
Навчальний посібник: Як підготувати ELECTRA до вивчення іспанської мови з нуля



Навчальний посібник: Як підготувати ELECTRA до вивчення іспанської мови з нуля
Вперше опубліковано дослідником машинного навчання Skim AI, Крісом Траном.![]()
Вступ
У цій статті йдеться про те, як за допомогою ELECTRA, ще одного члена сімейства методів попереднього навчання Transformer, підготувати іспанську мову для досягнення найсучасніших результатів у тестах з обробки природної мови. Це третя частина серії статей про навчання користувацьких мовних моделей BERT для іспанської мови для різних сценаріїв використання:
- Частина I: Як навчити мовну модель RoBERTa для іспанської мови з нуля
- Частина II: Як навчити іспанську мовну модель SpanBERTa розпізнавати іменовані об'єкти (NER)
1. Вступ
На ICLR 2020, ELECTRA: попереднє навчання текстових кодерів як дискримінаторів, а не генераторівбуло представлено новий метод для самоконтролюючого навчання мовного представлення. ELECTRA є ще одним членом сімейства методів попереднього навчання Transformer, попередні члени якого, такі як BERT, GPT-2, RoBERTa, досягли багатьох найсучасніших результатів у тестах з обробки природної мови.
На відміну від інших методів моделювання замаскованої мови, ELECTRA - це більш ефективне завдання попереднього навчання, яке називається виявленням замінених токенів. У невеликих масштабах ELECTRA-small можна навчити на одному графічному процесорі за 4 дні, щоб перевершити GPT (Radford et al., 2018) (тренується з використанням у 30 разів більшої кількості обчислень) на бенчмарку GLUE. У великих масштабах ELECTRA-large перевершує ALBERT (Lan et al., 2019) на GLUE і встановлює нові стандарти для SQuAD 2.0.

ELECTRA постійно перевершує підходи до попереднього навчання на основі маскованих мовних моделей.
{: .text-center}
2. Метод
Моделювання мови за допомогою масок, такі методи попереднього навчання, як BERT (Devlin et al., 2019) зіпсувати вхідні дані, замінивши деякі токени (зазвичай 15% вхідних даних) на [МАСКА] а потім навчити модель відтворювати оригінальні токени.
Замість маскування ELECTRA спотворює вхідні дані, замінюючи деякі лексеми зразками з виходів зменшеної замаскованої мовної моделі. Потім навчається дискримінативна модель, щоб передбачити, чи була кожна лексема оригіналом або заміною. Після попереднього навчання генератор викидається, а дискримінатор налаштовується на наступних завданнях.
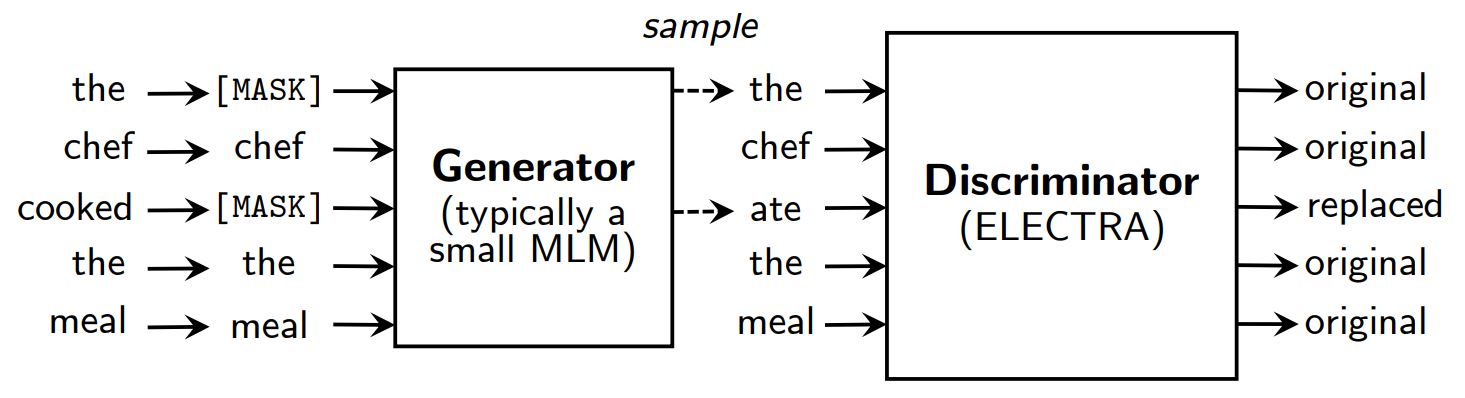
Огляд ELECTRA.
