
LLMのための数発プロンプト、学習、微調整 - AI&YOU #67 LLMのための数発プロンプト、学習、微調整 - AI&YOU #67



Few-Shot Prompting, Learning, and Fine-Tuning for LLMs – AI&YOU #67 Few-Shot Prompting, Learning, and Fine-Tuning for LLMs – AI&YOU #67
今週のスタッツ Research by MobiDev on few-shot learning for coin image classification found that using just 4 image examples per coin denomination, they could achieve ~70% accuracy.
In AI, the ability to learn efficiently from limited data has become crucial. That’s why it’s important for enterprises to understand few-shot learning, few-shot prompting, and fine-tuning LLMs.
今週のAI&YOUでは、私たちが公開した3つのブログから得た洞察を紹介します:
Few-Shot Prompting, Learning, and Fine-Tuning for LLMs – AI&YOU #67
Few Shot Learning is an innovative machine learning paradigm that enables AI models to learn new concepts or tasks from only a few examples. Unlike traditional supervised learning methods that require vast amounts of labeled training data, Few Shot Learning techniques allow models to generalize effectively using just a small number of samples. This approach mimics the human ability to quickly grasp new ideas without the need for extensive repetition.
フューショットラーニングの本質は、事前知識を活用し、新しいシナリオに迅速に適応する能力にある。モデルが「学習方法を学習する」メタ学習などのテクニックを使うことで、Few Shot Learningアルゴリズムは、最小限の追加トレーニングで幅広いタスクに取り組むことができる。この柔軟性により、データが乏しかったり、入手にコストがかかったり、常に進化し続けるようなシナリオにおいて、非常に貴重なツールとなる。

AIにおけるデータ不足の課題
すべてのデータが同じように作成されるわけではなく、高品質のラベル付きデータは希少で貴重な商品となり得る。この希少性は、従来の教師あり学習アプローチにとって大きな課題となる。教師あり学習アプローチでは、満足のいく性能を達成するために、通常、数千から数百万のラベル付き事例を必要とする。
データ不足の問題は、希少疾患の症例が限られているヘルスケアなどの専門領域や、新しいカテゴリーのデータが頻繁に出現する変化の激しい環境において特に深刻である。このようなシナリオでは、大規模なデータセットを収集し、ラベル付けするために必要な時間とリソースは法外なものとなり、AIの開発と展開におけるボトルネックとなる。
数発学習と従来の教師あり学習の比較
Understanding the distinction between Few Shot Learning and traditional supervised learning is crucial to grasp its real-world impact.
トラディショナル 教師付き学習, while powerful, has drawbacks:
データ依存性: Struggles with limited training data.
柔軟性がない: Performs well only on specific trained tasks.
資源強度: Requires large, expensive datasets.
継続的なアップデート: Needs frequent retraining in dynamic environments.
Few Shot Learning offers a paradigm shift:
サンプル効率: Generalizes from few examples using meta-learning.
迅速な適応: Quickly adapts to new tasks with minimal examples.
リソースの最適化: Reduces data collection and labeling needs.
継続的な学習: Suitable for incorporating new knowledge without forgetting.
汎用性がある: Applicable across various domains, from computer vision to NLP.
By tackling these challenges, Few Shot Learning enables more adaptable and efficient AI models, opening new possibilities in AI development.
サンプル効率学習のスペクトラム
A fascinating spectrum of approaches aims to minimize required training data, including Zero Shot, One Shot, and Few Shot Learning.
