
エンタープライズAIとLLMアプリケーションのためのベクターデータベース・トップ5



膨大な量の高次元データを効率的に保存、管理、検索する能力は、今日の企業にとって最重要となっている。ベクターデータベースは強力なソリューションとして登場し、AIを活用したアプリケーションの可能性を最大限に引き出すことを可能にしました。これらの特殊なデータベースは、複雑なベクトルデータを扱うように設計されており、高速な類似検索、レコメンデーション、その他の高度な機能を容易にします。AIが現代技術のあらゆる側面に浸透し続ける中、ベクターデータベースは競争力を得ようとする企業にとって不可欠なツールとなっている。
このブログでは、市販のベクターデータベースのトップ5を取り上げます:
1. 松ぼっくり
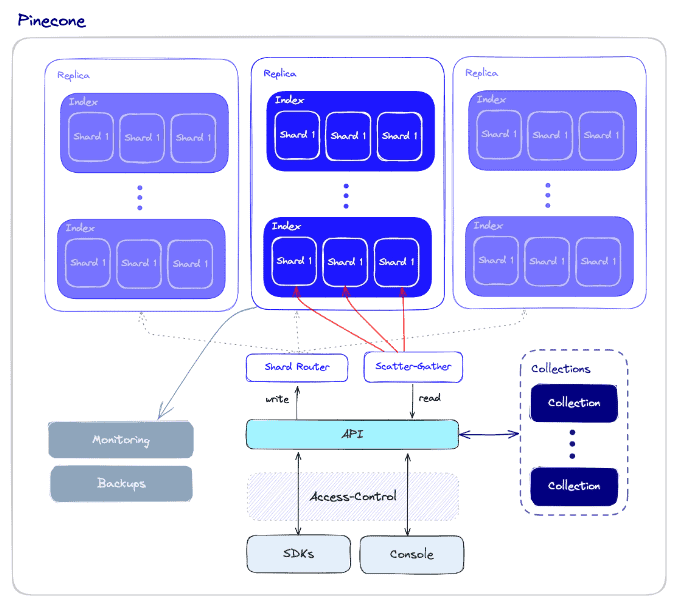
Pineconeは、高いパフォーマンスと使いやすさを優先したフルマネージドベクトルデータベースです。高度なベクトル検索アルゴリズムとフィルタリングや分散インフラストラクチャなどの機能を組み合わせ、あらゆるスケールで高速かつ信頼性の高いベクトル検索を提供します。
Pinecone の際立った利点の 1 つは、開発者がインフラストラクチャをプロビジョニングしたり保守したりする必要がない、サーバーレスという性質です。これにより、開発者はアプリケーションの構築に集中でき、Pinecone は複雑なデータベースの管理とスケーリングを行います。Pinecone は一般的な機械学習フレームワークやデータソースとシームレスに統合できるため、セマンティック検索、レコメンデーション、異常検知、質問応答など、幅広いアプリケーションに対応できます。
2. クロマ

Chromaは、機械学習モデルやフレームワークとシームレスに統合するために設計されたベクトルデータベースです。Chromaの主な目的は、効率的なベクトルの保存、検索、類似検索機能を提供することで、AIを活用したアプリケーションの構築プロセスを簡素化することです。
