
AI&YOU #68을 촉발하는 생각의 사슬(CoT)에 대해 다시 생각해야 합니다.



금주의 통계: Zero-shot CoT performance was only 5.55% for GPT-4-Turbo, 8.51% for Claude-3-Opus, and 4.44% for GPT-4. (“Chain of Thoughtlessness?” paper)
Chain-of-Thought (CoT) prompting has been hailed as a breakthrough in unlocking the reasoning capabilities of large language models (LLMs). However, recent research has challenged these claims and prompted us to revisit the technique.
이번 주 AI&YOU에서는 이 주제에 대해 게시한 세 개의 블로그에서 얻은 인사이트를 살펴봅니다:
We need to rethink chain-of-thought (CoT) prompting AI&YOU #68
LLMs demonstrate remarkable capabilities in natural language processing (NLP) and generation. However, when faced with complex reasoning tasks, these models can struggle to produce accurate and reliable results. This is where Chain-of-Thought (CoT) prompting comes into play, a technique that aims to enhance the problem-solving abilities of LLMs.
An advanced 프롬프트 엔지니어링 technique, it is designed to guide LLMs through a step-by-step reasoning process. Unlike standard prompting methods that aim for direct answers, CoT prompting encourages the model to generate intermediate reasoning steps before arriving at a final answer.
At its core, CoT prompting involves structuring input prompts in a way that elicits a logical sequence of thoughts from the model. By breaking down complex problems into smaller, manageable steps, CoT attempts to enable LLMs to navigate through intricate reasoning paths more effectively.
