
LLMアプリにベクターデータベースを活用する方法 - AI&YOU #54



今週のスタッツ/ファクト 今週の統計/事実今後3年間で、45.9%の企業がAIとMLアプリケーションの拡張を優先することを目標としている。次期会計年度には、56.8%がAI/ML投資による2桁の収益増加を見込んでおり、さらに37%が次のように見込んでいる。
LLMがより洗練され、要求が厳しくなるにつれ、企業はこれらのモデルの学習と運用に必要な膨大な量のデータを効率的に保存・検索するという課題に直面している。ベクトル・データベースは、LLMの可能性を最大限に引き出す鍵です。 企業におけるLLM AIの応用。
今週のAI&YOUでは、私たちが発表した3つのブログからの洞察を紹介します:
LLMアプリケーションにベクターデータベースを使用する方法 - AI&YOU #54
ベクトルデータベースは、高次元のベクトルデータを格納・管理するために設計された特殊なデータベースである。データを行と列として格納する従来のデータベースとは異なり、ベクトルデータベースはデータをベクトル空間の数値ベクトルとして表現します。
テキスト文書や画像などの各データポイントは、ベクトル埋め込みに変換される。ベクトル埋め込みとは、データの意味的な意味を捉える、高密度で固定長の数値表現である。
ベクターデータベースの仕組み
ベクトルデータベースの中核には、ベクトル埋め込みとベクトル空間の概念がある。ベクトル埋め込みは、word2vecやBERTのような機械学習モデルを用いて生成され、データ点を高次元ベクトル空間にマッピングすることを学習する。このベクトル空間では、類似のデータ点は互いに近いベクトルで表現され、非類似のデータ点は離れて表現されます。
ベクトルデータベースは、効率的な類似検索や最近傍検索を可能にする。クエリベクトルが提供されると、データベースはコサイン類似度やユークリッド距離のような距離メトリックを使用して、ベクトル空間内で最も類似したベクトルを素早く見つけることができる。これにより、キーワードの完全一致ではなく、意味的類似性に基づく関連データの高速かつ正確な検索が可能になります。
LLMアプリケーションにベクトルデータベースを使用する利点
ベクターデータベースは、LLMアプリケーションをサポートする上で、従来のデータベースと比較していくつかの重要な利点がある:
意味検索: ベクターデータベースはセマンティック検索を可能にし、LLMがキーワードの完全一致に頼るのではなく、クエリの意味や文脈に基づいて情報を検索できるようにする。
スケーラビリティ: ベクターデータベースは、大規模なベクターデータを効率的に扱うように設計されている。数百万から数十億の高次元ベクトルを格納し、処理することができます。
クエリー時間の短縮 ベクトル・データベースで使用される特殊な索引付けと検索アルゴリズムは、大規模なデータセットでも高速なクエリを可能にする。
精度の向上: ベクトル埋め込みに取り込まれた意味情報を活用することで、ベクトルデータベースはLLMがユーザーのクエリに対してより正確で文脈に関連した応答を提供するのに役立つ。
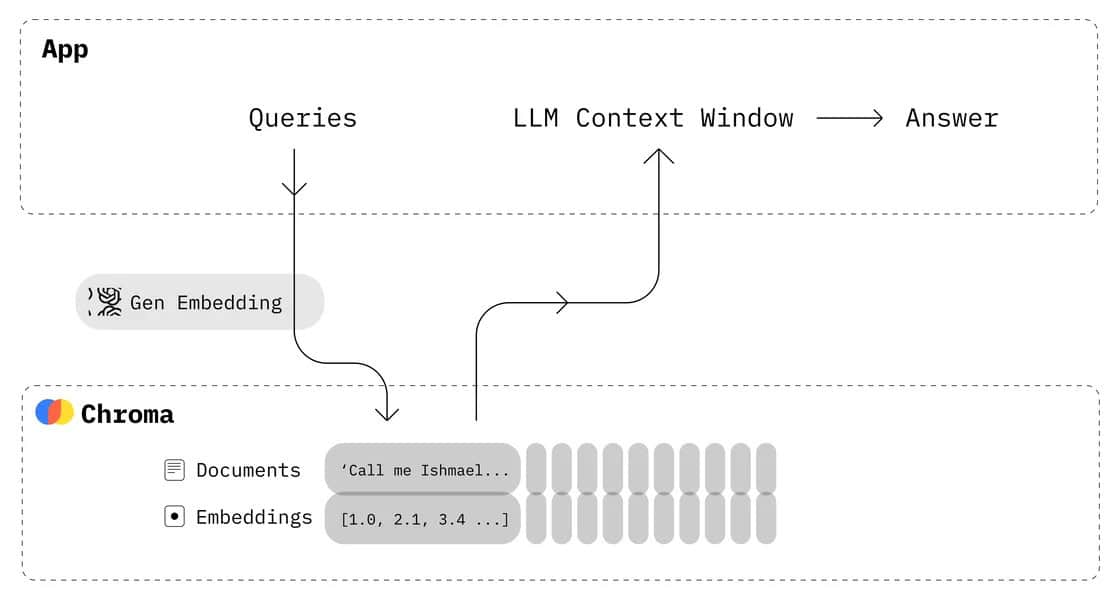
LLMとベクトル・データベース:エンタープライズAIに最適な組み合わせ
LLMの成功は、学習対象となるデータの質とアクセス性に大きく依存している。ベクターデータベースは、LLMが必要とする膨大な量のデータを保存・検索するための強力なソリューションを提供します。
LLMは何十億もの単語を含む膨大なデータセットで学習されるため、言語の複雑さを学習し、文脈と意味を深く理解することができます。一度事前訓練されたLLMは、特定のユースケースや業種に適応させるために、ドメイン固有のデータで微調整することができます。このデータの質と関連性は、エンタープライズAIアプリケーションにおけるLLMの性能と精度に直接影響します。
LLMデータの保存と検索に従来のデータベースを使用することの課題
リレーショナル・データベースのような従来のデータベースは、LLMが必要とする非構造化・高次元データの処理には適していない。これらのデータベースは、以下のような課題を抱えている:
