
AI&YOUを促す思考連鎖(CoT)を再考する必要がある #68



今週のスタッツ Zero-shot CoT performance was only 5.55% for GPT-4-Turbo, 8.51% for Claude-3-Opus, and 4.44% for GPT-4. (“Chain of Thoughtlessness?” paper)
Chain-of-Thought (CoT) prompting has been hailed as a breakthrough in unlocking the reasoning capabilities of large language models (LLMs). However, recent research has challenged these claims and prompted us to revisit the technique.
今週のAI&YOUでは、このトピックについて掲載した3つのブログから洞察を探る:
We need to rethink chain-of-thought (CoT) prompting AI&YOU #68
LLMs demonstrate remarkable capabilities in natural language processing (NLP) and generation. However, when faced with complex reasoning tasks, these models can struggle to produce accurate and reliable results. This is where Chain-of-Thought (CoT) prompting comes into play, a technique that aims to enhance the problem-solving abilities of LLMs.
An advanced 迅速なエンジニアリング technique, it is designed to guide LLMs through a step-by-step reasoning process. Unlike standard prompting methods that aim for direct answers, CoT prompting encourages the model to generate intermediate reasoning steps before arriving at a final answer.
At its core, CoT prompting involves structuring input prompts in a way that elicits a logical sequence of thoughts from the model. By breaking down complex problems into smaller, manageable steps, CoT attempts to enable LLMs to navigate through intricate reasoning paths more effectively.
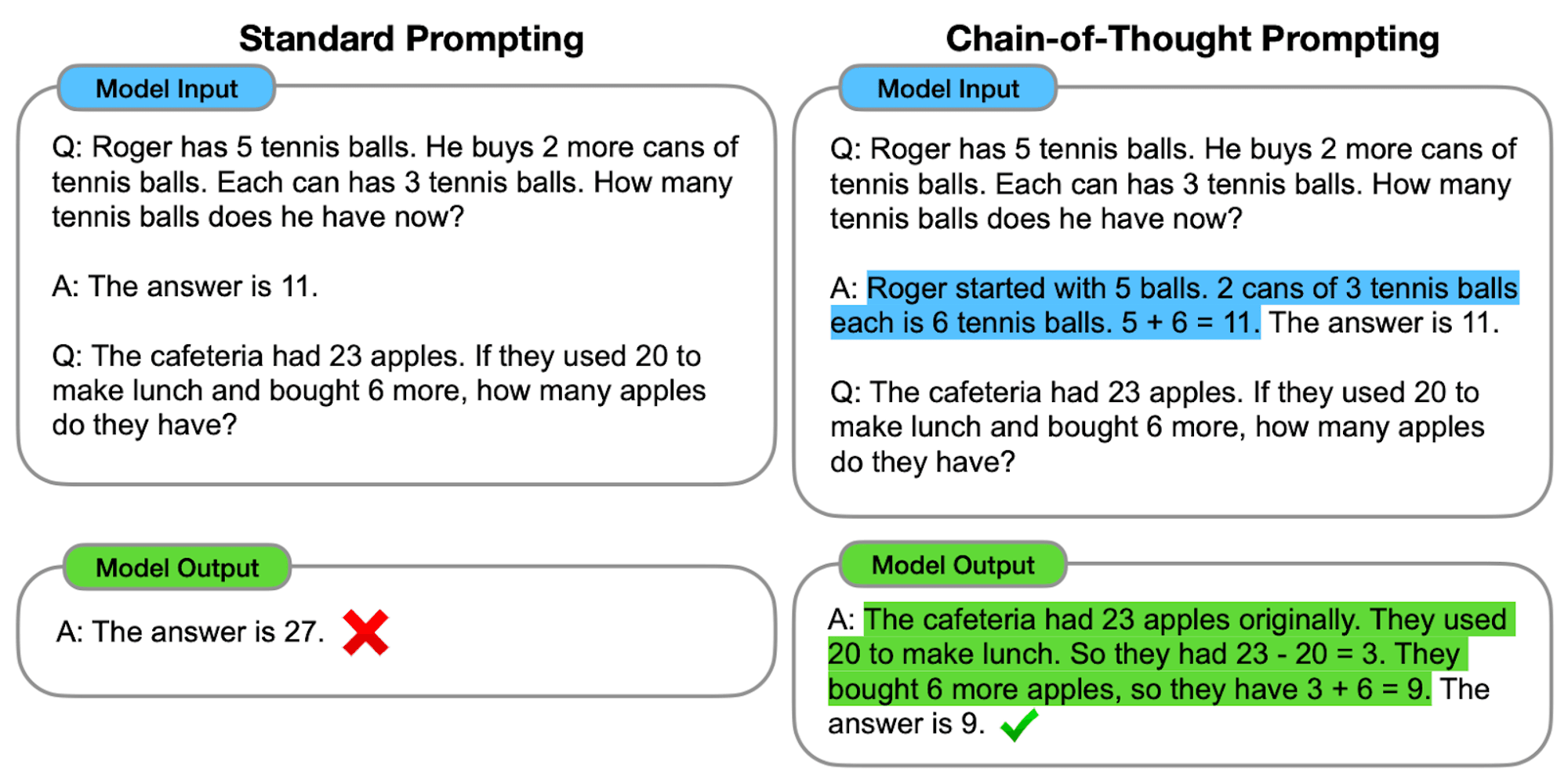
CoTの仕組み