CoT 작동 방식
CoT 프롬프트의 핵심은 최종 답변에 도달하기 전에 일련의 중간 추론 단계를 통해 언어 모델을 안내하는 것입니다. 이 프로세스에는 일반적으로 다음이 포함됩니다:
문제 분해: 복잡한 작업은 관리하기 쉬운 작은 단계로 세분화됩니다.
단계별 추론: 모델에 각 단계를 명시적으로 생각하라는 메시지가 표시됩니다.
논리적 진행: 각 단계는 이전 단계를 기반으로 하여 생각의 연쇄를 만들어냅니다.
결론 도출: 최종 답은 누적된 추론 단계를 통해 도출됩니다.
CoT 프롬프트의 유형
생각의 연쇄 프롬프트는 다양한 방식으로 구현할 수 있으며, 두 가지 주요 유형이 있습니다:
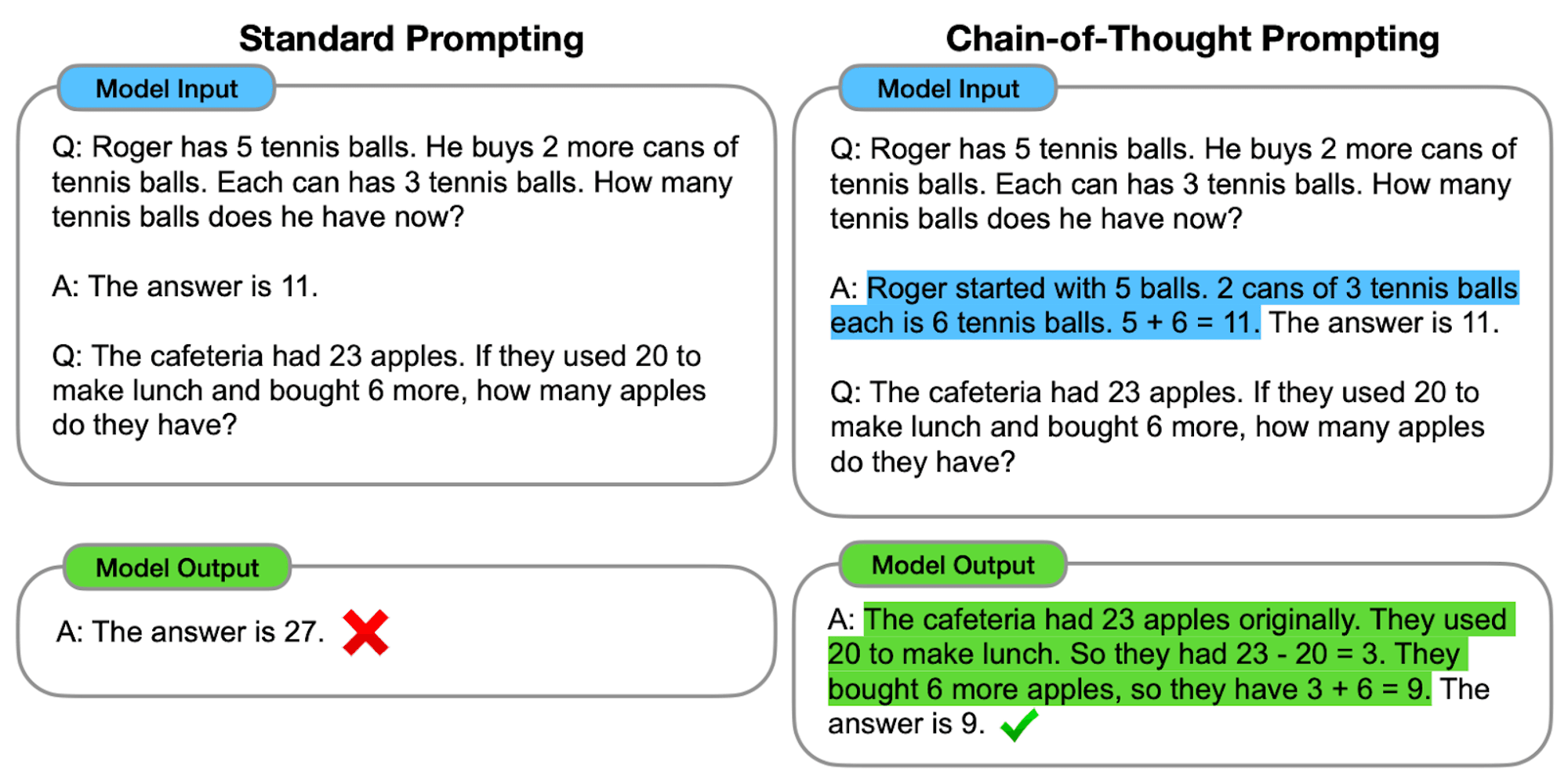
Zero-shot CoT: Zero-shot CoT doesn’t require task-specific examples. Instead, it uses a simple prompt like “Let’s approach this step by step” to encourage the model to break down its reasoning process.****
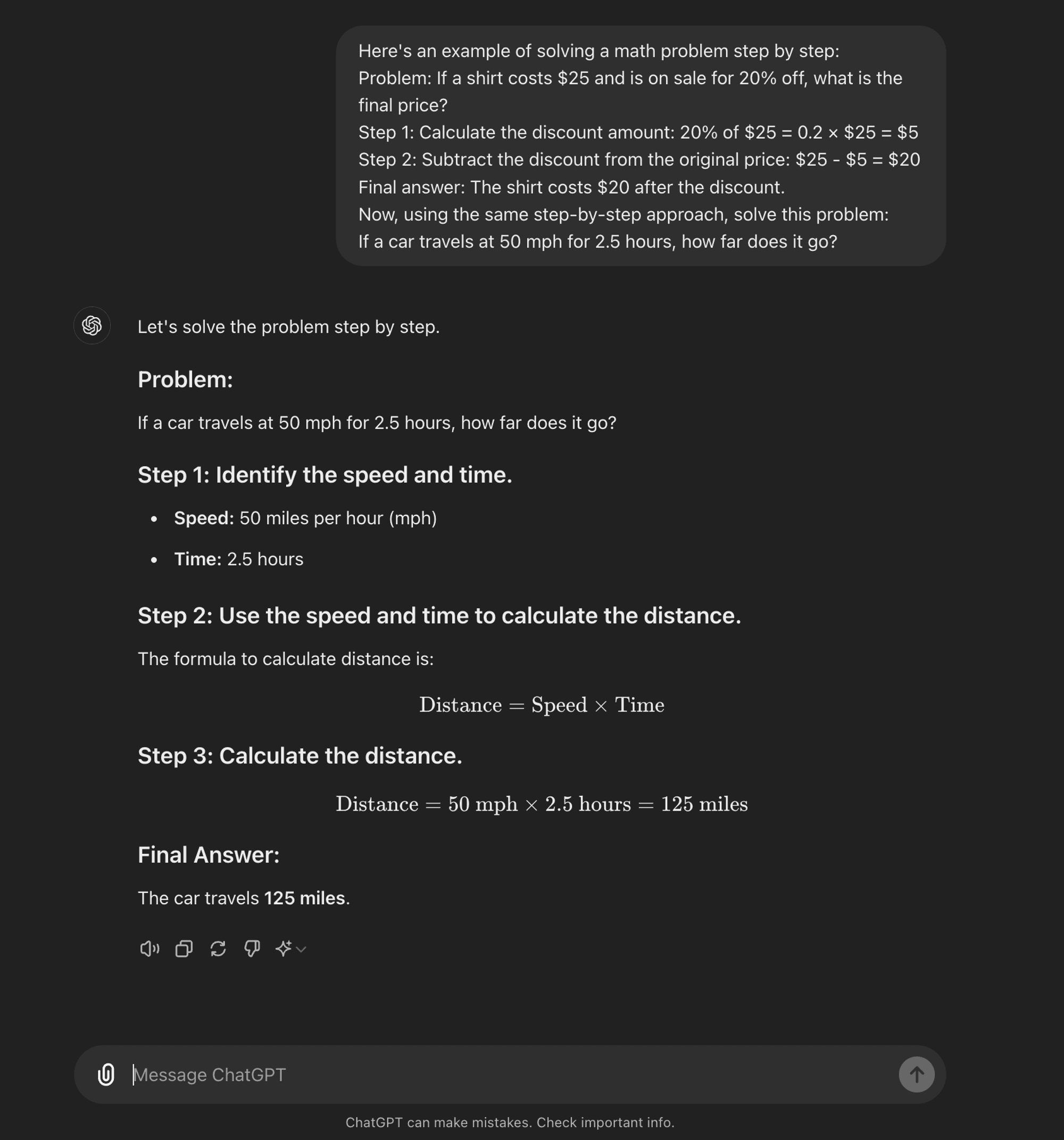
