubtitles.txt.gz
!.gzip -d $DATA_DIR/OpenSubtitles.txt.gz
!head -n $TRAIN_SIZE $DATA_DIR/OpenSubtitles.txt > $DATA_DIR/train_data.txt
!.rm $DATA_DIR/OpenSubtitles.txt
사전 학습 데이터 집합을 구축하기 전에 말뭉치의 형식이 다음과 같은지 확인해야 합니다:
- 각 줄은 문장입니다.
- 빈 줄은 두 문서를 구분합니다.
사전 학습 데이터 세트 구축
저희는 다음과 같은 토큰라이저를 사용할 것입니다. bert-기반-다국어-케이스 를 사용하여 스페인어 텍스트를 처리합니다.
# 사전 학습된 WordPiece 토큰라이저를 저장하여 vocab.txt를 가져옵니다.
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenizer.save_pretrained(DATA_DIR)
당사는 다음을 사용합니다. 빌드_프리트레이닝_데이터세트.py 를 사용하여 원시 텍스트 덤프에서 사전 학습 데이터 세트를 만들 수 있습니다.
!python3 electra/build_pretraining_dataset.py \.
--corpus-dir $DATA_DIR \.
--vocab-file $DATA_DIR/vocab.txt \.
--output-dir $DATA_DIR/pretrain_tfrecords \.
--max-seq-length 128 \
--blanks-separate-docs False \.
--소문자 없음 \
--num-processes 5
교육 시작
당사는 다음을 사용합니다. run_pretraining.py 를 사용하여 ELECTRA 모델을 사전 학습할 수 있습니다.
소형 일렉트라 모델을 1백만 걸음으로 훈련하려면 실행하세요:
python3 run_pretraining.py --data-dir $DATA_DIR --model-name electra_small
Tesla V100 GPU에서는 4일이 조금 넘게 걸립니다. 그러나 이 모델은 20만 걸음(v100 GPU에서 10시간 동안 훈련)을 수행한 후에도 괜찮은 결과를 얻을 수 있습니다.
교육을 사용자 지정하려면 .json 하이퍼파라미터가 포함된 파일입니다. 다음을 참조하세요. configure_pretraining.py 를 입력하면 모든 하이퍼파라미터의 기본값을 확인할 수 있습니다.
아래에서는 100단계에 대해서만 모델을 학습하도록 하이퍼파라미터를 설정했습니다.
hparams = {
"do_train": "true",
"do_eval": "false",
"model_size": "small",
"do_lower_case": "false",
"vocab_size": 119547,
"num_train_steps": 100,
"저장_체크포인트_단계": 100,
"train_batch_size": 32,
}
open("hparams.json", "w")를 f로 사용합니다:
json.dump(hparams, f)
교육을 시작하겠습니다:
!python3 electra/run_pretraining.py \.
--data-dir $DATA_DIR \.
--model-name $MODEL_NAME \.
--hparams "hparams.json"
가상 머신에서 훈련하는 경우, 터미널에서 다음 명령을 실행하여 TensorBoard로 훈련 과정을 모니터링하세요.
pip install -U tensorboard
tensorboard dev upload --logdir data/models/electra-spanish
이것은 텐서보드 V100 GPU에서 4일 동안 1백만 걸음을 걸을 수 있는 일렉트라 스몰 트레이닝을 수행했습니다.
 {: .align-center}
{: .align-center}
4. 텐서플로 체크포인트를 파이토치 형식으로 변환하기
허깅 페이스에는 도구 를 사용하여 텐서플로우 체크포인트를 PyTorch로 변환할 수 있습니다. 그러나 이 도구는 아직 ELECTRA용으로 업데이트되지 않았습니다. 다행히도 이 작업에 도움이 될 수 있는 @lonePatient의 GitHub 리포지토리를 발견했습니다.
!.git clone https://github.com/lonePatient/electra_pytorch.git
MODEL_DIR = "data/models/electra-spanish/"
config = {
"vocab_size": 119547,
"embedding_size": 128,
"hidden_size": 256,
"num_hidden_layers": 12,
"num_attention_heads": 4,
"intermediate_size": 1024,
"generator_size":"0.25",
"hidden_act": "젤루",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embedings": 512,
"type_vocab_size": 2,
"initializer_range": 0.02
}
open(MODEL_DIR + "config.json", "w")를 f로 사용합니다:
json.dump(config, f)
!.python electra_pytorch/convert_electra_tf_checkpoint_to_pytorch.py \.
--tf_checkpoint_path=$MODEL_DIR \.
--electra_config_file=$MODEL_DIR/config.json \.
--pytorch_dump_path=$MODEL_DIR/pytorch_model.bin
ELECTRA를 다음과 함께 사용하세요. 트랜스포머
모델 체크포인트를 PyTorch 형식으로 변환한 후, 사전 학습된 ELECTRA 모델을 다운스트림 작업에 사용할 수 있습니다. 트랜스포머 라이브러리.
토치 가져오기
트랜스포머에서 일렉트라포프리트레이닝, 일렉트라토커나이저패스트 가져오기
판별자 = ElectraForPreTraining.from_pretrained(MODEL_DIR)
토큰화기 = ElectraTokenizerFast.from_pretrained(DATA_DIR, do_lower_case=False)
문장 = "로스 파하로 에스탄 칸탄도" # 새들이 노래하고 있어요.
fake_sentence = "로스 파하로 에스탄 하블란도" # 새들이 말하고 있습니다.
fake_tokens = tokenizer.tokenize(fake_sentence, add_special_tokens=True)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
판별자_아웃풋 = 판별자(가짜_입력)
예측 = 판별자_아웃풋[0] > 0
[print("%7s" % 토큰, end="") for token in fake_tokens]
print("\n")
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()];
[CLS] 파즈 #1TP5타로 에스탄 하블라 #1TP5타도 [SEP]
1 0 0 0 0 0 0 0
저희 모델은 100단계만 학습되었기 때문에 예측이 정확하지 않습니다. 완전히 학습된 스페인어용 일렉트라 스몰은 아래와 같이 로드할 수 있습니다:
판별자 = ElectraForPreTraining.from_pretrained("skimai/electra-small-spanish")
토큰화기 = ElectraTokenizerFast.from_pretrained("skimai/electra-small-spanish", do_lower_case=False)
5. 결론
이 글에서는 ELECTRA 백서를 통해 ELECTRA가 현재 가장 효율적인 트랜스포머 사전 훈련 방식인 이유를 살펴봤습니다. 소규모의 경우, ELECTRA-small은 하나의 GPU로 4일 동안 트레이닝하여 GLUE 벤치마크에서 GPT를 능가하는 성능을 낼 수 있습니다. 대규모로 보면 ELECTRA-large는 SQuAD 2.0의 새로운 기준을 제시합니다.
그런 다음 실제로 스페인어 텍스트에 대해 ELECTRA 모델을 학습하고 Tensorflow 체크포인트를 PyTorch로 변환한 후 트랜스포머 라이브러리.
참조
- [1] ELECTRA: 텍스트 인코더를 생성기가 아닌 판별기로 사전 훈련하기
- [2] 구글-연구/일렉트라 - 원본 문서의 공식 깃허브 저장소
- [3] 일렉트라_피토치 - ELECTRA의 PyTorch 구현


