
ChainPollのためのAI研究論文内訳:LLM幻覚検出のための有効性の高い方法



この記事では、大規模言語モデル(LLM)が直面する最も差し迫った課題の一つである「幻覚」を取り上げた重要な研究論文を紹介する。論文のタイトルは"ChainPoll:LLM幻覚検出のための有効性の高い方法AIが生み出す不正確さを特定し、軽減するための斬新なアプローチを紹介する。
Galileo Technologies Inc.の研究者が執筆したChainPoll論文は、LLM出力の幻覚を検出するための新しい手法を提示している。ChainPollと名付けられたこの手法は、精度と効率の両方で既存の代替手法を凌駕している。さらに、この論文では、従来のベンチマークよりも効果的に幻覚検出メトリクスを評価するために設計された、慎重にキュレートされたベンチマークデータセット群であるRealHallを紹介しています。
LLMにおける幻覚とは、これらのAIモデルが、事実と異なる、無意味な、あるいは入力データと無関係なテキストを生成する事例を指す。チャットボットからコンテンツ作成ツールに至るまで、LLMがさまざまなアプリケーションにますます統合されるにつれ、こうした幻覚によって誤った情報が伝播するリスクは指数関数的に高まっている。この問題は、AIが生成するコンテンツの信頼性と信用性に大きな課題を突きつけている。
AIシステムの責任ある導入には、幻覚を正確に検出し軽減する能力が不可欠である。本研究は、このようなエラーを特定するためのより強固な方法を提供し、AIが生成するコンテンツの信頼性を向上させ、AIアプリケーションに対するユーザーの信頼を高め、AIシステムを通じて誤った情報が広まるリスクを低減することにつながる。幻覚問題に取り組むことで、本研究は、様々な業界において、より信頼性の高い、信頼できるAIアプリケーションへの道を開く。

背景と問題提起
LLMの出力から幻覚を検出するのは、いくつかの要因から複雑な作業である。LLMが生成するテキストの量は膨大であり、幻覚はしばしば微妙な性質を持つため、正確な情報と区別することが難しい。さらに、多くの幻覚は文脈に依存する性質があり、生成されたすべてのコンテンツをチェックするための包括的な「グランドトゥルース」がないことが、検出プロセスをさらに複雑にしている。
ChainPollの論文が発表される以前、既存の幻覚検出手法はいくつかの限界に直面していた。その多くは、多様なタスクや領域において有効性に欠け、また、リアルタイムでの応用には計算コストがかかりすぎるものもあった。また、特定のモデル・アーキテクチャや学習データに依存する手法もあり、事実誤認と文脈誤認など、異なるタイプの幻覚を区別するのに苦労するものがほとんどだった。
さらに、これらの手法を評価するために使用されるベンチマークは、実世界のアプリケーションにおいて最先端のLLMがもたらす真の課題を反映していないことが多かった。その多くは、古くて弱いモデルに基づいていたり、LLMの能力や潜在的な幻覚の全容を表していない、狭く特定のタスクに焦点を当てていたりした。
こうした問題に対処するため、ChainPoll論文の研究者たちは2つのアプローチをとった:
より効果的な新しい幻覚検出法を開発(ChainPoll)
より適切で挑戦的なベンチマーク・スイートの作成(リアルホール社)
この包括的なアプローチは、幻覚の検出を改善するだけでなく、異なる検出方法を評価・比較するための、より強固な枠組みを確立することを目的としている。
論文の主な貢献
ChainPollの論文は、AIの研究開発分野に3つの主要な貢献をしており、それぞれが幻覚検出の課題の重要な側面に取り組んでいる。