CoTプロンプトの核心は、最終的な答えに到達する前に、一連の中間推論ステップを通して言語モデルをガイドすることである。このプロセスには通常以下が含まれる:
問題の分解: 複雑な仕事を、管理しやすい小さなステップに分解する。
ステップバイステップの推論: モデルには、各ステップを明示的に考えさせる。
論理的な進行: それぞれのステップが前のステップの上に積み重なり、思考の連鎖が生まれる。
結論 最終的な答えは、積み重ねられた推論のステップから導き出される。
CoTプロンプティングの種類
思考連鎖プロンプトはさまざまな方法で実施することができるが、主に2つのタイプが際立っている:
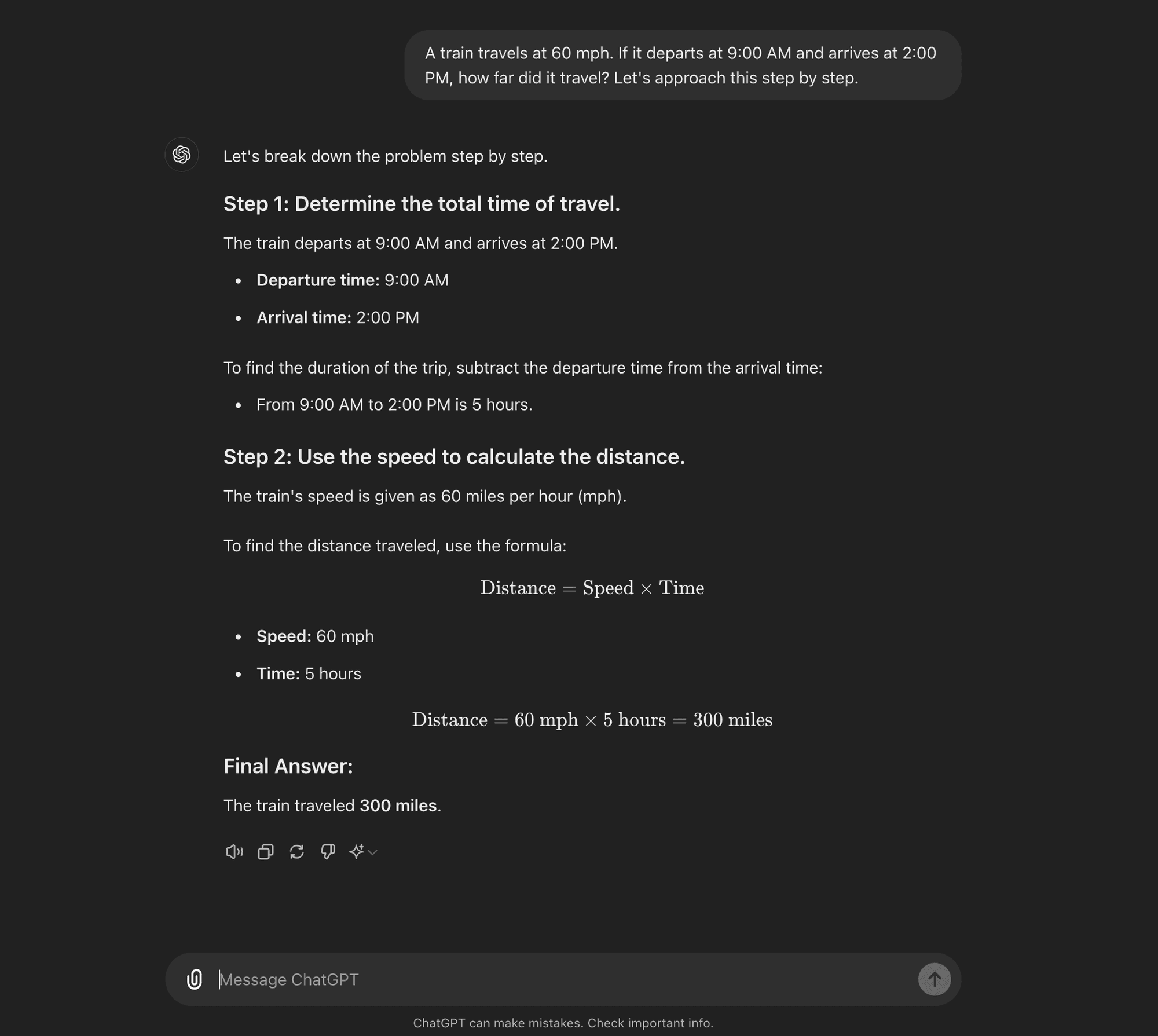
Zero-shot CoT: Zero-shot CoT doesn’t require task-specific examples. Instead, it uses a simple prompt like “Let’s approach this step by step” to encourage the model to break down its reasoning process.****
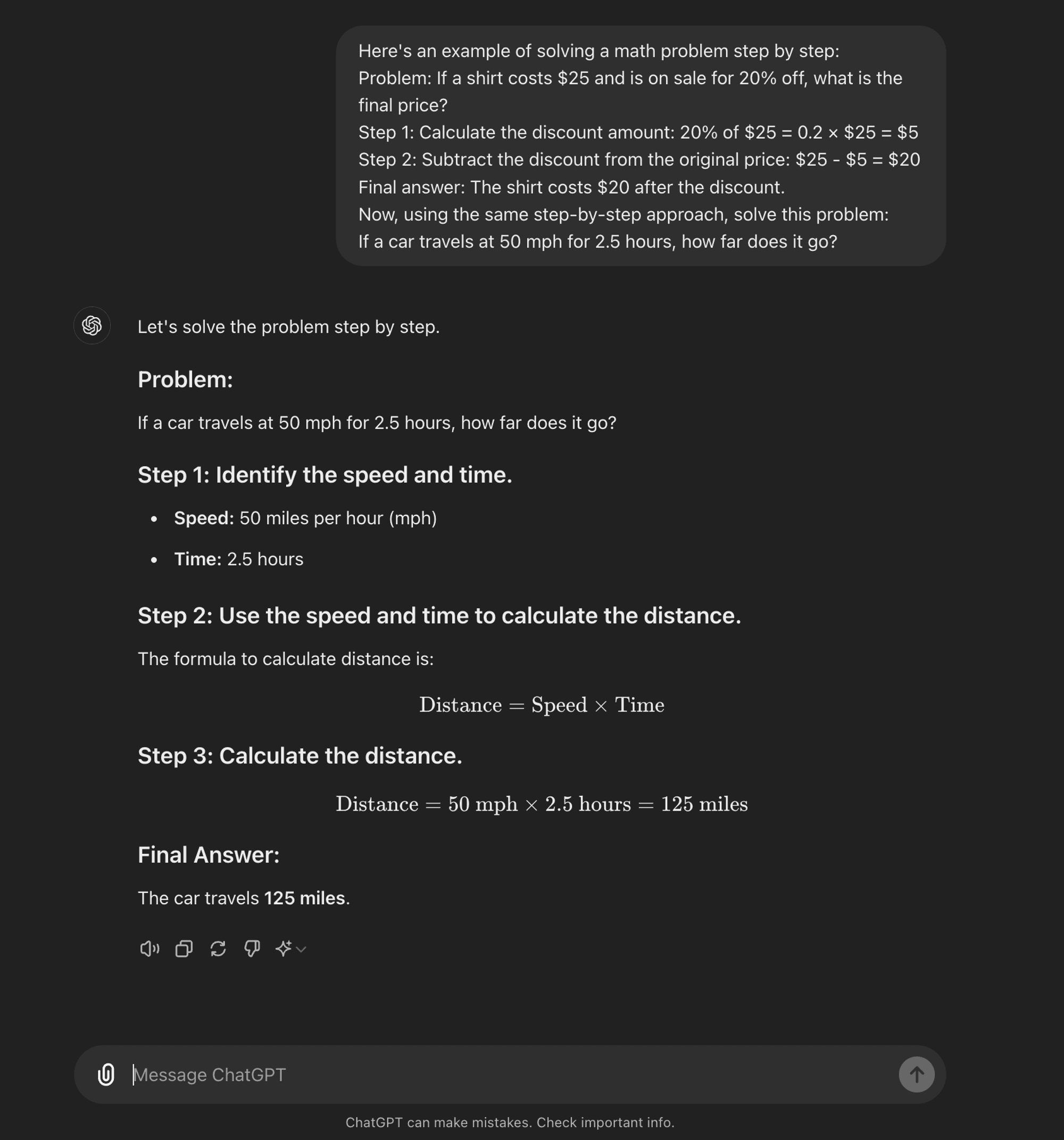
Few-shot CoT: 数発CoTでは、望ましい推論プロセスを示す少数の例をモデルに提供する。これらの例は、新しい未知の問題に取り組む際に、モデルが従うべきテンプレートの役割を果たす。
Zero-shot CoT
Few-shot CoT
AI Research Paper Breakdown: “Chain of Thoughtlessness?”
