
LLMの価格体系を理解する:インプット、アウトプット、コンテクスト・ウィンドウ



企業のAI戦略において、大規模言語モデル(LLM)の価格体系を理解することは、効果的なコスト管理のために極めて重要です。LLMに関連する運用コストは、適切な監視が行われないとすぐにエスカレートし、予期せぬコスト高騰につながる可能性があるため、予算が頓挫し、普及の妨げになります。T
このブログ記事では、LLMの料金体系の主要な構成要素について掘り下げ、LLMの利用を最適化し、経費を管理するのに役立つ洞察を提供します。
LLMの価格設定は通常、3つの主要な要素を中心に展開される: 入力トークン、出力トークン、コンテキストウィンドウ.これらの各要素は、アプリケーションでLLMを利用する際の全体的なコストを決定する上で重要な役割を果たします。これらの要素を十分に理解することで、モデルの選択、使用パターン、最適化戦略について、十分な情報に基づいた意思決定を行うことができるようになります。
LLM価格の基本構成要素
入力トークン
入力トークンは、処理のためにLLMに入力されるテキストを表します。これには、プロンプト、指示、およびモデルに提供される追加コンテキストが含まれます。入力トークンの数は、各API呼び出しのコストに直接影響します。トークンの数が多いほど、処理により多くの計算リソースが必要になるからです。
出力トークン
出力トークンは、お客様の入力に応じて LLM が生成するテキストです。出力トークンの価格は、テキスト生成に必要な追加の計算工数を反映して、入力トークンとは異なることがよくあります。出力トークンの使用量を管理することは、特に大量のテキストを生成するアプリケーションでは、コストを管理するために非常に重要です。
コンテキストウィンドウ
コンテキストウィンドウとは、モデルが応答を生成する際に考慮できる過去のテキストの量のことである。コンテキストウィンドウを大きくすると、より包括的な理解が可能になるが、トークンの使用量と計算要件が増えるため、コストが高くなる。
インプット・トークン:インプットトークンとは何か?
入力トークンは、LLMが処理するテキストの基本単位である。通常、トークンは単語の一部に対応し、一般的な単語は1つのトークンで表され、あまり一般的でない単語は複数のトークンに分割されることが多い。例えば、"The quick brown fox "という文は、["The", "quick", "bro", "wn", "fox"]とトークン化され、5つの入力トークンになります。
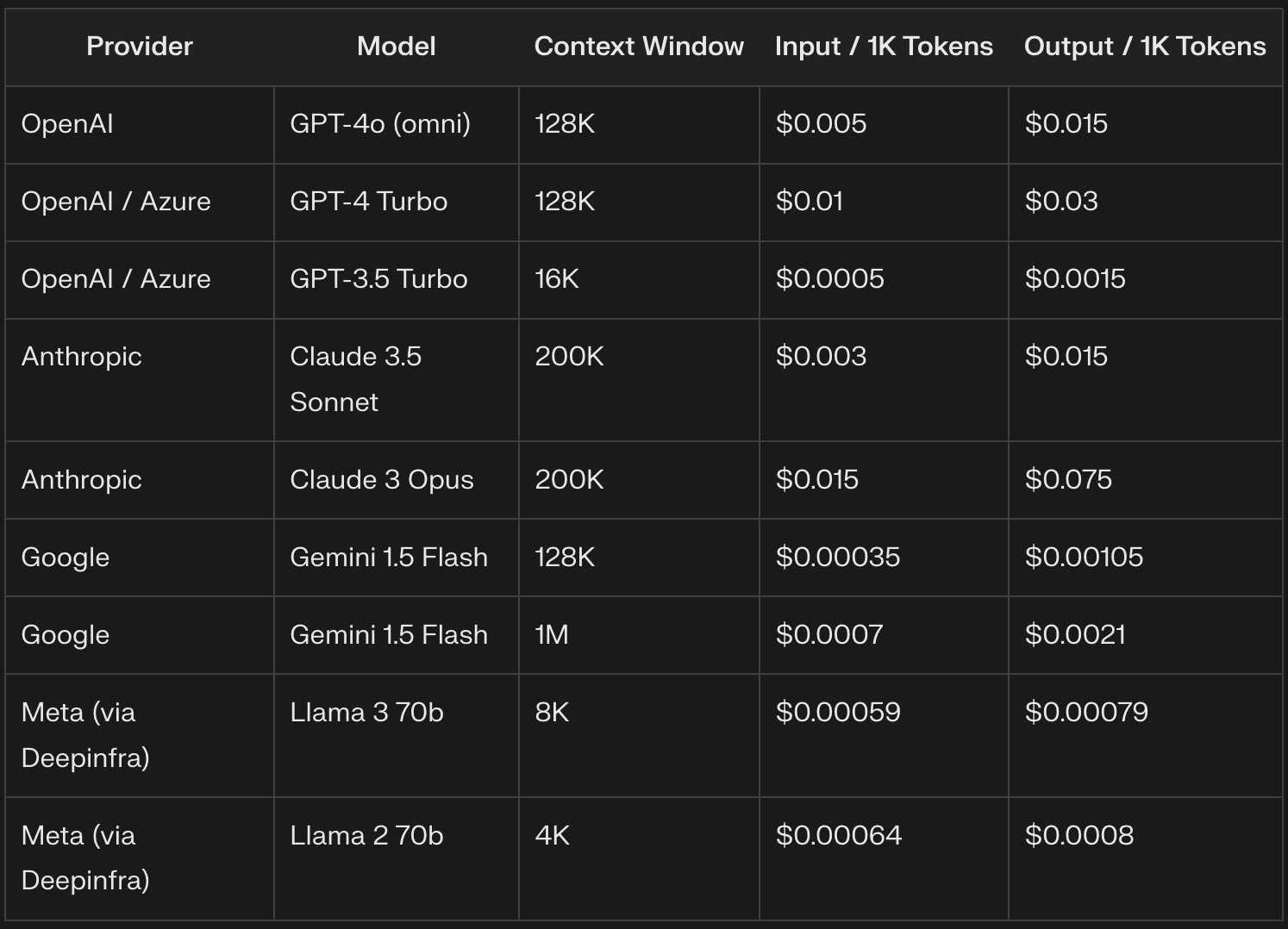