まず、ChainPollを紹介する。ChainPollは、新しい幻覚検出方法論である。ChainPollは、幻覚を識別するためにLLM自体の力を活用し、精度と信頼性を向上させるために注意深く設計されたプロンプト技術と集計方法を使用する。より詳細で体系的な説明を引き出すために思考連鎖プロンプトを採用し、信頼性を高めるために検出プロセスを複数回繰り返し、オープンドメインとクローズドドメインの両方の幻覚検出シナリオに適応する。
第二に、既存のベンチマークの限界を認識し、著者らはRealHallを開発した。RealHallは、新しいベンチマーク・データセット群である。RealHallは、幻覚検出手法のより現実的で挑戦的な評価を提供するように設計されている。最先端のLLMにとっても挑戦的な4つの厳選されたデータセットで構成され、実世界のLLMアプリケーションに関連するタスクに焦点を当て、オープンドメインとクローズドドメインの両方の幻覚シナリオをカバーしている。
最後に、ChainPollを既存のさまざまな幻覚検出方法と徹底的に比較する。 この包括的な評価では、新しく開発されたRealHallベンチマーク・スイートを使用し、この分野で確立された指標と最近の革新的な技術の両方を含み、精度、効率、費用対効果などの要素を考慮している。この評価を通じて、様々なタスクや幻覚のタイプにわたってチェーンポールの優れた性能を実証している。
これら3つの重要な貢献を提供することで、ChainPoll論文は幻覚検出の技術的な現状を前進させるだけでなく、AIの安全性と信頼性の重要な領域であるこの分野における将来の研究開発により強固な枠組みを提供する。
ChainPollの手法を探る
ChainPollの核心は、AIが生成したテキストの幻覚を識別するために、大規模な言語モデル自体の能力を活用することである。このアプローチは、そのシンプルさ、有効性、さまざまなタイプの幻覚に対する適応性で際立っている。
ChainPollの仕組み
ChainPollメソッドは、簡単かつ強力な原理で動作する。LLM(具体的には、論文の実験ではGPT-3.5-turbo)を使って、与えられたテキスト補完に幻覚が含まれているかどうかを評価する。
このプロセスには3つの重要なステップがある:
まず、システムはLLMに、注意深く操作された「幻覚」を使って、対象テキストに幻覚があるかどうかを評価するよう促す。 迅速.
次に、このプロセスを複数回、通常は5回繰り返し、信頼性を確保する。
最後に、システムは「はい」の回答数(幻覚の存在を示す)を回答総数で割ってスコアを算出する。
このアプローチにより、ChainPollはLLMの言語理解能力を活用しながら、集計によって個々の評価エラーを軽減することができる。
思考の連鎖を促す役割
ChainPollの重要な革新点は、思考連鎖(CoT)プロンプトの使用である。この技法は、ある文章に幻覚が含まれているかどうかを判断する際に、LLMにその推論を段階的に説明するよう促すものである。著者らは、慎重に設計された「詳細なCoT」プロンプトが、より体系的で信頼できる説明をモデルから一貫して引き出すことを発見した。
CoTを組み込むことで、ChainPollは幻覚検出の精度を向上させるだけでなく、モデルの意思決定プロセスに対する貴重な洞察を提供する。この透明性は、特定のテキストに幻覚が含まれているとフラグが立てられる理由を理解する上で極めて重要であり、将来的にはよりロバストなLLMの開発に役立つ可能性がある。
開領域幻覚と閉領域幻覚の区別
ChainPollの強みの一つは、オープンドメインの幻覚とクローズドドメインの幻覚の両方に対応できることである。オープンドメインの幻覚は、世界一般についての誤った主張を指し、クローズドドメインの幻覚は、特定の参照テキストや文脈との矛盾を含む。