Now that you know what CoT prompting is, we can dive into some recent research that challenges some of its benefits and offers some insight into when it is actually useful.
The research paper, titled “Chain of Thoughtlessness? An Analysis of CoT in Planning,” provides a critical examination of CoT prompting’s effectiveness and generalizability. As AI practitioners, it’s crucial to understand these findings and their implications for developing AI applications that require sophisticated reasoning capabilities.

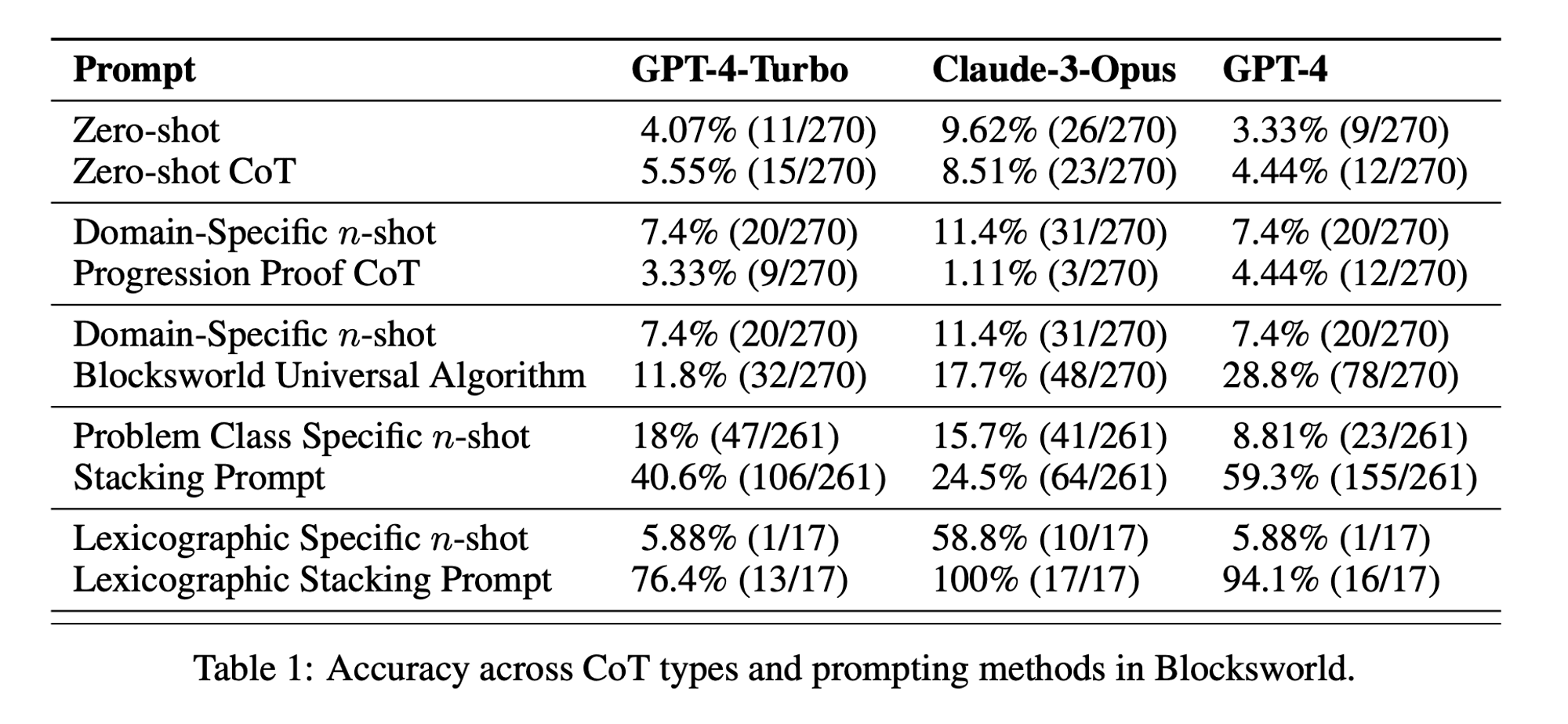
研究者たちは、ブロックワールドと呼ばれる古典的なプランニング領域を主なテスト対象として選んだ。ブロックワールドでは、一連の移動アクションを使って、ブロックの集合を初期配置からゴール配置に再配置することがタスクとなる。この領域は、推論能力と計画能力をテストするのに理想的である:
様々な複雑さの問題を生成することができる。
明確で、アルゴリズム的に検証可能な解決策がある。
LLMのトレーニング・データにはあまり含まれていないと思われる。