{: .text-center}
Незважаючи на наявність генератора і дискримінатора, подібного до GAN, ELECTRA не є змагальною в тому сенсі, що генератор, який виробляє пошкоджені токени, навчений з максимальною ймовірністю, а не для того, щоб обдурити дискримінатор.
Чому ELECTRA така ефективна?
З новою метою навчання ELECTRA може досягти порівнянної продуктивності з такими сильними моделями, як RoBERTa (Liu et al., (2019)) який має більше параметрів і потребує в 4 рази більше обчислень для навчання. У статті було проведено аналіз, щоб зрозуміти, що насправді сприяє ефективності ELECTRA. Ключові висновки такі:
- ELECTRA значно виграє від того, що втрати визначаються для всіх вхідних лексем, а не лише для їх підмножини. Зокрема, в ELECTRA дискримінатор прогнозує кожен лексему на вході, в той час як в BERT генератор прогнозує тільки 15% замасковані лексеми на вході.
- Продуктивність BERT дещо знижується, оскільки на етапі попереднього навчання модель бачить
[МАСКА]токени, тоді як на етапі тонкого налаштування це не так.
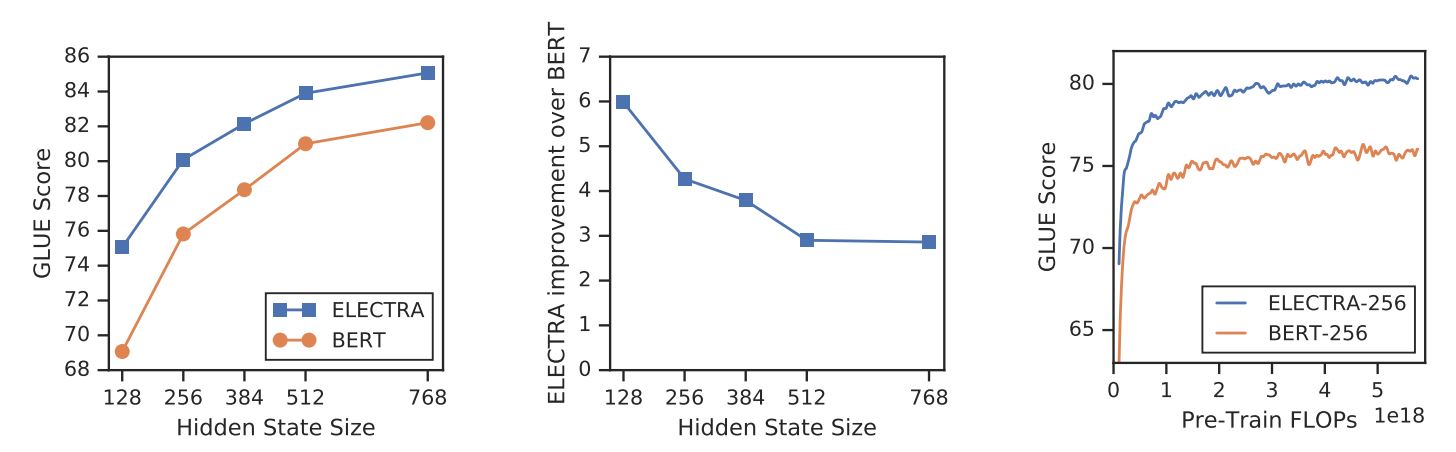
ELECTRA проти BERT
{: .text-center}
3. Попереднє тренування ELECTRA
У цьому розділі ми навчимо ELECTRA з нуля працювати з TensorFlow, використовуючи скрипти, надані авторами ELECTRA в google-research/electra. Потім ми перетворимо модель в чекпоінт PyTorch, який можна легко налаштувати для подальших завдань за допомогою Hugging Face's трансформатори бібліотека.