Few-shot CoT: 몇 샷 CoT는 모델에 원하는 추론 과정을 보여주는 소수의 예제를 제공하는 것입니다. 이러한 예제는 보이지 않는 새로운 문제를 해결할 때 모델이 따라야 할 템플릿 역할을 합니다.
Zero-shot CoT
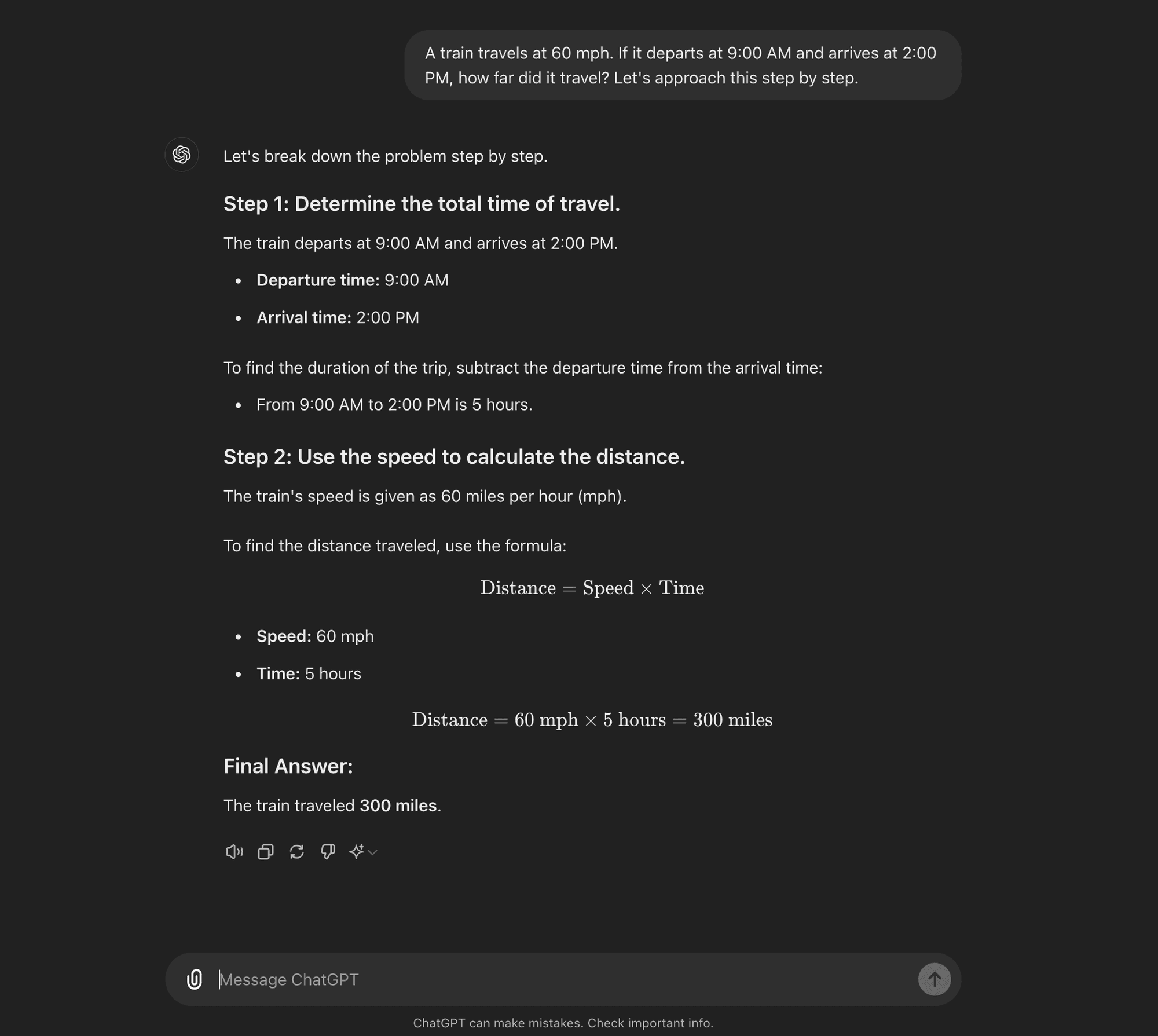
Few-shot CoT
AI Research Paper Breakdown: “Chain of Thoughtlessness?”
Now that you know what CoT prompting is, we can dive into some recent research that challenges some of its benefits and offers some insight into when it is actually useful.
The research paper, titled “Chain of Thoughtlessness? An Analysis of CoT in Planning,” provides a critical examination of CoT prompting’s effectiveness and generalizability. As AI practitioners, it’s crucial to understand these findings and their implications for developing AI applications that require sophisticated reasoning capabilities.