スケーラビリティ: 従来のデータベースは、大規模なデータセットを扱う際に性能上の問題に直面することが多く、LLMの訓練や運用に必要な膨大な量のデータを保存・検索することが困難であった。
非効率的な検索:従来のデータベースにおけるキーワードベースの検索では、データの意味や文脈を捉えることができず、LLMがクエリを実行した場合、関連性のない、あるいは不完全な結果となってしまう。
柔軟性に欠ける: 従来のデータベースの硬直したスキーマは、LLMに関連する多様で進化するデータタイプや構造に対応することを困難にしている。
ベクターデータベースはどのようにこれらの課題を克服するか
ベクターデータベースは、LLMをサポートするという点で、従来のデータベースの限界に対処するために特別に設計されている:
コンテキストを考慮したデータ検索のための効率的な類似性検索: データを高次元空間のベクトルとして表現することで、ベクトルデータベースは高速かつ正確な類似性検索を可能にする。LLMはクエリの意味に基づいて関連情報を検索することができ、より文脈に適した応答を保証する。
大規模なデータセットを扱うためのスケーラビリティ: ベクターデータベースは、大量のベクターデータを効率的に扱うために構築されている。複数のマシンにまたがって水平方向に拡張できるため、LLMが必要とする何十億ものベクトル埋め込みデータの保存と処理が可能です。
LLMアプリケーションにおけるベクトル・データベースの使用例を特定する
ベクター・データベースを導入する前に、それが企業のAIアプリケーションに最も価値を提供できる具体的なユースケースを特定することが極めて重要だ。
意味検索と情報検索 は、ベクトル・データベースが得意とする分野のひとつである。文書、画像、その他のデータをベクトルとして表現することで、LLMは自然言語クエリを使用して最も意味的に類似した結果を取得し、検索出力の精度と関連性を向上させることができます。
検索拡張世代、または ラグ, LLMがベクトルデータベースと統合することで、より正確で文脈に関連した応答を生成できる。生成プロセスにおいて、LLMは入力クエリに基づいてベクトル・データベースから関連情報を検索し、生成テキストの一貫性と事実の正確性を高める。
パーソナライゼーションと推薦システム もベクトルデータベースから大きな恩恵を受けることができる。ユーザーの嗜好、行動、アイテムの特徴をベクトルとして表現することで、LLMはユーザーとアイテムのベクトル間の類似性を計算することで、高度にターゲット化されたレコメンデーションやユーザー固有のアウトプットを生成することができる。
ベクター・データベースは次のような用途にも使用できる。 ナレッジ・マネジメントとコンテンツ組織.企業はベクトル・データベースを活用して大量の非構造化データを整理・管理し、類似したベクトル同士をクラスタリングすることでコンテンツを自動的に分類・タグ付けし、発見とナビゲーションを容易にすることができる。
ニーズに合ったベクターデータベースの選択
エンタープライズAIアプリケーションの成功には、適切なベクターデータベースを選択することが重要です。さまざまなベクターデータベースのソリューションを評価する際には、オープンソースとプロプライエタリのオプションのトレードオフを考慮してください。
オープンソースのベクターデータベースは、柔軟性、カスタマイズ性、費用対効果が高く、活発なコミュニティ、定期的なアップデート、豊富なドキュメントを備えている。一方、プロプライエタリなソリューションは、クラウドプラットフォームや専門ベンダーによって提供されることが多く、マネージドサービス、エンタープライズグレードのサポート、エコシステム内の他のツールとのシームレスな統合を提供しますが、高いコストとベンダーロックインのリスクを伴う場合があります。
スケーラビリティ、パフォーマンス、統合の容易さは、ベクトルデータベースを選択する際に評価すべき重要な要素です。ストレージ容量とクエリ性能の両面で、データベースのデータ規模を処理する能力を評価し、大規模データセットでの類似性検索を大幅に高速化できる近似最近傍(ANN)検索など、データベースのインデックス作成と検索アルゴリズムを検討します。