ゼロショット学習:例なしに学習する
Recognizes unseen classes using auxiliary information like textual descriptions
Valuable when labeled examples for all classes are impractical or impossible
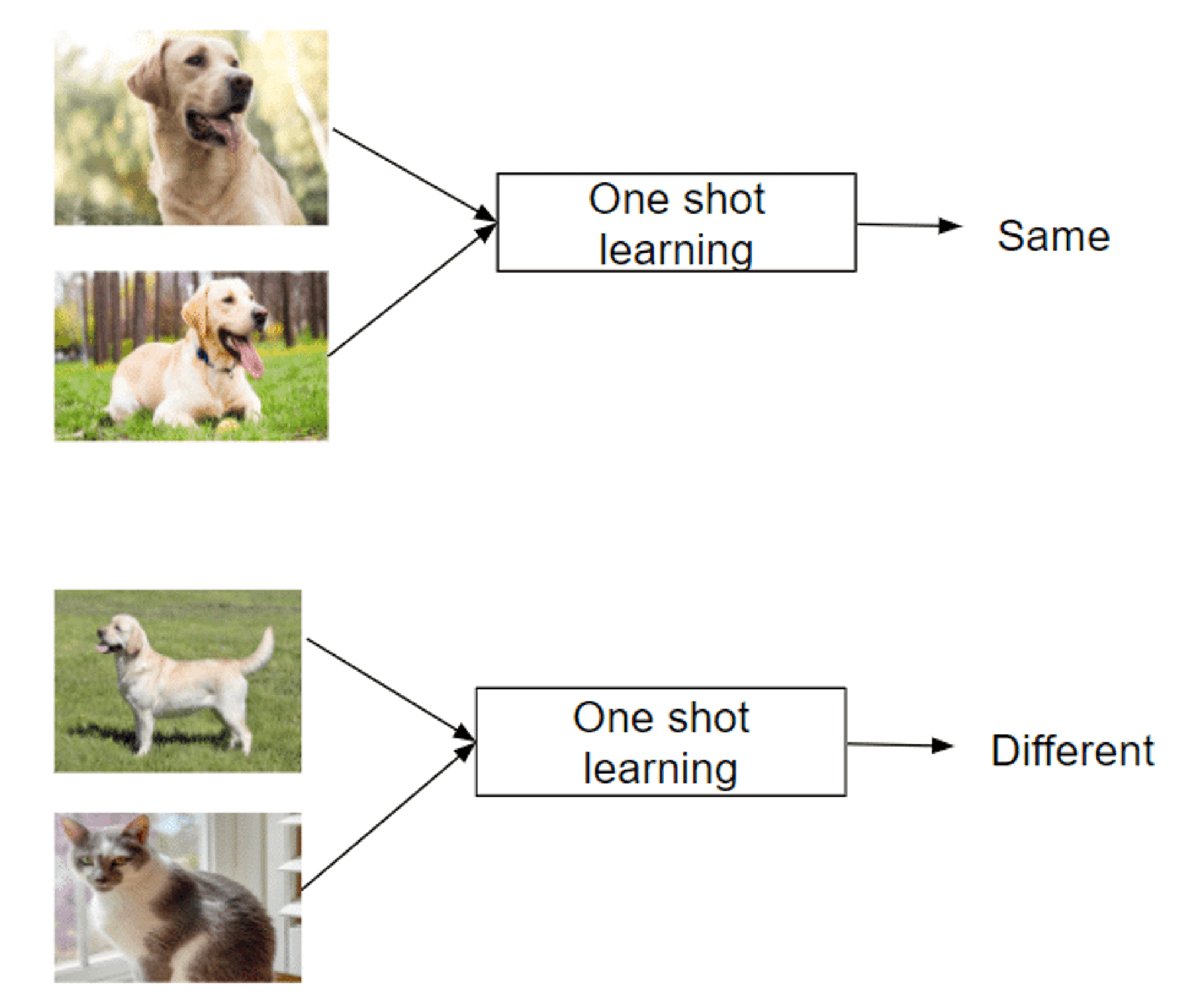
ワンショット学習:単一インスタンスからの学習
Recognizes new classes from just one example
Mimics human ability to grasp concepts quickly
Successful in areas like facial recognition
数撃ちゃ当たる学習:最小限のデータでタスクをマスターする
Uses 2-5 labeled examples per new class
Balances extreme data efficiency and traditional methods
Enables rapid adaptation to new tasks or classes
Leverages meta-learning strategies to learn how to learn
This spectrum of approaches offers unique capabilities in tackling the challenge of learning from limited examples, making them invaluable in data-scarce domains.