これらの異なるタイプの幻覚を扱うために、著者らはChainPollの2つの変種を開発した: オープンドメインの幻覚に対するチェーンポール正しさ そして クローズドドメインの幻覚に対するチェーンポール・アドヒアランス.これらのバリエーションは、主にプロンプト戦略が異なり、ChainPollの中核となる手法を維持しながら、異なる評価コンテキストに適応できるようになっている。
リアルホール ベンチマーク・スイート
著者らは、既存のベンチマークの限界を認識し、より現実的で困難な幻覚検出法の評価を提供するために設計された新しいベンチマーク・スイート、RealHallも開発した。
データセット選択の基準(チャレンジ、リアリズム、タスクの多様性)
リアルホールの設立は、3つの重要な原則によって導かれた:
チャレンジだ: このデータセットは、最先端のLLMにとっても大きな困難をもたらすはずであり、モデルの改良が進んでもベンチマークが適切であり続けることを保証する。
リアリズム: タスクは、LLMの実世界でのアプリケーションを忠実に反映したものであるべきで、ベンチマークの結果をより実用的なシナリオに適用できるようにする。
タスクの多様性: このスイートは、LLMの幅広い能力をカバーし、幻覚検出法の包括的な評価を提供するものでなければならない。
これらの基準から、幻覚検出手法の確かな実験場となる4つのデータセットが選ばれた。
RealHallの4つのデータセットの概要
RealHallは2組のデータセットで構成され、それぞれが幻覚検出の異なる側面を扱っている:
リアルホール閉店: このペアには、COVID-QA with retrievalデータセットとDROPデータセットが含まれる。これらはクローズドドメインの幻覚に焦点を当て、提供された参照テキストとの整合性を保つモデルの能力をテストする。
リアルホール・オープン このペアは、Open Assistant promptsデータセットとTriviaQAデータセットからなる。これらはオープンドメインの幻覚を対象としており、モデルが世界について誤った主張をするのを避ける能力を評価する。
RealHallの各データセットは、そのユニークな課題と実世界のLLMアプリケーションとの関連性から選ばれた。例えば、COVID-QAデータセットは、検索による生成シナリオを模倣し、DROPは離散推論能力をテストする。
RealHallはどのように以前のベンチマークの限界に対処しているか
RealHallは、いくつかの点で、以前のベンチマークより大幅に改善されている。第一に、より新しく強力なLLMを使用して応答を生成するため、検出される幻覚が現在の最新モデルによって生成されたものを代表することが保証される。これは、簡単に検出可能な幻覚を生成する時代遅れのモデルを使用した古いベンチマークによく見られる問題に対処するものである。
第二に、RealHallはタスクの多様性とリアリズムに重点を置いているため、幻覚検出手法のより包括的で実用的な評価が可能である。これは、狭く特定のタスクや人工的なシナリオに焦点を当てた、これまでの多くのベンチマークとは対照的である。
最後に、オープン・ドメインとクローズド・ドメインの両方のタスクを含むことで、RealHallは幻覚検出方法のより微妙な評価を可能にする。これは、実世界のLLMアプリケーションの多くが、両方のタイプの幻覚検出を必要とするため、特に重要である。
これらの改善により、RealHallは幻覚検出法を評価するための、より厳密で適切なベンチマークを提供し、この分野における新たな基準を打ち立てた。
実験結果と分析
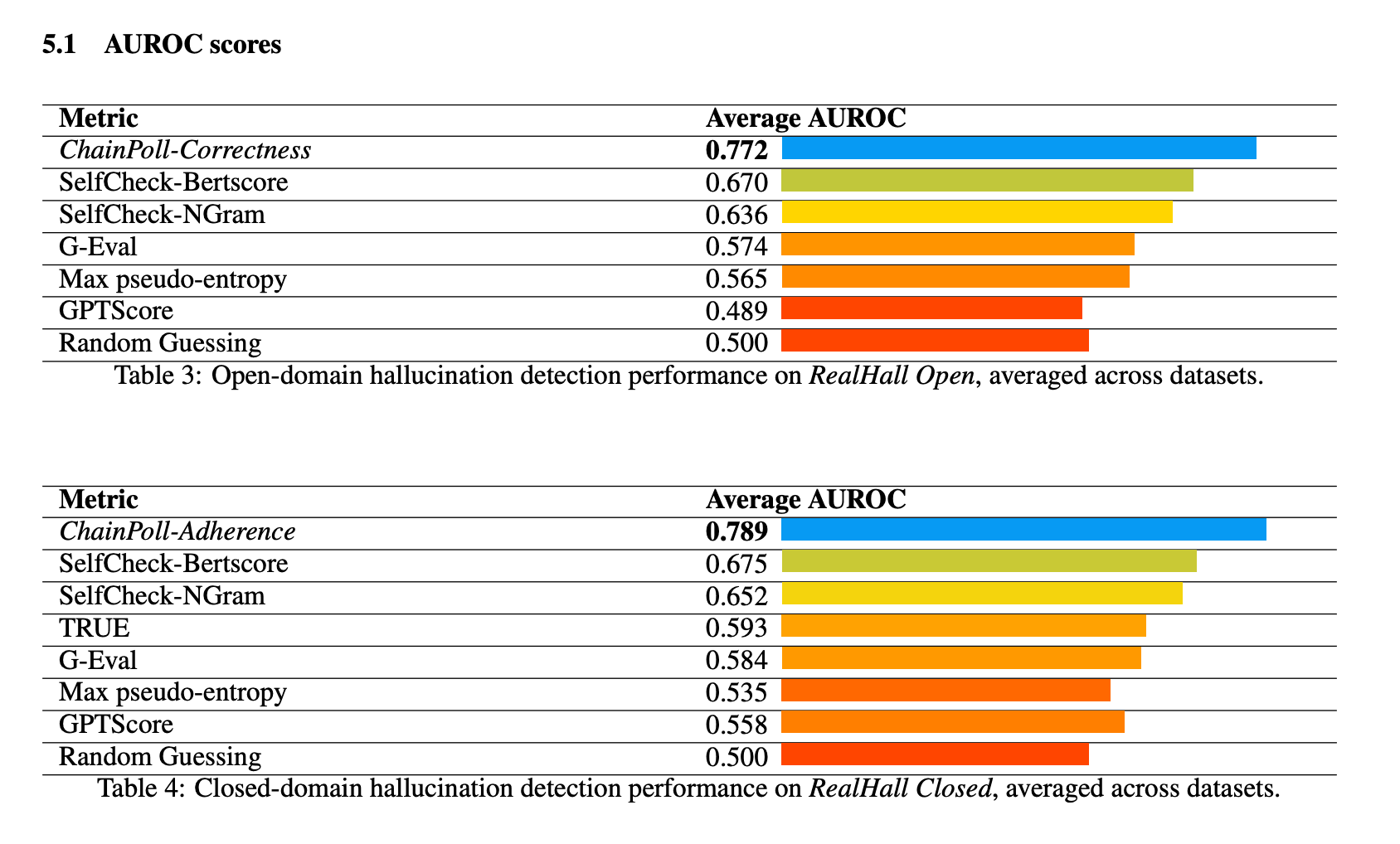