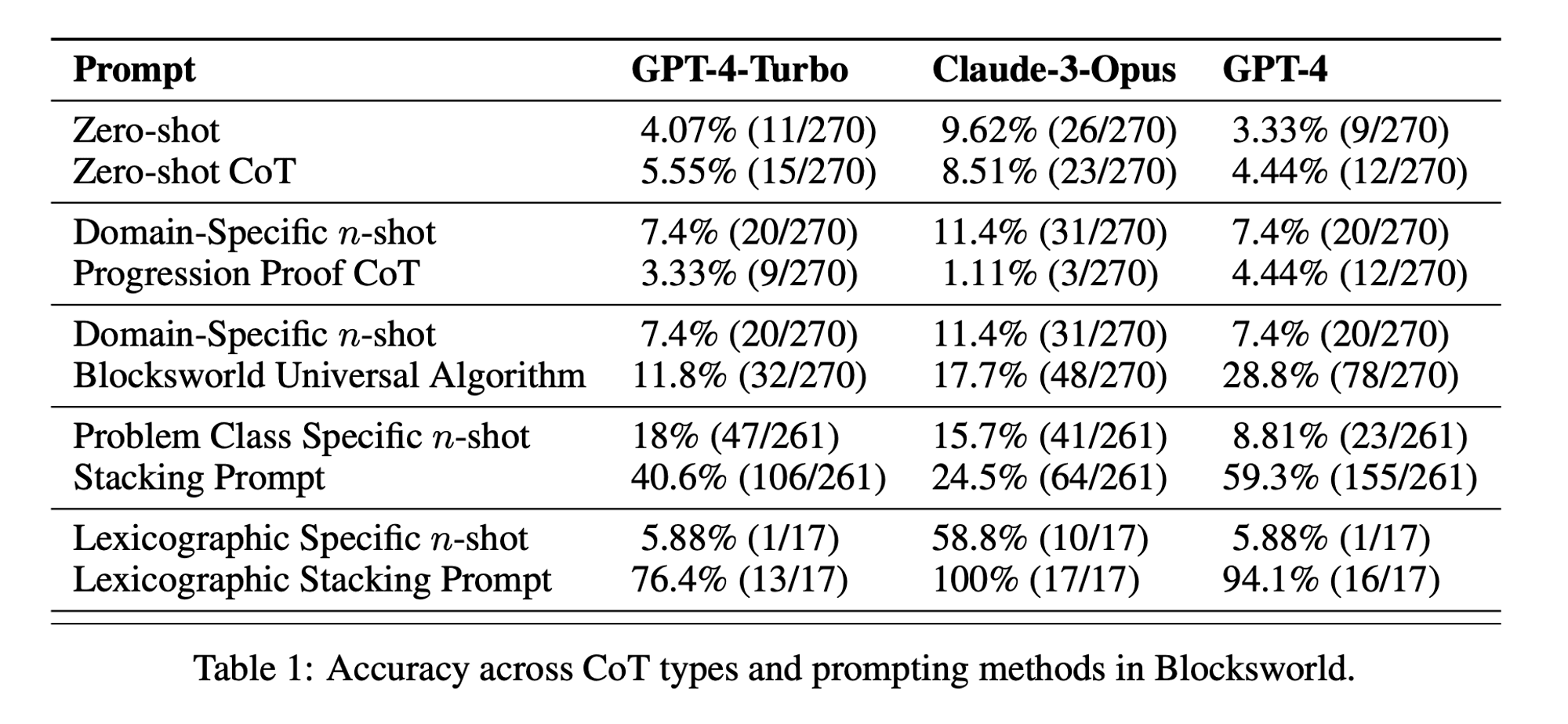
연구진은 블록스월드라는 고전적인 계획 영역을 주요 테스트 대상으로 선택했습니다. 블록스월드에서는 일련의 이동 동작을 사용하여 블록 집합을 초기 구성에서 목표 구성으로 재배치하는 작업을 수행합니다. 이 도메인은 추론 및 계획 능력을 테스트하는 데 이상적입니다:
다양한 복잡성을 가진 문제를 생성할 수 있습니다.
명확하고 알고리즘적으로 검증 가능한 솔루션을 제공합니다.
LLM 학습 데이터에 많이 나타나지 않을 가능성이 높습니다.
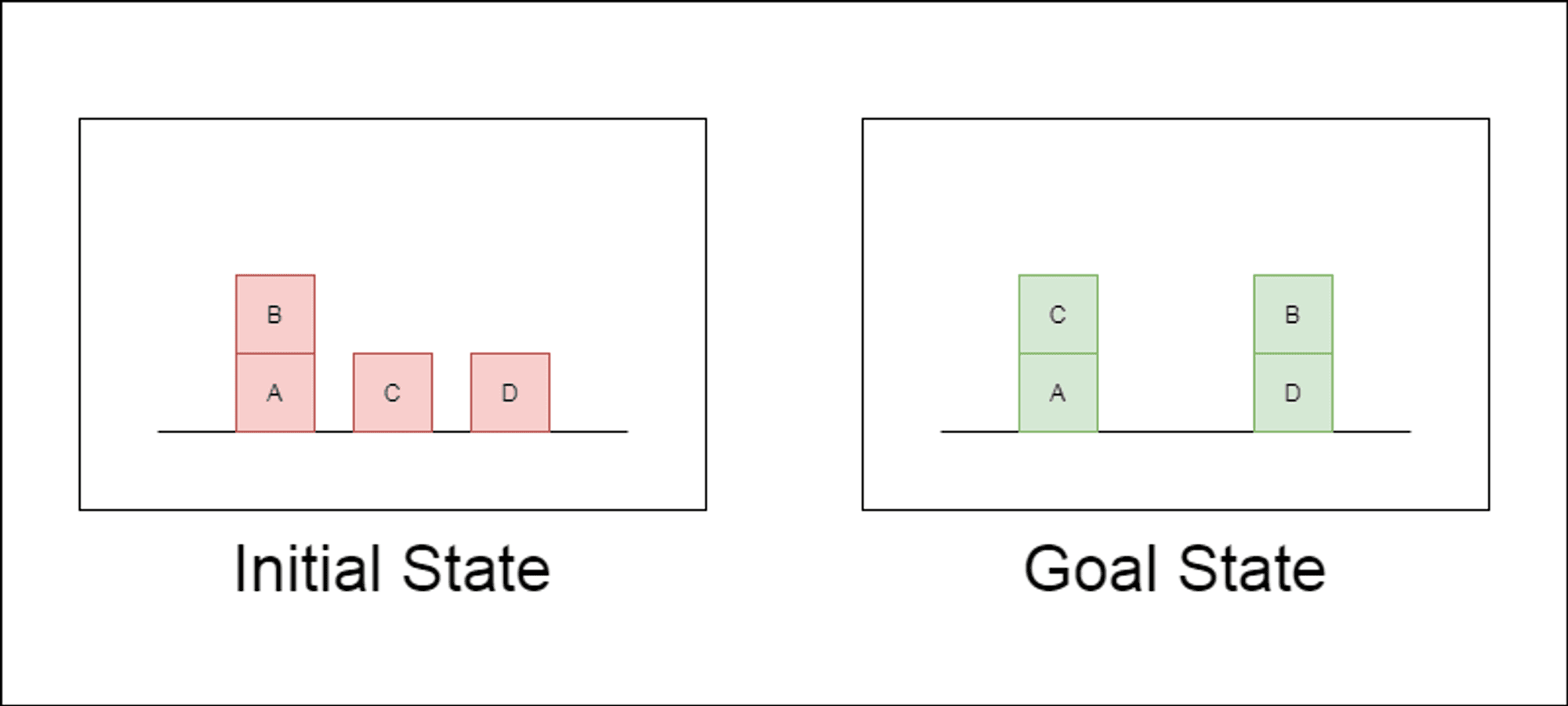
이 연구에서는 세 가지 최신 LLM을 조사했습니다: GPT-4, Claude-3-Opus, GPT-4-Turbo입니다. 이 모델들은 다양한 특이성을 가진 프롬프트를 사용하여 테스트되었습니다:
제로 샷 생각의 사슬 (유니버설): 프롬프트에 "단계별로 생각해 봅시다"를 추가하기만 하면 됩니다.
진행 증명(PDDL에만 해당): 계획의 정확성에 대한 일반적인 설명을 예시와 함께 제공합니다.
블록월드 범용 알고리즘: 블록월드 문제를 해결하기 위한 일반적인 알고리즘을 시연합니다.
스태킹 프롬프트: 블록월드 문제의 특정 하위 클래스(테이블에서 스택으로)에 집중합니다.
사전 스태킹: 목표 상태의 특정 구문 형식으로 범위를 더 좁힙니다.
