
LangChain導入の失敗と課題トップ5



ラングチェーン言語モデルを利用したアプリケーションを構築するための人気のフレームワークである「言語モデル」は、AIコミュニティで大きな支持を集めている。複雑な自然言語処理システムの作成を簡素化するというその約束は、開発者や企業を魅了しています。しかし、どんな新しい技術でもそうであるように、LangChainの成功した実装と使用を妨げる、よくある間違いや課題があります。
このブログでは、LangChainの失敗と課題のトップ5を紹介し、これらの落とし穴を回避し、この強力なフレームワークを最大限に活用するためのヒントを提供します。
間違い#1:アーキテクチャを複雑にしすぎる
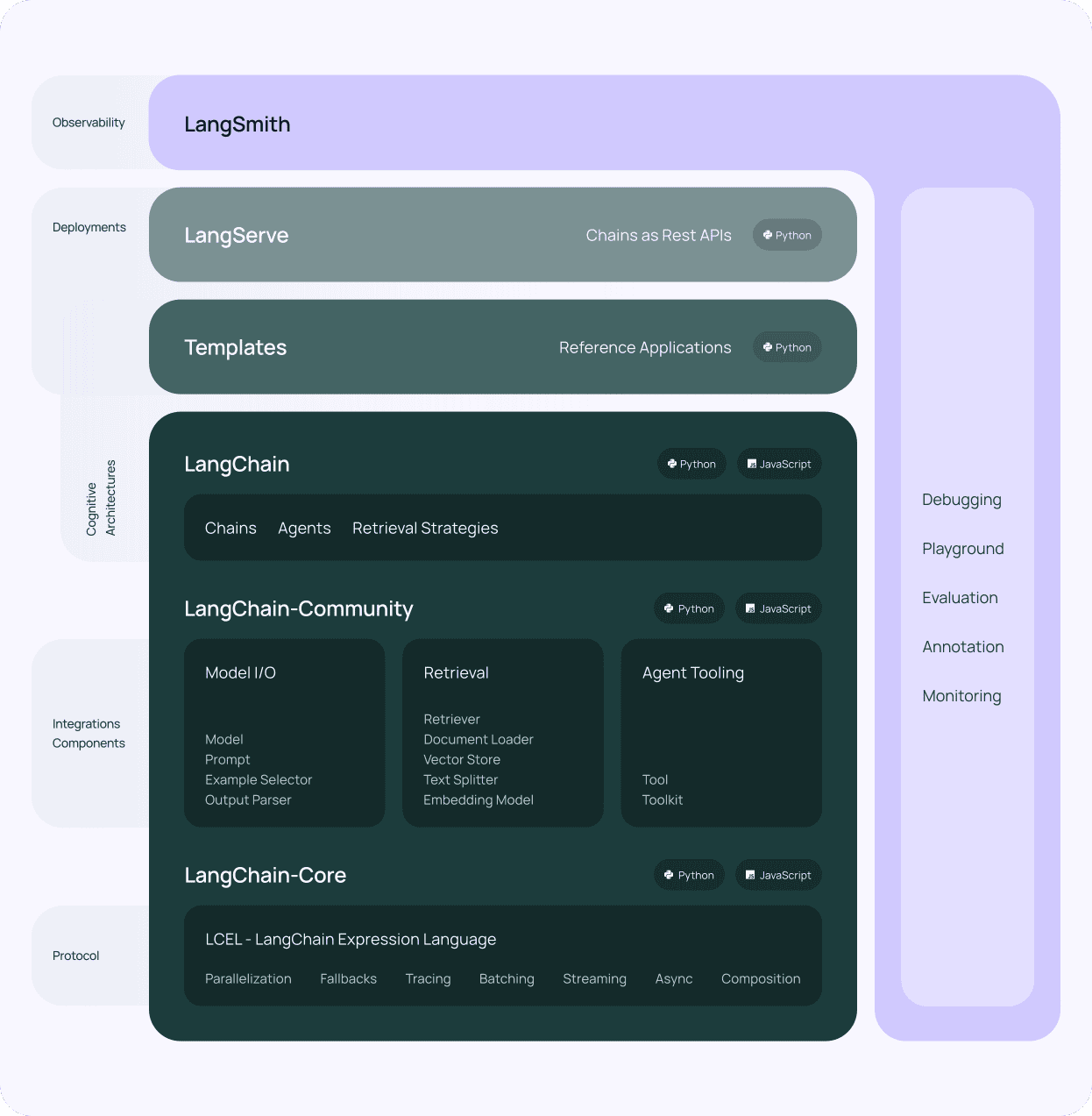
LangChainを使用する際によくある間違いの一つは、アーキテクチャを複雑にしすぎることです。LangChainのデザインは、抽象化された基盤の上に構築されています。 チェーン, 代理店そして 工具 インタフェースの抽象化である。これらの抽象化は、柔軟性と再利用性を提供することを目的としているが、適切に使用しなければ不必要な複雑さにつながる可能性もある。
例えば、LangChainのクラス階層は非常に深く、複数レベルの継承が可能です。例えばAgentのクラス階層には 代理店, エージェントエグゼキューター, ゼロショット・エージェントそして 会話エージェントなどがある。この抽象化レベルでは、開発者がエージェントを適切に初期化する方法や、カスタマイズのためにどのメソッドをオーバーライドすべきかを理解することが難しくなります。
また、チェーンやエージェントのライフサイクルにフックするためのCallbackインターフェースの使用も、複雑になりすぎる可能性のある例です。ドキュメントでは、以下のような様々なコールバックメソッドについて明確に説明されていません。 オン・チェーン・スタート, オンツールスターそして on_agent_actionそしてそれらがいつ呼び出されるのか。このような明確性の欠如は、カスタムのロギング、モニタリング、状態管理を実装する際の混乱や困難につながる可能性がある。
複雑すぎるアーキテクチャの影響は大きい。開発者は、自分たちの特定のニーズに合わせてフレームワークを変更する方法を理解するのに苦労するため、カスタマイズの努力を妨げる可能性がある。抽象化された複数のレイヤーを通して問題をトレースするのは時間がかかり、フラストレーションがたまるため、デバッグはより困難になる。さらに、複雑なコードは理解しにくく、更新しにくく、時間の経過とともに拡張しにくくなるため、保守性が損なわれる。
間違い#2:文書や例を軽視している
LangChainを使うときによくあるもう一つの間違いは、明確で包括的なドキュメントの重要性を軽視することです。LangChainのドキュメントは充実していますが、開発者がフレームワークの機能とベストプラクティスを完全に把握するために必要な明確さと深さに欠けていることがよくあります。
LangChainのドキュメントの欠点は、主要な概念、デフォルトパラメータ、様々なコンポーネントの期待される入出力について詳細な説明がないことです。開発者はしばしば、ある機能の効果的な使い方を理解するために、ソースコードを探し回ったり、試行錯誤に頼ったりすることになります。
さらに、ドキュメントで提供されている使用例は、単純すぎることが多く、実際のユースケースを紹介できていない。このような例は、ユーザーが使い始める手助けにはなるが、実用的なアプリケーションで遭遇する複雑さやニュアンスの違いに対する準備としては不十分だ。
ドキュメントやサンプルを軽視した結果は重大です。LangChainを初めて使う開発者は、フレームワークの効果的な使い方を理解するのに苦労し、フラストレーションと時間の浪費につながります。経験豊富なユーザでさえ、より明確なドキュメントがあれば簡単に対処できたはずの特定の機能の実装方法や問題のトラブルシューティングに膨大な時間を費やすことになります。