Few Shot Prompting vs Fine Tuning LLM
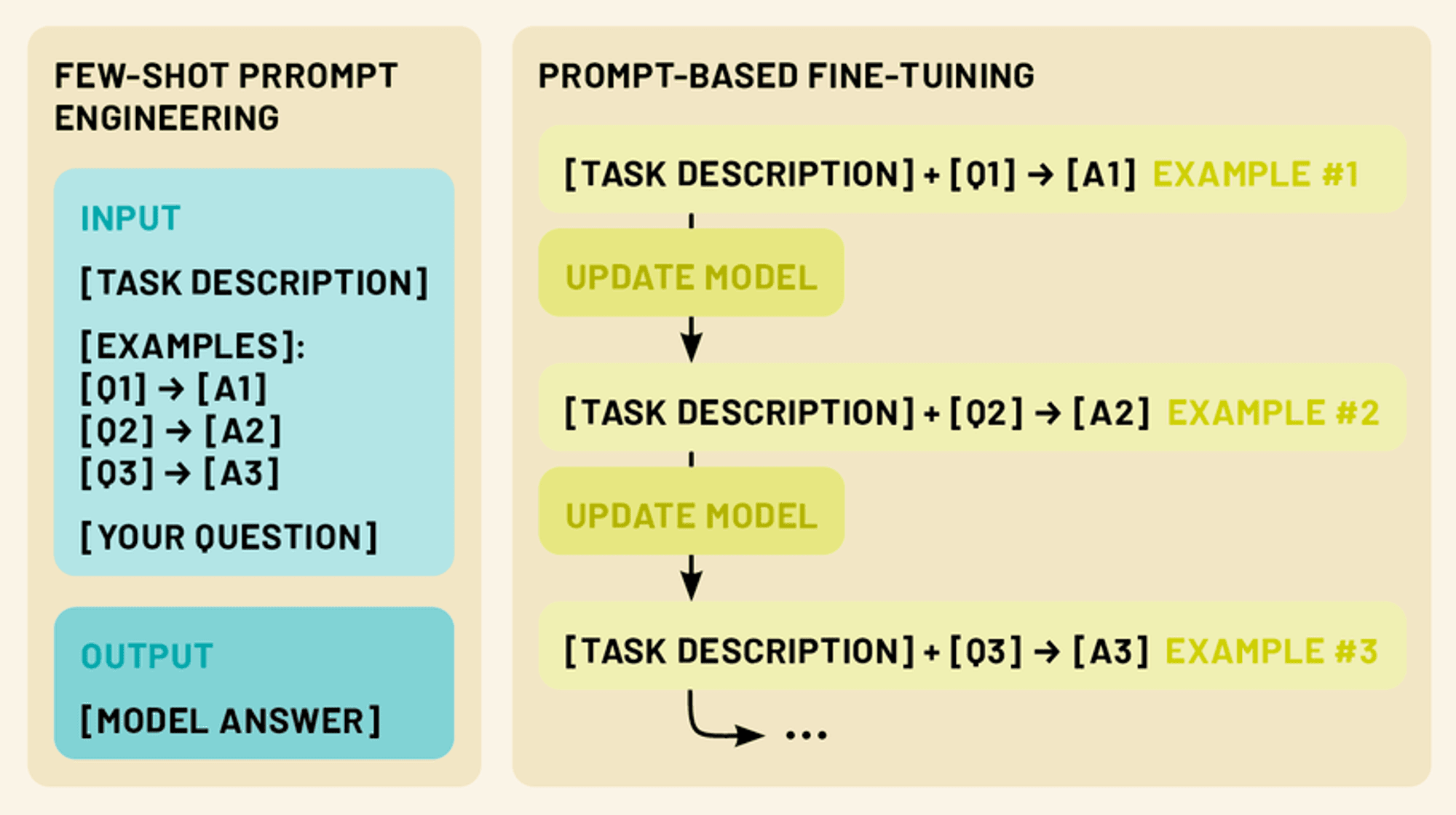
Two more powerful techniques exist in this realm: few-shot prompting and fine-tuning. Few-shot prompting involves crafting clever input prompts that include a small number of examples, guiding the model to perform a specific task without any additional training. Fine-tuning, on the other hand, involves updating the model’s parameters using a limited amount of task-specific data, allowing it to adapt its vast knowledge to a particular domain or application.