연구진은 복잡성이 증가하는 문제에 대해 이러한 프롬프트를 테스트함으로써 LLM이 예시에서 보여준 추론을 얼마나 잘 일반화할 수 있는지 평가하고자 했습니다.
주요 조사 결과 공개
이 연구 결과는 CoT 프롬프트에 대한 많은 일반적인 가정에 도전합니다:
CoT의 제한적인 효과: 이전의 주장과는 달리, CoT 프롬프트는 제공된 예제가 쿼리 문제와 매우 유사한 경우에만 성능이 크게 향상되는 것으로 나타났습니다. 문제가 예제에 표시된 정확한 형식에서 벗어나는 순간 성능이 급격히 떨어졌습니다.
급격한 성능 저하: 문제의 복잡성(관련된 블록의 수로 측정)이 증가함에 따라 사용된 CoT 프롬프트에 관계없이 모든 모델의 정확도가 급격히 감소했습니다. 이는 LLM이 간단한 예제에서 보여준 추론을 더 복잡한 시나리오로 확장하는 데 어려움을 겪고 있음을 시사합니다.
일반 프롬프트의 비효율성: 놀랍게도 일반적인 CoT 프롬프트는 추론 예시가 없는 표준 프롬프트보다 성적이 더 떨어지는 경우가 많았습니다. 이는 CoT가 학습자가 일반화 가능한 문제 해결 전략을 학습하는 데 도움이 된다는 생각과 모순되는 결과입니다.
특이성 트레이드오프: 이 연구에 따르면 매우 구체적인 프롬프트는 높은 정확도를 달성할 수 있지만, 이는 매우 좁은 문제 집합에서만 가능합니다. 이는 성능 향상과 프롬프트의 적용 가능성 사이에 뚜렷한 상충 관계가 있음을 강조합니다.