Chromaの特筆すべき特徴のひとつは、リアルタイム・インデックス機能で、開発者は新しいデータをアプリケーションに素早く取り込むことができる。さらに、Chromaはメタデータの保存をサポートしており、ベクターにコンテキスト情報を関連付けることができます。Chromaのユーザーフレンドリーなインターフェースと包括的なドキュメントにより、導入は簡単です。Chromaは、さまざまな距離メトリックとインデックス作成アルゴリズムをサポートすることで、セマンティック検索、推薦システム、異常検知など、さまざまなユースケースにおいて最適なパフォーマンスを保証します。
3. クドラント
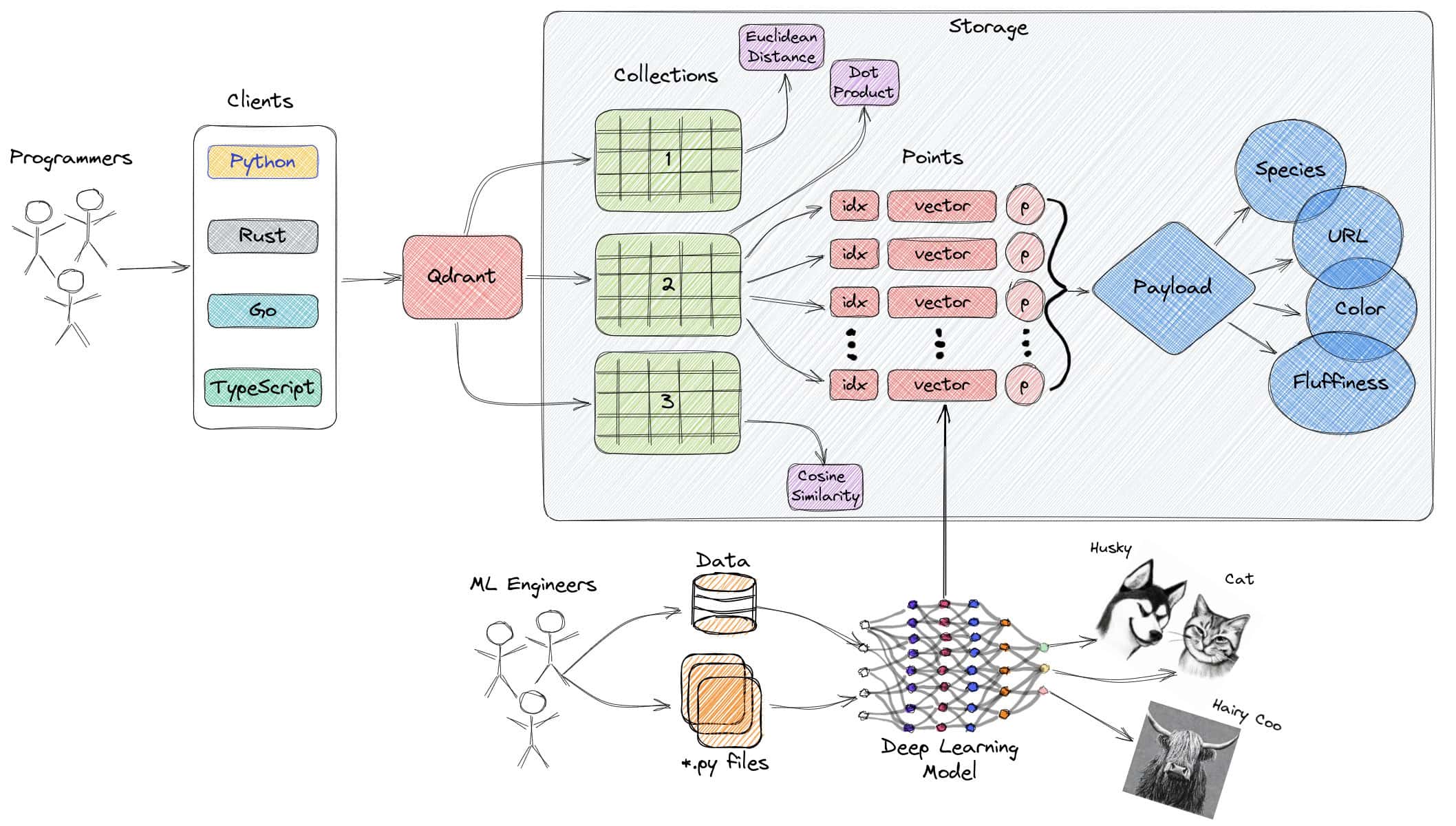
QdrantはRustで書かれたオープンソースのベクトル類似検索エンジンです。メタデータを追加したベクトルを保存、検索、管理するための便利な API を提供し、開発者はニューラルネットワークのエンコーダやエンベッディングを、マッチング、検索、レコメンデーションなどのためのプロダクションレディのアプリケーションに変換することができます。
Qdrantは、リアルタイム更新、高度なフィルタリング、分散インデックス、クラウドネイティブなデプロイメントオプションなど、豊富な機能を提供します。何十億ものベクトルや高いクエリ負荷を処理できるように設計されたQdrantは、機械学習フレームワークとシームレスに統合され、セマンティック検索、レコメンデーション、チャットボット、マッチングエンジン、異常検知など様々なユースケースでベクトル検索ソリューションを構築する強力なツールとなります。
4. ウィービエイト
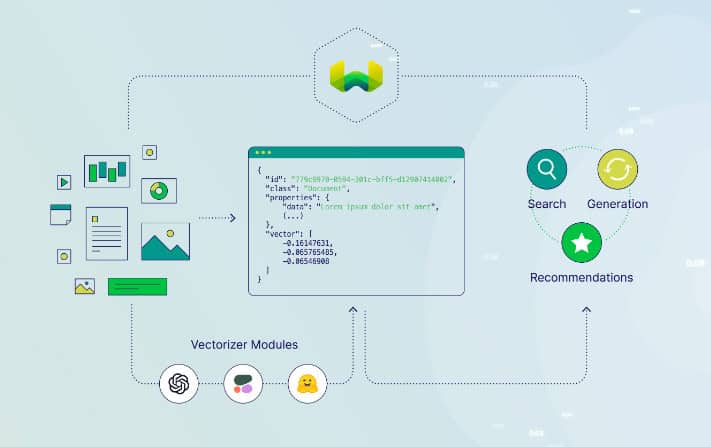
Weaviateは、スピード、スケーラビリティ、使いやすさを優先したオープンソースのベクターデータベースです。オブジェクトとベクトルの両方を保存できることが特徴で、ベクトル検索と構造化フィルタリングを組み合わせるのに適している。Weaviate は、GraphQL ベースの API、CRUD 操作、水平スケーリング、クラウドネイティブなデプロイメントオプションを提供し、開発者に柔軟でスケーラブルなソリューションを提供します。
さらにWeaviateは、NLPタスク、自動スキーマ設定、カスタムベクタライズのためのモジュールを組み込み、その機能をさらに強化している。様々な距離メトリクスとインデックスタイプをサポートし、一般的な機械学習ツール、グラフデータベース、Kubernetes環境とシームレスに統合できる。Weaviateのモジュラーアーキテクチャと豊富な機能により、セマンティック検索、画像検索、レコメンデーション、ナレッジグラフなど、多様なユースケースにわたるベクトル検索アプリケーションを構築するための強力なツールとなる。