Both approaches fall under the umbrella of few-shot learning. By leveraging these techniques, we can dramatically enhance the performance and versatility of LLMs, making them more practical and effective tools for a wide range of applications in natural language processing and beyond.
フューショット・プロンプティングLLMの可能性を引き出す
Few-shot prompting capitalizes on the model’s ability to understand instructions, effectively “programming” the LLM through crafted prompts.
Few-shot prompting provides 1-5 examples demonstrating the desired task, leveraging the model’s pattern recognition and adaptability. This enables performance of tasks not explicitly trained for, tapping into the LLM’s capacity for in-context learning.
By presenting clear input-output patterns, few-shot prompting guides the LLM to apply similar reasoning to new inputs, allowing quick adaptation to new tasks without parameter updates.
数ショットのプロンプトの種類(ゼロショット、ワンショット、数ショット)
Few-shot prompting encompasses a spectrum of approaches, each defined by the number of examples provided. (Just like few-shot learning):
ゼロショットのプロンプト: このシナリオでは、例題は提供されない。その代わり、モデルにはタスクの明確な指示や説明が与えられる。例えば、"次の英文をフランス語に翻訳してください:[入力テキスト]"。
一発プロンプト: ここでは、実際の入力の前に一つの例が提供される。これはモデルに、期待される入出力関係の具体的な例を与える。例えば「次のレビューのセンチメントをポジティブかネガティブかに分類しなさい。例:「この映画は素晴らしかった!」 - 肯定的な入力:「筋書きに耐えられなかった。- モデルは応答を生成する]"
数発のプロンプト: このアプローチでは、実際の入力の前に複数の例(通常2~5)を提供する。これにより、モデルはタスクのより複雑なパターンやニュアンスを認識することができる。例えば「次の文を質問か文に分類しなさい:空は青い。- 文『今何時ですか』 - 質問『私はアイスクリームが大好きです』。- 文の入力:'近くのレストランはどこにありますか' - [モデルが応答を生成する]"
効果的な数発プロンプトをデザインする
効果的なプロンプトを作成することは、芸術であると同時に科学でもあります。ここでは、いくつかの重要な原則を紹介します:
明快さと一貫性: 例や指示が明確で、一貫した形式に従っていることを確認しましょう。そうすることで、モデルがパターンを認識しやすくなります。
多様性: 複数の例を使用する場合は、モデルにタスクのより広い理解を与えるために、考えられる入力と出力の範囲をカバーするようにしてください。
関連性がある: 対象とする特定のタスクやドメインに密接に関連する例を選びます。こうすることで、モデルが知識の最も関連性の高い側面に集中できるようになります。
簡潔さ: 十分な文脈を提供することは重要ですが、モデルを混乱させたり、重要な情報を薄めたりするような、長すぎたり複雑すぎたりするプロンプトは避けてください。
実験: Don’t be afraid to iterate and experiment with different prompt structures and examples to find what works best for your specific use case.
数発のプロンプトを使いこなすことで、LLMの潜在能力を最大限に引き出し、追加入力やトレーニングを最小限に抑えながら、さまざまなタスクに取り組ませることができる。
LLMの微調整:限られたデータでモデルを調整する
数ショットのプロンプトは、モデル自体に変更を加えることなく、LLMを新しいタスクに適応させるための強力なテクニックであるが、ファインチューニングは、特定のタスクやドメインでさらに優れたパフォーマンスを発揮するために、モデルのパラメータを更新する方法を提供する。ファインチューニングにより、事前に訓練されたLLMにエンコードされた膨大な知識を活用しながら、タスク固有のわずかなデータを使用して、特定のニーズに合わせてLLMを調整することができます。
LLMの文脈でファインチューニングを理解する
Fine-tuning an LLM involves further training a pre-trained model on a smaller, task-specific dataset. This process adapts the model to the target task while building upon existing knowledge, requiring less data and resources than training from scratch.