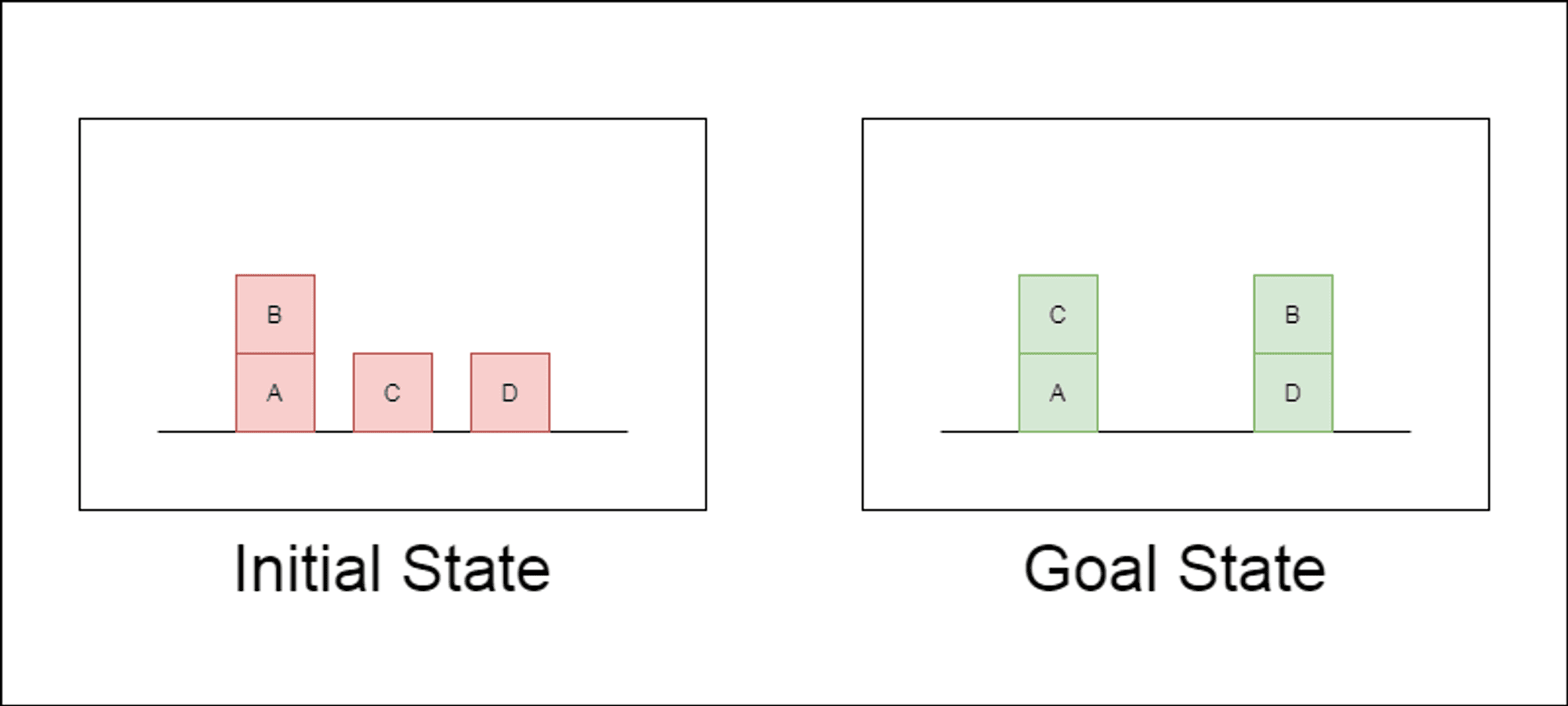
この研究では、3つの最新型LLMを検証した:GPT-4、Claude-3-Opus、GPT-4-Turboである。これらのモデルは様々な特異性のプロンプトを用いてテストされた:
ゼロショット連鎖思考(ユニバーサル): プロンプトに「ステップ・バイ・ステップで考えよう」と付け加えるだけでいい。
進行の証明(PDDLに特有): プランの正しさについて、例を挙げて一般的な説明を行う。
Blocksworldユニバーサル・アルゴリズム: あらゆるBlocksworld問題を解くための一般的なアルゴリズムを示す。
スタッキング・プロンプト ブロックワールド問題の特定のサブクラス(テーブル対スタック)に焦点を当てる。
語彙の積み重ね: ゴール状態の特定の構文形式にさらに絞り込む。
研究者たちは、これらのプロンプトを複雑さを増していく問題でテストすることで、LLMが例題で示された推論をどの程度一般化できるかを評価することを目指した。
主な調査結果を発表
本研究の結果は、CoTプロンプトに関する多くの一般的な仮定を覆すものである:
CoTの効果は限定的: これまでの主張とは異なり、CoTプロンプトは、提供された例がクエリ問題と極めて類似している場合にのみ、大幅なパフォーマンス向上を示した。問題が例題に示された正確な形式から外れると、パフォーマンスは急激に低下した。
急速なパフォーマンス低下: 問題の複雑さが増すにつれて(関係するブロックの数で測定)、使用されたCoTプロンプトに関係なく、すべてのモデルの精度が劇的に低下した。これは、LLMが単純な例で示された推論を、より複雑なシナリオに拡張するのに苦労していることを示唆している。
