
生成的AIソリューションのための数ショットプロンプティングと微調整LLMの比較



大規模言語モデル(LLM)の真の可能性は、その膨大な知識ベースだけでなく、最小限の追加トレーニングで特定のタスクやドメインに適応する能力にある。そこで、数発プロンプトとファインチューニングの概念が登場し、実世界のシナリオでLLMのパワーを活用する方法を改善する。
LLMは広範な知識を網羅する膨大なデータセットで学習されるが、高度に専門化されたタスクやドメイン特有の専門用語に直面すると、しばしば苦戦を強いられる。従来の教師あり学習アプローチでは、これらのモデルを適応させるために大量のラベル付きデータが必要となるが、これは多くの実世界の状況では非現実的か不可能であることが多い。この課題により、研究者や実務家は、少数の例のみを用いてLLMを特定のユースケースに適合させる、より効率的な方法を模索している。
数発のプロンプティングと微調整の簡単な概要
この課題に対処するために、2つの強力なテクニックが存在する。数ショットプロンプトは、少数の例を含む巧妙な入力プロンプトを作成することで、追加トレーニングなしで特定のタスクを実行するようモデルを導く。一方、ファインチューニングでは、限られたタスク固有のデータを使用してモデルのパラメータを更新し、その膨大な知識を特定のドメインやアプリケーションに適応させる。
両アプローチは、数少ない例を用いてモデルが新しいタスクを学習したり、新しいドメインに適応したりすることを可能にするパラダイムである、数ショット学習の傘下にある。これらのテクニックを活用することで、LLMの性能と汎用性を劇的に向上させることができ、自然言語処理をはじめとする幅広いアプリケーションにおいて、より実用的で効果的なツールとなる。
フューショット・プロンプティングLLMの可能性を引き出す
スモールショット・プロンプトは、追加のトレーニングを必要とせずに、LLMを特定のタスクやドメインに誘導することができる強力なテクニックである。この方法は、LLMが本来持っている、指示を理解し従う能力を利用し、注意深く作られたプロンプトによってLLMを効果的に「プログラミング」する。
その核となるのは、少数(通常1~5)の例をLLMに与えることで、その例は望ましいタスクを示し、その後にモデルに応答を生成させたい新しい入力を与える。このアプローチは、モデルがパターンを認識する能力を活用し、与えられた例に基づいて動作を適応させることで、明示的に訓練されていないタスクを実行できるようにする。
数発プロンプトの主な原理は、入力と出力の明確なパターンをモデルに提示することで、新しい未知の入力に対して同様の推論を適用するように導くことができるというものだ。このテクニックは、LLMの文脈内学習能力を利用し、パラメータを更新することなく、新しいタスクに素早く適応することを可能にする。
数ショットのプロンプトの種類(ゼロショット、ワンショット、数ショット)
数発のプロンプトは、提供される例の数によって定義される、さまざまなアプローチを包含する:
ゼロショットのプロンプト: このシナリオでは、例題は提供されない。その代わり、モデルにはタスクの明確な指示や説明が与えられる。例えば、"次の英文をフランス語に翻訳してください:[入力テキスト]"。
一発プロンプト: ここでは、実際の入力の前に一つの例が提供される。これはモデルに、期待される入出力関係の具体的な例を与える。例えば「次のレビューのセンチメントをポジティブかネガティブかに分類しなさい。例:「この映画は素晴らしかった!」 - 肯定的な入力:「筋書きに耐えられなかった。- モデルは応答を生成する]"
数発のプロンプト: このアプローチでは、実際の入力の前に複数の例(通常2~5)を提供する。これにより、モデルはタスクのより複雑なパターンやニュアンスを認識することができる。例えば「次の文を質問か文に分類しなさい:空は青い。- 文『今何時ですか』 - 質問『私はアイスクリームが大好きです』。- 文の入力:'近くのレストランはどこにありますか' - [モデルが応答を生成する]"