Налаштування
!pip install tensorflow==1.15
!pip install transformers==2.8.0
!git clone https://github.com/google-research/electra.git
import os
import json
from transformers import AutoTokenizer
Дані
Ми попередньо навчимо ELECTRA на наборі даних іспанських субтитрів до фільмів, отриманих з OpenSubtitles. Цей набір даних має розмір 5,4 ГБ, а для презентації ми потренуємось на невеликій підмножині розміром ~30 МБ.
DATA_DIR = "./data" #@param {type: "string"}
TRAIN_SIZE = 1000000 #@param {type: "integer"}
MODEL_NAME = "electra-spanish" #@param {type: "string"}
# Завантажте та розархівуйте набір даних іспанських субтитрів до фільмів
if not os.path.exists(DATA_DIR):
!mkdir -p $DATA_DIR
!wget "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz" -O $DATA_DIR/OpenSubtitles.txt.gz
!gzip -d $DATA_DIR/OpenSubtitles.txt.gz
!head -n $TRAIN_SIZE $DATA_DIR/OpenSubtitles.txt > $DATA_DIR/train_data.txt
!rm $DATA_DIR/OpenSubtitles.txt
Перед створенням набору даних для попереднього навчання ми повинні переконатися, що корпус має наступний формат:
- кожен рядок є реченням
- порожній рядок розділяє два документи
Створіть набір даних для попередньої підготовки
Ми будемо використовувати токенізатор bert-base-multilingual-cased для обробки іспанських текстів.
# Збережіть попередньо навчений токенізатор WordPiece, щоб отримати vocab.txt
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenizer.save_pretrained(DATA_DIR)
Ми використовуємо build_pretraining_dataset.py створити набір даних для попереднього навчання з дампа сирого тексту.
!python3 electra/build_pretraining_dataset.py \
--corpus-dir $DATA_DIR \
--vocab-file $DATA_DIR/vocab.txt \
--output-dir $DATA_DIR/pretrain_tfrecords \
--max-seq-length 128 \
--blanks-separate-docs False \
--no-lower-case \
--num-processes 5
Почніть тренування
Ми використовуємо run_pretraining.py для попереднього навчання моделі ELECTRA.
Щоб натренувати маленьку модель ELECTRA на 1 мільйон кроків, побігайте:
python3 run_pretraining.py --data-dir $DATA_DIR --model-name electra_small
Це займає трохи більше 4 днів на графічному процесорі Tesla V100. Однак модель повинна досягти пристойних результатів після 200 тис. кроків (10 годин навчання на графічному процесорі v100).
Щоб налаштувати тренінг, створіть .json файл, що містить гіперпараметри. Будь ласка, зверніться до configure_pretraining.py для значень за замовчуванням для всіх гіперпараметрів.
Нижче ми встановлюємо гіперпараметри для навчання моделі лише на 100 кроках.
hparams = {
"do_train": "true",
"do_eval": "false",
"model_size": "small",
"do_lower_case": "false",
"vocab_size": 119547,
"num_train_steps": 100,
"save_checkpoints_steps": 100,
"train_batch_size": 32,
}
з open("hparams.json", "w") як f:
json.dump(hparams, f)
Почнемо тренування:
!python3 electra/run_pretraining.py \
--data-dir $DATA_DIR \
--model-name $MODEL_NAME \
--hparams "hparams.json"
Якщо ви тренуєтесь на віртуальній машині, запустіть наступні рядки на терміналі, щоб контролювати процес тренування за допомогою TensorBoard.
pip install -U tensorboard
tensorboard dev upload --logdir data/models/electra-spanish
Це TensorBoard тренування ELECTRA-small на 1 мільйон кроків за 4 дні на графічному процесорі V100.