In LLMs, fine-tuning typically adjusts weights in upper layers for task-specific features, while lower layers remain largely unchanged. This “transfer learning” approach retains broad language understanding while developing specialized capabilities.
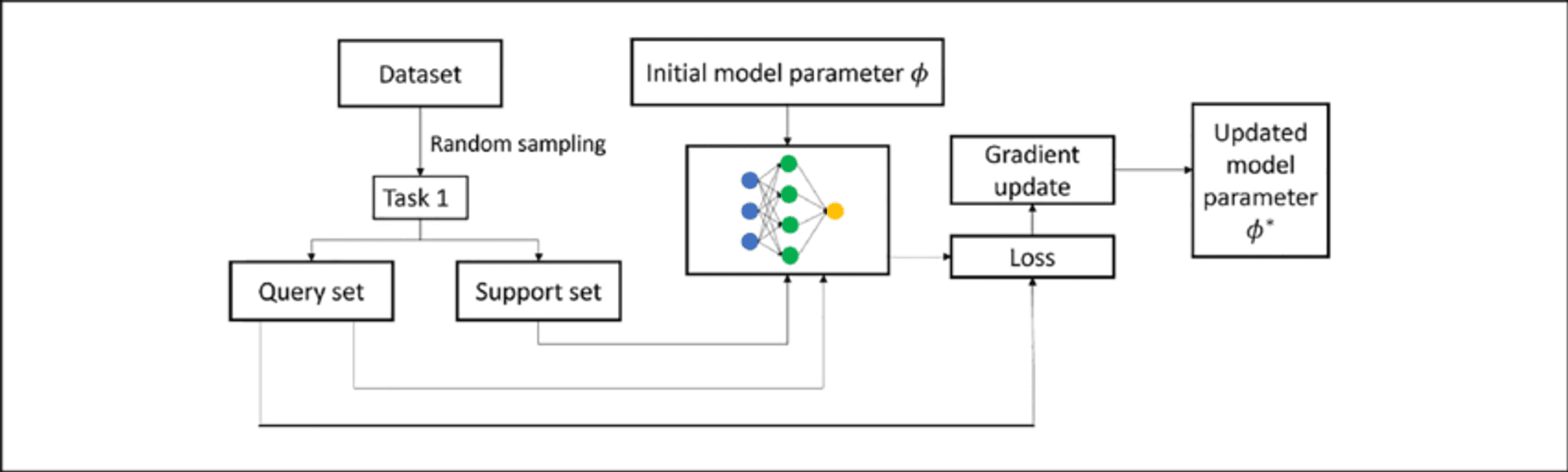
数ショットの微調整テクニック
Few-shot fine-tuning adapts the model using only 10 to 100 samples per class or task, valuable when labeled data is scarce. Key techniques include:
プロンプトベースの微調整: Combines few-shot prompting with parameter updates.
メタ学習アプローチ: Methods like MAML aim to find good initialization points for quick adaptation.
Adapter-based fine-tuning: Introduces small “adapter” modules between pre-trained model layers, reducing trainable parameters.
インコンテクスト学習: Fine-tunes LLMs to better perform adaptation through prompts alone.
These techniques enable LLMs to adapt to new tasks with minimal data, enhancing their versatility and efficiency.