効果的な数発プロンプトをデザインする
効果的なプロンプトを作成することは、芸術であると同時に科学でもあります。ここでは、いくつかの重要な原則を紹介します:
明快さと一貫性: 例や指示が明確で、一貫した形式に従っていることを確認しましょう。そうすることで、モデルがパターンを認識しやすくなります。
多様性: 複数の例を使用する場合は、モデルにタスクのより広い理解を与えるために、考えられる入力と出力の範囲をカバーするようにしてください。
関連性がある: 対象とする特定のタスクやドメインに密接に関連する例を選びます。こうすることで、モデルが知識の最も関連性の高い側面に集中できるようになります。
簡潔さ: 十分な文脈を提供することは重要ですが、モデルを混乱させたり、重要な情報を薄めたりするような、長すぎたり複雑すぎたりするプロンプトは避けてください。
実験: 繰り返しを恐れず、さまざまな実験をすること。 迅速 構造や例を見て、特定のユースケースに最適なものを見つけよう。
数発のプロンプトを使いこなすことで、LLMの潜在能力を最大限に引き出し、追加入力やトレーニングを最小限に抑えながら、さまざまなタスクに取り組ませることができる。
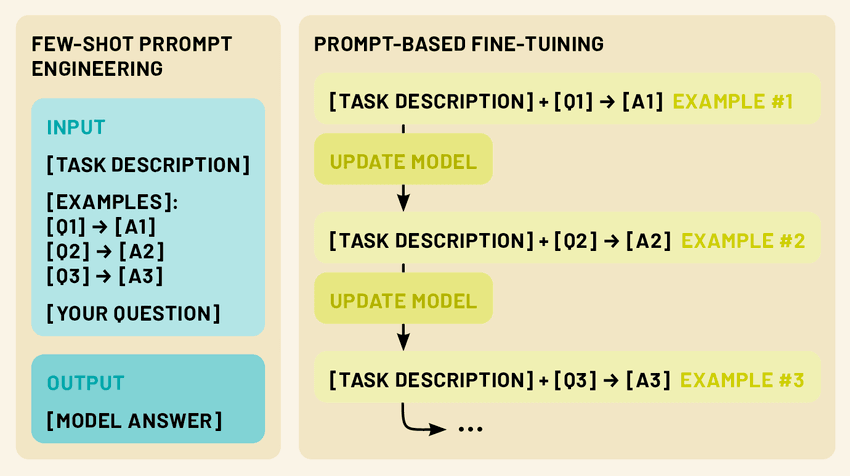
LLMの微調整:限られたデータでモデルを調整する
数ショットのプロンプトは、モデル自体に変更を加えることなく、LLMを新しいタスクに適応させるための強力なテクニックであるが、ファインチューニングは、特定のタスクやドメインでさらに優れたパフォーマンスを発揮するために、モデルのパラメータを更新する方法を提供する。ファインチューニングにより、事前に訓練されたLLMにエンコードされた膨大な知識を活用しながら、タスク固有のわずかなデータを使用して、特定のニーズに合わせてLLMを調整することができます。
LLMの文脈でファインチューニングを理解する
LLMのファインチューニングには、事前に訓練されたモデルを、タスクに特化したより小さなデータセットでさらに訓練することが含まれる。このプロセスにより、モデルは学習した表現をターゲットタスクやドメインのニュアンスに適応させることができる。ファインチューニングの主な利点は、事前に訓練されたモデルに既に存在する豊富な知識と言語理解に基づいて構築されるため、ゼロからモデルを訓練するよりもはるかに少ないデータと計算リソースで済むことである。
LLMの文脈では、微調整は通常、よりタスクに特化した特徴を担当するネットワークの上位層の重みを調整することに重点を置き、(より一般的な言語パターンを把握する)下位層はほとんど変更しない。このアプローチは、しばしば「転移学習」と呼ばれ、ターゲットタスクに特化した能力を発達させながら、モデルの幅広い言語理解を維持することを可能にする。
数ショットの微調整テクニック
数ショットファインチューニングは、ファインチューニングの概念をさらに一歩進め、非常に少数の例(通常、クラスまたはタスクごとに10~100サンプルの範囲)のみを使用してモデルの適合を試みる。このアプローチは、ターゲットタスクのラベル付きデータが少ないか、入手にコストがかかる場合に、特に有用である。少数サンプルによるファインチューニングの主なテクニックには、以下のようなものがある:
プロンプトベースの微調整: この方法は、数発プロンプトとパラメータ更新のアイデアを組み合わせたものである。モデルは、各例がプロンプトとコンプリーションのペアとしてフォーマットされた、数発プロンプトと同様の小さなデータセット上で微調整される。
メタ学習アプローチ: などのテクニックがある。 モデル無視メタ学習 (MAML) は、LLMの数ショット微調整に適応できる。これらの方法は、モデルが最小限のデータで新しいタスクに素早く適応できるような、良い初期化点を見つけることを目的としている。