ベクターデータベースが、LLMフレームワーク、データパイプライン、ダウンストリームアプリケーションなど、既存のテクノロジースタックとどの程度統合されているかを調査し、タイムリーなヘルプ、バグ修正、機能アップデートを確実に利用できるよう、活発なコミュニティ、包括的なドキュメント、迅速なサポートチャネルを持つデータベースを優先する。

ベクターデータベースをLLMアプリケーションに統合するためのベストプラクティス
エンタープライズAIアプリケーションにベクターデータベースをスムーズかつ効果的に導入するためには、いくつかのベストプラクティスに従う必要がある。
まず、次のことを行う。 堅牢なデータ前処理パイプライン を使用して、生データをクリーニング、正規化し、ベクトル埋め込み生成に適した形式に変換します。さまざまな埋め込みモデルや埋め込みテクニックを試して、特定のユースケースやデータタイプに最も適したアプローチを見つけ、ドメイン固有のデータで事前に訓練された埋め込みモデルを微調整して、企業のコンテキスト内の固有のセマンティクスや関係をキャプチャします。
実施 データ品質チェックと検証ステップ ベクトル埋込みの一貫性と信頼性を保証します。
クエリの最適化とパフォーマンス・チューニング は、ベクトルデータベースを効率的に使用するために不可欠です。ベクトルデータベースのインデックス作成と検索パラメータを微調整して、クエリの速度と精度のバランスを取り、次元削減、量子化手法、キャッシュ機構などのテクニックを採用して、ベクトルの保存と検索を最適化します。
を設立する。 総合監視システム ベクトルデータベースのパフォーマンス、可用性、健全性を追跡し、ベクトルデータの完全性と鮮度を確保するために定期的なメンテナンスタスクを実行します。
セキュリティとアクセス・コントロール は、機密性の高い企業データを扱う場合に最も重要です。機密情報を保護するために、暗号化、認証、アクセス制御メカニズムなどの強固なセキュリティ対策を導入し、不正アクセスの試みや不審な行動を検出・防止するために、アクセスログを定期的に監査・確認する。
を育てる コラボレーションと知識共有の文化 ベクターデータベースとLLMアプリケーションに関するベストプラクティス、学んだ教訓、革新的なアイデアの交換を奨励します。
これらのベストプラクティスに従い、企業独自の要件を考慮することで、ベクターデータベースの導入を成功させ、LLMアプリケーションの可能性を最大限に引き出すことができます。
ベクターデータベースによる検索拡張世代(RAG)の実現
エンタープライズAIにおけるベクトル・データベースの最もエキサイティングなアプリケーションの一つは、検索拡張生成を可能にする能力である。RAGは、大規模な言語モデルとベクトル検索のパワーを組み合わせ、文脈に関連した正確な応答を生成する。
企業環境では、RAGは、ユーザーのクエリを理解し、驚くほどの精度で応答できるインテリジェントなチャットボットやバーチャルアシスタントを構築するために使用することができます。ベクターデータベースを活用して関連情報を保存・検索することで、LLMは会話の特定のコンテキストに合わせた人間のような応答を生成することができます。
例えば、金融機関はRAGを搭載したチャットボットを導入することで、顧客にパーソナライズされた投資アドバイスを提供することができる。ベクター・データベースをLLMと統合することで、チャットボットは顧客の財務目標、リスク許容度、投資嗜好を理解し、データベースから取得した最も関連性の高い情報に基づいてオーダーメイドの推奨事項を生成することができる。
エンタープライズAIのスケーラビリティ、導入、ROIへの影響
ベクターデータベース技術の進歩と他のAIイノベーションとの統合は、企業のAI導入、スケーラビリティ、およびAIに大きな影響を与えている。 投資利益率(ROI).ベクターデータベースがよりスケーラブルで、効率的で、説明可能なAIソリューションを可能にすれば、企業はAI投資からより大きな価値を引き出すことができるだろう。