一般的なプロンプトの無効性: 意外なことに、より一般的なCoTプロンプトは、推論例のない標準的なプロンプトよりも成績が悪いことが多かった。これは、CoTがLLMの一般化可能な問題解決ストラテジーの学習に役立つという考えと矛盾する。
特異性のトレードオフ: この研究では、非常に具体的なプロンプトが高い精度を達成できることがわかったが、それは非常に狭い問題のサブセットにおいてのみであった。このことは、パフォーマンスの向上とプロンプトの適用可能性との間に鋭いトレードオフがあることを浮き彫りにしている。
真のアルゴリズム学習の欠如: この結果は、LLMがCoTの例題から一般的なアルゴリズムの適用方法を学んでいないことを強く示唆している。その代わりに、LLMはパターンマッチングに頼っているようだが、これは新しい問題やより複雑な問題に直面するとすぐに破綻してしまう。
これらの知見は、CoTプロンプトをアプリケーションに活用しようとしているAIの専門家や企業にとって重要な意味を持つ。CoTは特定の狭いシナリオではパフォーマンスを向上させることができるが、多くの人が期待していた複雑な推論タスクの万能薬にはならない可能性があることを示唆している。
AI開発への示唆
この研究結果は、AI開発、特に複雑な推論や計画能力を必要とするアプリケーションに取り組む企業にとって重要な意味を持つ:
CoTの効果の再評価: AI developers should be cautious about relying on CoT for tasks that require true algorithmic thinking or generalization to novel scenarios.