ChainPollは、RealHallスイートの全ベンチマークで優れたパフォーマンスを示した。ChainPollはAUROC(Receiver Operating Characteristic曲線下面積)0.781を達成し、次点のSelfCheck-BertScoreの0.673を大きく上回った。10%を上回るこの大幅な改善は、幻覚検出能力の大きな飛躍を意味する。
テストされた他の手法には、SelfCheck-NGram、G-Eval、GPTScoreが含まれるが、いずれもChainPollより顕著に成績が悪かった。興味深いことに、GPTScoreのような以前の研究で有望視されていたいくつかの手法は、より困難で多様なRealHallベンチマークでは低調な結果となった。

ChainPollの性能は、オープンドメインの幻覚検出タスクとクローズドドメインの幻覚検出タスクの両方で一貫して強力であった。オープンドメインのタスク(ChainPoll-Correctnessを使用)では、平均AUROC 0.772を達成し、クローズドドメインのタスク(ChainPoll-Adherenceを使用)では、0.789を記録した。
この方法は、離散推論を必要とするDROPのような困難なデータセットで特に強さを発揮した。
ChainPollは、その優れた精度だけでなく、多くの競合手法よりも効率的で費用対効果が高いことも証明した。ChainPollは、次善の方法であるSelfCheck-BertScoreの1/4のLLM推論量しか使用せずに結果を達成した。さらに、ChainPollはBERTのような追加モデルを使用する必要がないため、計算オーバーヘッドをさらに削減することができます。
この効率は、実用的なアプリケーションにとって極めて重要である。なぜなら、法外なコストや待ち時間を発生させることなく、生産環境におけるリアルタイムの幻覚検出を可能にするからである。
意味合いと今後の課題
ChainPollは、LLMの幻覚検出の分野における大きな進歩を意味する。この成功は、AIの安全性と信頼性を向上させるツールとしてLLMそのものを利用する可能性を示している。このアプローチは、自己改善・自己チェックAIシステムの研究に新たな道を開くものである。
ChainPollの効率性と正確性は、幅広いAIアプリケーションへの統合に適している。チャットボットの信頼性を高めたり、ジャーナリズムやテクニカルライティングのような分野でAIが生成するコンテンツの精度を高めたり、ヘルスケアや金融のような重要な領域でAIアシスタントの信頼性を高めたりするために使用できるだろう。
ChainPollは印象的な結果を示しているが、さらなる研究と改善の余地はまだある。今後の課題としては
より幅広いLLMと言語タスクに対応するためのChainPollの適応
正確さを犠牲にすることなく、効率をさらに向上させる方法を検討する。
テキスト以外のAI生成コンテンツに対するChainPollの可能性を探る
幻覚を発見するだけでなく、リアルタイムで修正したり予防したりする方法を開発する。
ChainPoll論文は、新しい幻覚検出手法と、よりロバストな評価ベンチマークの導入を通じて、AIの安全性と信頼性の分野に大きく貢献している。オープンドメインとクローズドドメインの両方の幻覚を検出する優れた性能を実証することで、ChainPollはより信頼性の高いAIシステムへの道を開く。LLMが様々なアプリケーションでますます重要な役割を果たすようになるにつれ、幻覚を正確に検出し、軽減する能力は極めて重要になります。この研究は、我々の現在の能力を向上させるだけでなく、AIの幻覚検出という重要な分野における将来の探求と開発のための新たな道を開くものである。