LLM プロバイダーは、多くの場合、1,000 トークンあたりのレートに基づいて投入トークンに課金します。例えば、GPT-4oは100万入力トークンあたり$5を請求し、これは1,000入力トークンあたり$0.005に相当する。正確な価格設定はプロバイダーやモデルのバージョンによって大きく異なり、より高度なモデルは一般的に高いレートを要求します。
LLMのコストを効果的に管理するには、インプット・トークンの使用量を最適化するための以下の戦略を検討してください:
簡潔なプロンプトを作成する:不必要な言葉を排除し、明確で直接的な指示に集中する。
効率的なエンコーディングを使用する: より少ないトークンでテキストを表現できるエンコーディング方法を選択します。
プロンプト・テンプレートを導入する: 一般的なタスクに最適化されたプロンプト構造を開発し、再利用する。
入力トークンを慎重に管理することで、AIアプリケーションの品質と有効性を維持しながら、LLM使用に関連するコストを大幅に削減することができます。
アウトプットのトークン:コストを理解する
出力トークンは、入力に応じて LLM が生成するテキストを表します。入力トークンと同様に、出力トークンもモデルのトークン化処理に基づいて計算されます。ただし、出力トークンの数はタスクとモデルの設定によって大きく異なります。例えば、簡単な質問であれば、トークンが少ない簡潔な応答が生成されるかもしれませんが、詳細な説明を求める要求であれば、数百のトークンが生成されるかもしれません。
LLM プロバイダーは、出力トークンに入力トークンとは異なる価格を設定することが多く、通常、テ キスト生成の計算の複雑さにより、より高いレートを設定しています。たとえば、OpenAIはGPT-4oに対して、100万トークンあたり$15(1,000トークンあたり$0.015)を課金しています。
出力トークンの使用を最適化し、コストを管理する:
プロンプトまたはAPIコールに明確な出力長制限を設定する。
数発学習」のようなテクニックを使って、モデルをより簡潔な回答に導く。
LLMの出力から不要な内容を取り除く後処理を実施する。
冗長なLLMコールを減らすために、頻繁にリクエストされる情報をキャッシュすることを検討する。
コンテキストウィンドウ隠れたコストドライバー
コンテキストウィンドウは、LLMが応答を生成する際に、どれだけ前のテキストを考慮できるかを決定する。この機能は、会話の一貫性を維持し、モデルが以前の情報を参照できるようにするために非常に重要です。コンテキストウィンドウの大きさは、特に長期記憶や複雑な推論を必要とするタスクにおいて、モデルのパフォーマンスに大きな影響を与える可能性がある。
コンテキスト・ウィンドウを大きくすると、モデルによって処理される入力トークンの数が直接的に増えるため、コストが高くなる。例えば
3,000トークンの会話を処理する4,000トークンのコンテキスト・ウィンドウを持つモデルは、3,000トークンすべてに課金されます。