現在のLLMの限界: Alternative approaches may be necessary for applications requiring robust planning or multi-step problem-solving.
迅速なエンジニアリングのコスト: 特異性の高いCoTプロンプトは、狭い範囲の問題セットに対しては良い結果をもたらすが、特に一般化可能性が限られていることを考えると、このようなプロンプトを作成するために必要な人的労力は、その利点を上回る可能性がある。
評価指標の再考: Relying solely on static test sets may overestimate a model’s true reasoning capabilities.
認識と現実のギャップ 一般的な言説ではしばしば擬人化される)LLMの推論能力の認識と、この研究で実証された実際の能力との間には大きな食い違いがある。
Recommendations for AI Practitioners:
評価だ: Implement diverse testing frameworks to assess true generalization across problem complexities.
CoT Usage: Apply Chain-of-Thought prompting judiciously, recognizing its limitations in generalization.
Hybrid Solutions: Consider combining LLMs with traditional algorithms for complex reasoning tasks.
Transparency: Clearly communicate AI system limitations, especially for reasoning or planning tasks.
R&D Focus: Invest in research to enhance true reasoning capabilities of AI systems.
微調整: Consider domain-specific fine-tuning, but be aware of potential generalization limits.
For AI practitioners and enterprises, these findings highlight the importance of combining LLM strengths with specialized reasoning approaches, investing in domain-specific solutions where necessary, and maintaining transparency about AI system limitations. As we move forward, the AI community must focus on developing new architectures and training methods that can bridge the gap between pattern matching and true algorithmic reasoning.
10 Best Prompting Techniques for LLMs
This week, we also explore ten of the most powerful and common prompting techniques, offering insights into their applications and best practices.

Well-designed prompts can significantly enhance an LLM’s performance, enabling more accurate, relevant, and creative outputs. Whether you’re a seasoned AI developer or just starting with LLMs, these techniques will help you unlock the full potential of AI models.
Make sure to check out the full blog to learn more about each one.
AI & YOU』をお読みいただきありがとうございます!
インフォグラフィックス、統計、ハウツーガイド、記事、ビデオなど、エンタープライズAIに関するその他のコンテンツについては、Skim AIをフォローしてください。 LinkedIn
創業者、CEO、ベンチャーキャピタル、投資家の方で、AIアドバイザリー、AI開発、デューデリジェンスのサービスをお探しですか?貴社のAI製品戦略や投資機会について、十分な情報に基づいた意思決定を行うために必要なガイダンスを得ることができます。
企業向けAIソリューションの立ち上げにお困りですか?当社のAIワークフォースマネジメント・プラットフォームを使用して独自のAI労働者を構築することをお考えですか?ご相談ください
ベンチャーキャピタルやプライベートエクイティが支援する以下の業界の企業向けに、カスタムAIソリューションを構築しています:医療テクノロジー、ニュース/コンテンツアグリゲーション、映画/写真制作、教育テクノロジー、リーガルテクノロジー、フィンテック&暗号通貨。