진정한 알고리즘 학습의 부족: 이 결과는 LLM이 CoT 예제에서 일반적인 알고리즘 절차를 적용하는 방법을 학습하지 않는다는 것을 강력하게 시사합니다. 대신 패턴 매칭에 의존하는 것으로 보이며, 이는 새롭거나 더 복잡한 문제에 직면하면 빠르게 무너집니다.
이러한 연구 결과는 애플리케이션에서 CoT 프롬프트를 활용하고자 하는 AI 전문가와 기업에게 중요한 시사점을 줍니다. CoT가 특정 좁은 시나리오에서는 성능을 향상시킬 수 있지만, 많은 사람들이 기대했던 복잡한 추론 작업에는 만병통치약이 아닐 수 있음을 시사합니다.
AI 개발에 대한 시사점
이 연구 결과는 특히 복잡한 추론이나 계획 능력이 필요한 애플리케이션을 개발하는 기업에서 AI 개발에 중요한 영향을 미칩니다:
CoT 효과 재평가: AI developers should be cautious about relying on CoT for tasks that require true algorithmic thinking or generalization to novel scenarios.
현재 LLM의 한계: Alternative approaches may be necessary for applications requiring robust planning or multi-step problem-solving.
프롬프트 엔지니어링 비용: 매우 구체적인 CoT 프롬프트는 좁은 문제 세트에 대해 좋은 결과를 얻을 수 있지만, 특히 일반화 가능성이 제한적이라는 점을 고려하면 이러한 프롬프트를 만드는 데 필요한 인적 노력이 이점을 능가할 수 있습니다.
평가 지표 다시 생각하기: Relying solely on static test sets may overestimate a model’s true reasoning capabilities.
인식과 현실 사이의 간극: 이 연구에서 입증된 바와 같이, 대중적인 담론에서 의인화된 LLM의 인지된 추론 능력과 실제 능력 사이에는 상당한 차이가 있습니다.
Recommendations for AI Practitioners:
평가: Implement diverse testing frameworks to assess true generalization across problem complexities.
CoT Usage: Apply Chain-of-Thought prompting judiciously, recognizing its limitations in generalization.
Hybrid Solutions: Consider combining LLMs with traditional algorithms for complex reasoning tasks.
Transparency: Clearly communicate AI system limitations, especially for reasoning or planning tasks.
R&D Focus: Invest in research to enhance true reasoning capabilities of AI systems.
미세 조정: Consider domain-specific fine-tuning, but be aware of potential generalization limits.
For AI practitioners and enterprises, these findings highlight the importance of combining LLM strengths with specialized reasoning approaches, investing in domain-specific solutions where necessary, and maintaining transparency about AI system limitations. As we move forward, the AI community must focus on developing new architectures and training methods that can bridge the gap between pattern matching and true algorithmic reasoning.
10 Best Prompting Techniques for LLMs
This week, we also explore ten of the most powerful and common prompting techniques, offering insights into their applications and best practices.

Well-designed prompts can significantly enhance an LLM’s performance, enabling more accurate, relevant, and creative outputs. Whether you’re a seasoned AI developer or just starting with LLMs, these techniques will help you unlock the full potential of AI models.
Make sure to check out the full blog to learn more about each one.
시간을 내어 AI & YOU를 읽어주셔서 감사합니다!
인포그래픽, 통계, 방법 가이드, 기사, 동영상 등 엔터프라이즈 AI에 관한 더 많은 콘텐츠를 보려면 다음에서 Skim AI를 팔로우하세요. LinkedIn
AI 자문, 부분적인 AI 개발 또는 실사 서비스를 찾고 있는 창업자, CEO, 벤처 캐피털리스트 또는 투자자이신가요? 귀사의 AI 제품 전략 및 투자 기회에 대해 정보에 입각한 결정을 내리는 데 필요한 가이드를 받아보세요.
엔터프라이즈 AI 솔루션을 시작하는 데 도움이 필요하신가요? 유니티의 AI 워크포스 관리 플랫폼으로 나만의 AI 워커를 구축하고 싶으신가요? 상담 신청하기
유니티는 다음 산업 분야의 벤처 캐피탈 및 사모펀드 지원 기업을 위한 맞춤형 AI 솔루션을 구축합니다: 의료 기술, 뉴스/콘텐츠 집계, 영화 및 사진 제작, 교육 기술, 법률 기술, 핀테크 및 암호화폐.