8,000トークンのコンテキストウィンドウを持つ同じ会話は、会話の以前の部分を含む7,000トークンに課金されるかもしれない。
このスケーリングは、特に長時間の対話や文書分析を扱うアプリケーションでは、大幅なコスト増につながる可能性がある。
コンテキストウィンドウの使用を最適化する:
タスク要件に基づく動的なコンテキストのサイジングを実装する。
要約のテクニックを使って、長い会話から関連する情報を凝縮する。
長い文書を処理するためにスライディングウィンドウアプローチを採用し、最も関連性の高いセクションに焦点を当てる。
広範な文脈を必要としない作業には、より小型で特殊なモデルを使うことを検討する。
コンテキスト・ウィンドウを注意深く管理することで、高品質のアウトプットの維持とLLMコストの抑制のバランスをとることができます。ゴールは、トークンの使用量や関連費用を不必要に増加させることなく、目の前のタスクに十分なコンテキストを提供することであることを忘れないでください。
LLM価格の今後の動向
LLMの状況が進化するにつれて、料金体系にも変化が見られるかもしれない:
タスクベースの価格設定: トークン数ではなく、タスクの複雑さに基づいて課金されるモデル。
サブスクリプション・モデル: LLMへの定額アクセスは、利用制限または段階的な価格設定が可能。
パフォーマンス・ベースド・プライシング: 量だけでなく、アウトプットの質や正確さに結びついたコスト。
技術の進歩がコストに与える影響
AIの継続的な研究開発は、以下をもたらすかもしれない:
より効率的なモデル: 運用コストの削減につながる計算要件の削減。
圧縮技術の向上: 入力と出力のトークン数を減らすための強化された方法。
エッジコンピューティングの統合: LLMタスクのローカル処理により、クラウドコンピューティングのコストを削減できる可能性がある。
結論
LLMの価格体系を理解することは、企業のAIアプリケーションにおける効果的なコスト管理に不可欠です。入力トークン、出力トークン、コンテキストウィンドウのニュアンスを把握することで、企業はモデルの選択と使用パターンについて十分な情報に基づいた意思決定を行うことができます。トークン使用量の最適化やキャッシュの活用など、戦略的なコスト管理手法を導入することで、大幅なコスト削減が可能になります。
LLMテクノロジーが進化し続ける中、価格動向や新たな最適化戦略について常に情報を得ることは、費用対効果の高いAIオペレーションを維持する上で極めて重要である。LLMのコスト管理を成功させるには、継続的なモニタリング、分析、適応を行い、AIへの投資から最大限の価値を引き出す必要があります。
貴社がLLMの価格体系をより効果的に活用する方法についてお知りになりたい場合は、お気軽にお問い合わせください!