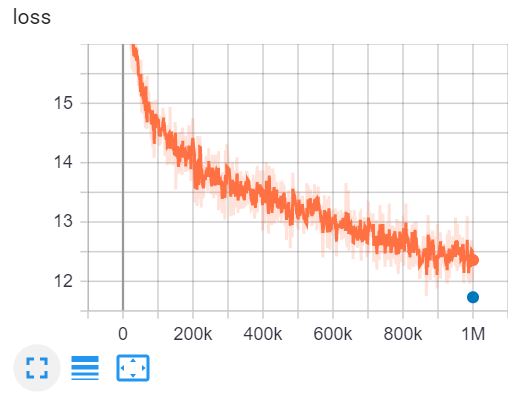 {: .align-center}
{: .align-center}
4. Конвертувати контрольні точки Tensorflow у формат PyTorch
Hugging Face має інструмент для перетворення контрольних точок Tensorflow у PyTorch. Однак цей інструмент ще не був оновлений для ELECTRA. На щастя, я знайшов репозиторій на GitHub від @lonePatient, який може допомогти нам з цим завданням.
!git clone https://github.com/lonePatient/electra_pytorch.git
MODEL_DIR = "data/models/electra-spanish/"
config = {{ "vocab size
"vocab_size": 119547,
"embedding_size": 128,
"hidden_size": 256,
"num_hidden_layers": 12,
"num_attention_heads": 4,
"intermediate_size": 1024,
"generator_size":"0.25",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 512,
"type_vocab_size": 2,
"initializer_range": 0.02
}
з open(MODEL_DIR + "config.json", "w") як f:
json.dump(config, f)
!python electra_pytorch/convert_electra_tf_checkpoint_to_pytorch.py \
--tf_checkpoint_path=$MODEL_DIR \
--electra_config_file=$MODEL_DIR/config.json \
--pytorch_dump_path=$MODEL_DIR/pytorch_model.bin
Використовуйте ELECTRA з трансформатори
Після перетворення контрольної точки моделі у формат PyTorch ми можемо почати використовувати нашу попередньо навчену модель ELECTRA для подальших завдань за допомогою трансформатори бібліотека.
імпортний ліхтар
з трансформаторів імпортувати ElectraForPreTraining, ElectraTokenizerFast
discriminator = ElectraForPreTraining.from_pretrained(MODEL_DIR)
tokenizer = ElectraTokenizerFast.from_pretrained(DATA_DIR, do_lower_case=False)
sentence = "Los pájaros están cantando" # Птахи співають
fake_sentence = "Los pájaros están hablando" # Птахи розмовляють
fake_tokens = tokenizer.tokenize(fake_sentence, add_special_tokens=True)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = discriminator_outputs[0] > 0
[print("%7s" % токен, end="") for token in fake_tokens]
print("\n")
[print("%7s" % int(prediction), end="") для prediction у predictions.tolist()];
[CLS] Los paj ##aros estan habla ##ndo [SEP].
1 0 0 0 0 0 0 0
Наша модель була навчена лише на 100 кроках, тому прогнози не є точними. Повністю навчену модель ELECTRA-small для іспанської мови можна завантажити нижче:
discriminator = ElectraForPreTraining.from_pretrained("skimai/electra-small-spanish")
tokenizer = ElectraTokenizerFast.from_pretrained("skimai/electra-small-spanish", do_lower_case=False)
5. Висновок
У цій статті ми розглянули документ ELECTRA, щоб зрозуміти, чому ELECTRA є найефективнішим підходом до попереднього навчання трансформаторів на даний момент. У невеликих масштабах ELECTRA-small можна тренувати на одному графічному процесорі протягом 4 днів, щоб перевершити GPT в тесті GLUE. У великих масштабах ELECTRA-large встановлює новий рівень технологій для SquAD 2.0.
Потім ми тренуємо модель ELECTRA на іспанських текстах, конвертуємо контрольну точку Tensorflow в PyTorch і використовуємо модель з трансформатори бібліотека.
Посилання
- [1] ELECTRA: попереднє навчання текстових кодерів як дискримінаторів, а не генераторів
- [2] google-research/electra - офіційний репозиторій GitHub оригіналу статті
- [3] electra_pytorch - реалізація ELECTRA на PyTorch