アダプターベースの微調整: このアプローチでは、すべてのモデル・パラメーターを更新する代わりに、事前に訓練されたモデルのレイヤー間に小さな「アダプター」モジュールを導入する。これらのアダプターだけが新しいタスクで訓練され、訓練可能なパラメーターの数を減らし、壊滅的な忘却のリスクを減らす。
インコンテクスト学習: 最近のアプローチの中には、LLMを微調整して文脈内学習をよりうまく行うようにし、プロンプトだけで新しいタスクに適応する能力を高めようとするものがある。
数発のプロンプティングと微調整:正しいアプローチの選択
LLMを特定のタスクに適応させる場合、数発のプロンプトと微調整の両方が強力な解決策を提供する。しかし、それぞれの方法には長所と限界があり、適切なアプローチを選択するかどうかはさまざまな要因に左右される。
各手法の長所と限界
数発のプロンプティング長所
モデルのパラメータを更新する必要がなく、元のモデルを維持できる。
柔軟性が高く、その場で適応可能
追加のトレーニング時間や計算リソースは不要
迅速なプロトタイピングや実験に役立つ
制限事項:
特に複雑な作業では、パフォーマンスが安定しないことがある。
モデル本来の能力と知識による制限
専門性の高い領域や業務に苦戦する可能性がある
微調整:長所:
多くの場合、特定のタスクでより良いパフォーマンスを達成する
新しいドメインや専門的な語彙にモデルを適応させることができる
同じようなインプットでより一貫した結果
継続的な学習と改善の可能性
制限事項:
追加のトレーニング時間と計算リソースが必要
注意深く管理しなければ、大惨事を引き起こす危険性がある。
小さなデータセットではオーバーフィットする可能性がある
柔軟性に欠け、大幅なタスク変更には再トレーニングが必要
テクニックを選択する際に考慮すべき要素
テクニックを選択する際に考慮すべき要素がいくつかある:
データの入手可能性: 質の高い、タスクに特化したデータが少量しかない場合は、微調整の方が望ましいかもしれない。具体的なデータが非常に限られている、あるいは全くないタスクの場合は、数ショットのプロンプトの方が良い選択かもしれない。
タスクの複雑性:モデルの事前学習領域に近い単純なタスクは、数発のプロンプトでうまくいくかもしれない。より複雑なタスクや専門的なタスクは、微調整が有効な場合が多い。
リソースの制約: 利用可能な計算リソースと時間の制約を考慮する。一般的に、数ショットのプロンプトは、より速く、より少ないリソース消費です。
柔軟性の要件:様々なタスクに素早く対応する必要がある場合や、頻繁にアプローチを変更する必要がある場合は、数ショットプロンプトの方が柔軟性があります。
パフォーマンス要件: 高い精度と一貫性が要求されるアプリケーションでは、特にタスク固有のデータが十分にあれば、微調整の方が良い結果が得られることが多い。
プライバシーとセキュリティ: 機密データを扱う場合は、モデル更新のためにデータを共有する必要がないため、数ショットのプロンプトが望ましいかもしれない。
LLMのための数撃ちゃ当たるテクニックの実用化
数発学習技術は、様々な領域におけるLLMの幅広い応用を開拓し、これらのモデルが最小限の例で特定のタスクに素早く適応することを可能にしている。
自然言語処理タスク:
テキストの分類 フュースショットテクニックにより、LLMは1つのカテゴリーにつきわずかな例で、テキストをあらかじめ定義されたクラスに分類することができる。これはコンテンツタギング、スパム検出、トピックモデリングに有用である。
センチメント分析: LLMはドメイン固有のセンチメント分析タスクに素早く適応し、異なるコンテキストにおけるセンチメント表現のニュアンスを理解することができる。
名前付き固有表現認識(NER): 数ショット学習により、LLMは、科学文献中の化学化合物の識別など、特殊なドメインにおける名前付きエンティティの識別と分類が可能になる。
質問に答える: LLMは、特定の領域や形式の質問に答えるように調整することができ、顧客サービスや情報検索システムでの有用性を高める。