多様な実例がなければ、開発者はLangChainプロジェクトを向上させる貴重な洞察やベストプラクティスを逃してしまうかもしれません。既存のパターンやアプローチに気づかなかったばかりに、うっかり車輪の再発明をしたり、最適とは言えない設計上の決断をしてしまうかもしれません。
間違い#3:矛盾や隠れた行動を見過ごす
LangChainを使うときに開発者が犯しがちな3つ目の間違いは、フレームワーク内の矛盾や隠れた動作を見落としてしまうことです。LangChainのコンポーネントは時に、明確に文書化されていない予期せぬ動作や一貫性のない動作をすることがあり、混乱や潜在的なバグを引き起こします。
例えば 会話バッファメモリ コンポーネントを使用するかどうかによって異なる場合がある。 カンバセーションチェーン または エージェントエグゼキューター.ConversationChainの場合、ConversationBufferMemoryは自動的にAIの応答をメモリに追加するが、AgentExecutorの場合は追加しない。このような矛盾は、明示的に文書化されていない場合、誤った仮定や誤った実装につながる可能性があります。
隠された動作のもう一つの例は、ある特定のチェーン、例えば LLMMathChainLLMMathChainは、他のチェーンと比較して、入力パラメータに異なるフォーマットを使用しています。LLMMathChainは、入力の辞書を期待する代わりに、単一の "question "パラメータを期待する。このような入力形式の不一致は、入力パラメータを構成することを困難にします。 統合 異なるチェーンをシームレスにつなぐ。
矛盾や隠れた動作を見落とすことの影響は大きい。開発者は、コンポーネントの動作に関する誤った仮定に起因する問題のデバッグに何時間も費やすかもしれない。フレームワークの異なる部分間で動作や入力フォーマットに一貫性がないため、データの流れを推論し、堅牢なアプリケーションを構築することが難しくなります。
さらに、隠れた動作は微妙なバグにつながる可能性があり、開発時には気づかなかったが、本番環境では表面化し、予期せぬ障害や不正な出力を引き起こすことがある。このような問題の特定と修正には時間がかかり、フレームワークの内部に関する深い知識が必要になります。
間違い#4:統合の課題を過小評価する
LangChainを使う際によくあるもう一つの間違いは、既存のコードベースやツール、ワークフローとフレームワークを統合する際の課題を過小評価することです。LangChainの独断的なデザインと、メソッドチェイニングやコールバックのような特定のパターンへの依存は、確立された開発環境に組み込もうとするときに摩擦を生む可能性があります。
例えば、LangChainを次のようなウェブフレームワークと統合する。 ファストAPI 異なるタイプのリクエスト、レスポンス、例外を変換する必要があるかもしれません。開発者はLangChainの入出力をウェブフレームワークの規約に注意深くマッピングしなければなりません。
同様に、LangChainをデータベースやメッセージキューと統合する場合、開発者はLangChainオブジェクトのシリアライズとデシリアライズを行う必要があります。フレームワークが特定のデザイン・パターンに依存しているため、既存のインフラストラクチャのベスト・プラクティスや要件と必ずしも一致しない場合があります。
LangChainのグローバルステートとシングルトンの使用は、コンカレント環境や分散環境でも問題を引き起こす可能性があります。依存関係の適切なスコープとインジェクションは、回避策やフレームワークのデフォルト動作への変更を必要とし、統合プロセスに複雑さを加えます。
統合の課題を過小評価することの結果は重大である。開発者は、統合タスクに予想以上の時間を費やし、プロジェクトのスケジュールを遅らせ、開発コストを増加させることに気づくかもしれない。また、統合の複雑さが増すと、バグが発生したり、保守性の問題が生じたりする可能性がある。