膨大な量の非構造化データをリアルタイムで処理・分析できるAIアプリケーションを構築できるようになったことで、さまざまなビジネス機能において自動化、最適化、イノベーションの新たな可能性が広がっている。顧客サービスやマーケティングから、サプライチェーン管理や財務予測まで、エンタープライズAIにおけるベクトルデータベースの潜在的な用途は無限です。
その結果、企業におけるAIの導入が大幅に増加し、さまざまな業種の企業がベクターデータベースを活用して競争優位性とビジネスの成長を推進しています。ベクターデータベースは、組織がより迅速なTime-to-Value、運用コストの削減、収益源の拡大を達成するのに役立つため、AIイニシアチブのROIも改善されるでしょう。
ベクターデータベースを企業に導入するための10の戦略
今週は、ベクター・データベースを企業で採用するための10の戦略も紹介した:
ベクターデータベースをビジネス目標に合わせる: ベクターデータベースのメリットを享受し、具体的なビジネス価値を高めることができる具体的なユースケースを特定する。
スケーラビリティとパフォーマンスのニーズを評価する: 最適なスケーラビリティ・アプローチを決定するために、現在のデータ量、予測される増加、およびクエリー・パターンを評価します。
シームレスな統合と互換性の確保: 潜在的な相互運用性の問題に対処し、ベクターデータベースを既存のインフラストラクチャやデータパイプラインとシームレスに統合します。
強固なセキュリティ対策を実施する: 強力な暗号化、セキュアな鍵管理、定期的なアクセス監視と監査を実施することで、組織の資産を保護します。
インデックス作成とクエリのパフォーマンスを最適化する: データ特性とクエリパターンに沿ったインデックス作成戦略を選択し、最適なパフォーマンスを確保するために戦略を継続的に反復します。
社内の専門性を高め、協力関係を促進する: 包括的なトレーニングプログラムに投資し、部門横断的なコラボレーションを促進することで、ベクターデータベースの導入を加速し、そのメリットを最大限に引き出す。
段階的な実施アプローチを採用する: 焦点を絞ったパイロット・プロジェクトから小規模に開始し、フィードバックを集め、徐々に導入規模を拡大することで、混乱を最小限に抑え、リソースを効果的に管理する。
メタデータと運用データを活用する: メタデータを活用して、的を絞ったコンテキストに応じたクエリーを可能にし、運用データを分析してベクターデータベースの構成を微調整し、パフォーマンスを最適化します。
既存のデータパイプラインとの統合 データの取り込み、前処理、変換を効率的に行い、データの品質と信頼性を維持するためのデータガバナンスポリシーを確立する。
適切なベクターデータベースのソリューションを選択する: オープンソースと商用オプションの両方を評価し、組織の要件と能力に最適なものを見つける。
エンタープライズAIが進化を続ける中、ベクターデータベースはイノベーションと競争優位性を推進する上でますます重要な役割を果たすようになるでしょう。この革新的なテクノロジーを採用し、これらの実装戦略に従うことで、AI革命の最前線に組織を位置づけることができます。
インフォグラフィックス、統計、ハウツーガイド、記事、ビデオなど、エンタープライズAIに関するその他のコンテンツについては、Skim AIをフォローしてください。 LinkedIn
創業者、CEO、ベンチャーキャピタリスト、投資家の皆様は、専門的なAIアドバイザリーまたはデューデリジェンスサービスをお探しですか?貴社のAI製品戦略や投資機会について、十分な情報に基づいた意思決定を行うために必要なガイダンスを得ることができます。
企業向けAIソリューションの立ち上げにお困りですか?当社のAIワークフォースマネジメント・プラットフォームを使用して独自のAI労働者を構築することをお考えですか?ご相談ください
ベンチャーキャピタルやプライベートエクイティが支援する以下の業界の企業向けに、カスタムAIソリューションを構築しています:医療テクノロジー、ニュース/コンテンツアグリゲーション、映画/写真制作、教育テクノロジー、リーガルテクノロジー、フィンテック&暗号通貨。