ドメイン固有の適応:
合法だ: 少数精鋭の技術により、LLMは最小限のドメイン固有の訓練で、法的文書を理解し、生成し、法的事例を分類し、契約書から関連情報を抽出することができる。
メディカルだ: LLMは、医療報告書の要約、症状からの疾患分類、少数の医療例のみを用いた薬物相互作用予測などのタスクに適応できる。
テクニカルだ: 工学やコンピュータ・サイエンスのような分野では、数発学習によって、LLMは専門的な技術コンテンツを理解し、生成し、コードをデバッグし、ドメイン固有の用語を使って複雑な概念を説明することができる。
多言語およびクロスリンガルアプリケーション:
低リソース言語翻訳:スモールショット技術は、利用可能なデータが限られている言語の翻訳タスクをLLMが実行するのに役立つ。
クロスリンガル移籍: 高リソース言語で訓練されたモデルは、少数ショット学習を使って低リソース言語のタスクに適応させることができる。
多言語タスク適応: LLMは、各言語でいくつかの例を挙げるだけで、複数の言語間で同じタスクを実行できるように素早く適応することができる。
スモールショット・テクニックの課題と限界
LLMのための数発技術は非常に大きな可能性を秘めているが、同時にいくつかの課題や限界もあり、それに対処する必要がある。
一貫性と信頼性の問題:
パフォーマンスのばらつき: 特に複雑なタスクやエッジケースの場合、少ないショット数で一貫性のない結果が出ることがある。
敏速な感受性: プロンプトの文言や例題の選択を少し変えるだけで、アウトプットの質が大きく変わることがある。
タスク固有の制限: タスクによっては、ほんの数個の例から学習することが本質的に難しく、パフォーマンスが最適化されない場合がある。
倫理的配慮と偏見:
バイアスの増幅: 少数ショット学習は、提供された限られた例に存在するバイアスを増幅し、不公平または差別的な出力につながる可能性がある。
堅牢性に欠ける: 数発のテクニックで適応されたモデルは、敵対的な攻撃や予期せぬ入力に対してより弱いかもしれない。
透明性と説明可能性: 数ショットのシナリオで、モデルがどのように結論に達するかを理解し、説明するのは難しいかもしれない。
計算資源と効率:
モデルサイズの制限: LLMが大きくなるにつれて、微調整に必要な計算量はますます大きくなり、利用しにくくなる可能性がある。
推論時間: 複雑なスモールショットプロンプトは推論時間を増加させ、リアルタイムアプリケーションに影響を与える可能性がある。
エネルギー消費: 数ショットの技術を大規模に展開するために必要な計算資源は、エネルギー効率と環境への影響に懸念を抱かせる。
これらの課題と限界に対処することは、LLMにおける少数ショット学習技術の継続的な発展と責任ある展開にとって極めて重要である。研究が進むにつれて、この強力な手法の信頼性、公平性、効率性を高める革新的なソリューションが登場することが期待される。
結論
数発のプロンプトと微調整は画期的なアプローチであり、LLMが最小限のデータで特殊なタスクに迅速に適応することを可能にする。私たちが探求してきたように、これらのテクニックは、自然言語処理タスクの強化から、ヘルスケア、法律、テクノロジーなどの分野でのドメイン固有の適応の実現まで、LLMを業界全体の多様なアプリケーションに調整する上で、これまでにない柔軟性と効率性を提供する。
特に一貫性、倫理的配慮、計算効率の面で課題が残るものの、LLMにおける数発学習の可能性は否定できない。研究が進み、現在の限界に対処し、新たな最適化戦略が発見されれば、この技術がさらに強力で多用途に応用されることが予想される。AIの未来は、より大きなモデルだけでなく、より賢く、より適応性の高いモデルにある。そして数発学習は、私たちの進化し続けるニーズを真に理解し、それに応えることのできる、知的で効率的、高度に専門化された言語モデルの新時代への道を開きつつある。