さらに、統合の課題によって引き起こされる摩擦は、一部の開発者にLangChainを完全に放棄させ、既存の技術スタックやワークフローとの互換性がより高い代替ソリューションを選択させるかもしれません。これは、LangChainの強力な機能を活用する機会を逃し、潜在的に最適でない実装につながる可能性があります。
間違い#5:パフォーマンスと信頼性の考慮を無視する
LangChainを使うときに開発者が犯しがちな5つ目の過ちは、パフォーマンスと信頼性を無視することです。LangChainは言語モデルを使ったアプリケーションを構築するための強力なツール群を提供しますが、これらのアプリケーションを本番ユースケースに最適化するには、パフォーマンスと信頼性の要素に注意深く注意を払う必要があります。
LangChainアプリケーションを最適化する際の課題の一つは、フレームワークのアーキテクチャが本質的に複雑であることです。抽象化された複数のレイヤと、言語入出力の処理に関わる多数のコンポーネントがあるため、パフォーマンスのボトルネックや非効率性を特定することが難しい場合があります。開発者は、アプリケーションを効果的にプロファイリングし最適化するために、フレームワークの内部を深く理解する必要があるかもしれません。
もう一つの問題は、LangChainのデフォルト設定が必ずしも本番環境に適していないことです。フレームワークのデフォルト設定は、パフォーマンスやコスト効率よりも使いやすさや柔軟性を優先しているかもしれません。例えば、キャッシュ、トークンの使用、API呼び出しのデフォルト設定は、レイテンシやコストに対して最適化されていない可能性があり、実際のシナリオでは最適なパフォーマンスとは言えません。
パフォーマンスと信頼性を無視すると、重大な結果を招きかねません。LangChainで構築されたアプリケーションは、遅いレスポンスタイム、高いレイテンシ、運用コストの増加に悩まされるかもしれません。ミッションクリティカルなアプリケーションやユーザが利用するアプリケーションでは、パフォーマンスの低下はユーザエクスペリエンスの低下やユーザの信頼喪失につながります。
さらに、LangChainアプリケーションが本番環境で適切にテスト・監視されない場合、信頼性の問題が発生する可能性があります。予期せぬ障害、タイムアウト、リソースの制約により、アプリケーションが応答しなくなったり、正しくない出力を出すことがあります。このような問題のデバッグとトラブルシューティングは、フレームワークと基礎となるインフラストラクチャの深い知識を必要とし、困難な場合があります。
これらのリスクを軽減するために、開発者はLangChainアプリケーションを構築する際に、パフォーマンスと信頼性の要素を積極的に考慮する必要があります。これには、異なるコンフィギュレーションオプションのパフォーマンスへの影響を慎重に評価すること、徹底的なパフォーマンステストを実施すること、運用中のアプリケーションを監視して問題を迅速に特定し対処することなどが含まれます。
スキムAIでLangChainのミスと課題を克服する
このブログポストでは、LangChainの強力なフレームワークを使う際に、開発者や企業が陥りがちな失敗や課題のトップ5を紹介します。アーキテクチャの複雑化やドキュメントの軽視から、不整合の見落としや統合の課題の過小評価まで、これらの間違いはLangChain実装の成功を大きく妨げます。さらに、パフォーマンスと信頼性を無視すると、最適な結果を得られず、本番環境で失敗することさえあります。
しかし、これらの課題は克服できないものではないことを認識することが重要です。これらの課題に積極的に取り組み、専門家の指導を仰ぐことで、企業はLangChainに関連するハードルを克服し、アプリケーションのためにこのフレームワークの可能性を最大限に引き出すことができます。LangChainを利用することで、企業はAIへの取り組みにおいて価値とイノベーションを促進する、高性能で保守可能な信頼性の高いソリューションを構築することができます。