5. ミルバス
Milvusは、埋め込み管理、類似検索、スケーラブルなAIアプリケーションのために特別に設計されたオープンソースのベクトルデータベースです。ヘテロジニアスコンピュートのサポート、ストレージの信頼性、包括的なメトリクス、クラウドネイティブアーキテクチャなど、包括的な機能を提供します。
Milvusの強みの1つは、異なる導入環境においても一貫したパフォーマンスを提供できる点にあります。Milvusは様々なインデックス、距離メトリクス、クエリタイプをサポートする柔軟なAPIを提供しており、開発者はデータベースを特定のニーズに合わせてカスタマイズすることができます。数十億ベクトルまで拡張可能で、カスタムプラグインで拡張できるため、スケーラビリティと拡張性が保証されます。Milvusは、機械学習フレームワーク、Kubernetesオペレータ、分析ツールとシームレスに統合できるため、画像・動画検索、レコメンデーションエンジン、チャットボット、異常検知など、幅広いアプリケーションに対応できる汎用性の高い選択肢となっている。
企業に適したベクターデータベースの選択
AIや機械学習の導入が加速する中、ベクターデータベースは、強力なエンタープライズAIアプリケーションを構築するための重要なコンポーネントとして台頭してきました。PineconeのようなフルマネージドソリューションからQdrantやChromaのようなオープンソースオプションまで、ベクターデータベースは様々な組織のニーズやユースケースに合わせた多様な選択肢を提供しています。
セマンティック検索エンジン、レコメンデーションシステム、その他AIを活用したアプリケーションのいずれを構築する場合でも、ベクトルデータベースは機械学習モデルの可能性を最大限に引き出すための基盤を提供します。これらのデータベースは、高速な類似検索、高度なフィルタリング、一般的なフレームワークとのシームレスな統合を可能にすることで、開発者がベクトルデータ管理の根本的な複雑さを心配することなく、革新的なソリューションの構築に集中できるようにします。