数発のプロンプティングと微調整:正しいアプローチの選択
LLMを特定のタスクに適応させる場合、数発のプロンプトと微調整の両方が強力な解決策を提供する。しかし、それぞれの方法には長所と限界があり、適切なアプローチを選択するかどうかはさまざまな要因に左右される。
Few-Shot Prompting Strengths:
モデルのパラメータを更新する必要がなく、元のモデルを維持できる。
柔軟性が高く、その場で適応可能
追加のトレーニング時間や計算リソースは不要
迅速なプロトタイピングや実験に役立つ
制限事項:
特に複雑な作業では、パフォーマンスが安定しないことがある。
モデル本来の能力と知識による制限
専門性の高い領域や業務に苦戦する可能性がある
Fine-Tuning Strengths:
多くの場合、特定のタスクでより良いパフォーマンスを達成する
新しいドメインや専門的な語彙にモデルを適応させることができる
同じようなインプットでより一貫した結果
継続的な学習と改善の可能性
制限事項:
追加のトレーニング時間と計算リソースが必要
注意深く管理しなければ、大惨事を引き起こす危険性がある。
小さなデータセットではオーバーフィットする可能性がある
柔軟性に欠け、大幅なタスク変更には再トレーニングが必要
Top 5 Research Papers for Few-Shot Learning
This week, we also explore the following five papers that have significantly advanced this field, introducing innovative approaches that are reshaping AI capabilities.

1️⃣ Matching Networks for One Shot Learning” (Vinyals et al., 2016)
Introduced a groundbreaking approach using memory and attention mechanisms. The matching function compares query examples to labeled support examples, setting a new standard for few-shot learning methods.
2️⃣ Prototypical Networks for Few-shot Learning” (Snell et al., 2017)
Presented a simpler yet effective approach, learning a metric space where classes are represented by a single prototype. Its simplicity and effectiveness made it a popular baseline for subsequent research.
3️⃣ Learning to Compare: Relation Network for Few-Shot Learning” (Sung et al., 2018)
Introduced a learnable relation module, allowing the model to learn a comparison metric tailored to specific tasks and data distributions. Demonstrated strong performance across various benchmarks.
4️⃣ A Closer Look at Few-shot Classification” (Chen et al., 2019)
Provided a comprehensive analysis of existing methods, challenging common assumptions. Proposed simple baseline models that matched or exceeded more complex approaches, emphasizing the importance of feature backbones and training strategies.
5️⃣ Meta-Baseline: Exploring Simple Meta-Learning for Few-Shot Learning” (Chen et al., 2021)
Combined standard pre-training with a meta-learning stage, achieving state-of-the-art performance. Highlighted the trade-offs between standard training and meta-learning objectives.
These papers have not only advanced academic research but also paved the way for practical applications in enterprise AI. They represent a progression towards more efficient, adaptable AI systems capable of learning from limited data – a crucial capability in many business contexts.
結論
Few-shot learning, prompting, and fine-tuning represent groundbreaking approaches, enabling LLMs to adapt swiftly to specialized tasks with minimal data. As we’ve explored, these techniques offer unprecedented flexibility and efficiency in tailoring LLMs to diverse applications across industries, from enhancing natural language processing tasks to enabling domain-specific adaptations in fields like healthcare, law, and technology.
AI & YOU』をお読みいただきありがとうございます!
インフォグラフィックス、統計、ハウツーガイド、記事、ビデオなど、エンタープライズAIに関するその他のコンテンツについては、Skim AIをフォローしてください。 LinkedIn
創業者、CEO、ベンチャーキャピタル、投資家の方で、AIアドバイザリー、AI開発、デューデリジェンスのサービスをお探しですか?貴社のAI製品戦略や投資機会について、十分な情報に基づいた意思決定を行うために必要なガイダンスを得ることができます。
企業向けAIソリューションの立ち上げにお困りですか?当社のAIワークフォースマネジメント・プラットフォームを使用して独自のAI労働者を構築することをお考えですか?ご相談ください
ベンチャーキャピタルやプライベートエクイティが支援する以下の業界の企業向けに、カスタムAIソリューションを構築しています:医療テクノロジー、ニュース/コンテンツアグリゲーション、映画/写真制作、教育テクノロジー、リーガルテクノロジー、フィンテック&暗号通貨。


