
LLMの費用を削減する10の実証済みの戦略 - AI&YOU #65



今週のスタッツ GPT-Jのような小さなLLMをカスケードで使用することで、GPT-4と比較して1.5%精度を向上させながら、全体のコストを80%削減できる。(Dataiku)
組織がさまざまなアプリケーションで大規模な言語モデル(LLM)にますます依存するようになるにつれ、適切な監視と最適化戦略がなければ、LLMの導入と維持に伴う運用コストはあっという間に制御不能に陥る可能性があります。
MetaはLlama 3.1もリリースしており、オープンソースのLLMとしてはこれまでで最も先進的だと最近話題になっている。
今週のAI&YOUでは、私たちが公開した3つのブログから得た洞察を紹介します:
LLMの費用を削減する10の実証済みの戦略 - AI&YOU #65
今週は、企業がLLMのコストを効果的に管理し、コスト効率と経費管理を維持しながら、これらのモデルの可能性を最大限に活用できるようにするための、実証済みの10の戦略を探る。
1.スマートなモデル選択
モデルの複雑さをタスク要件に注意深く適合させることで、LLMコストを最適化します。すべてのアプリケーションに最新で最大のモデルが必要なわけではありません。基本的な分類や単純なQ&Aのような単純なタスクには、より小さく効率的な事前学習済みモデルを使用することを検討してください。このアプローチは、パフォーマンスを損なうことなく、大幅なコスト削減につながります。
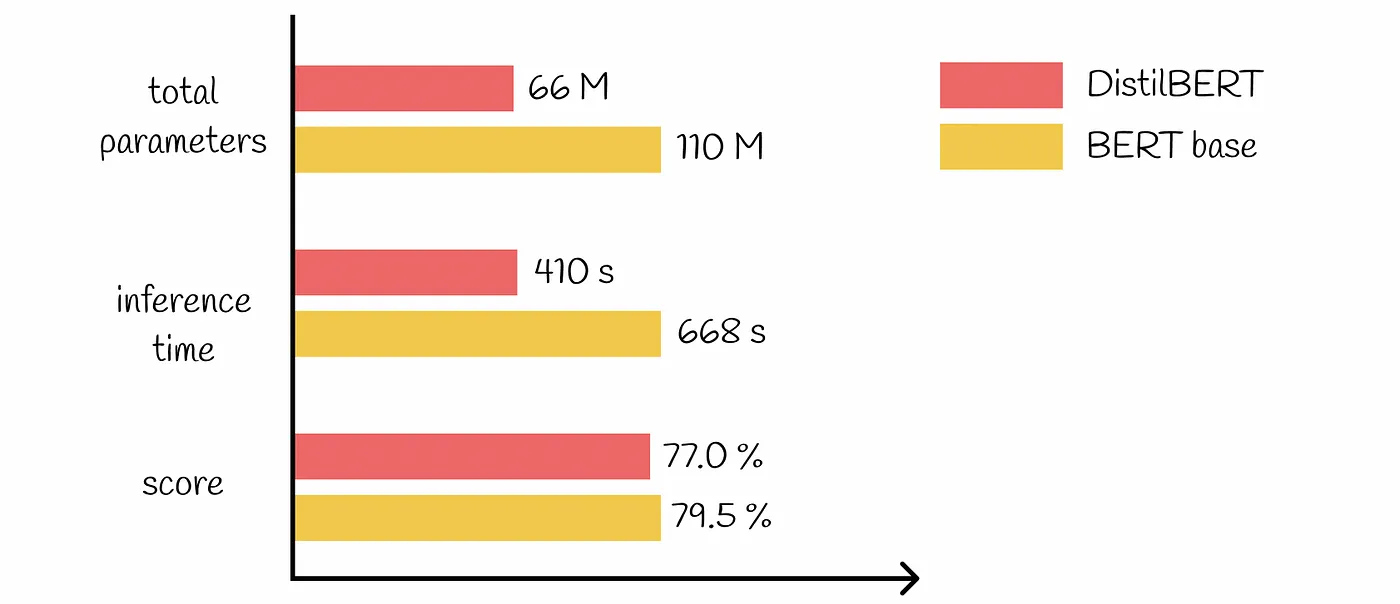
例えば、BERT-Largeの代わりにDistilBERTをセンチメント分析に使用することで、計算オーバーヘッドと関連費用を大幅に削減できる一方で、手元の特定のタスクに対して高い精度を維持することができます。
2.堅牢な利用状況追跡の導入
あなたの会社について包括的な見解を得る LLMの利用 マルチレベルのトラッキングメカニズムトークンの使用状況、レスポンスタイム、モデルコールを会話、ユーザー、会社の各レベルで監視します。LLMプロバイダーのビルトイン分析ダッシュボードを活用するか、インフラストラクチャと統合されたカスタムトラッキングソリューションを実装します。
このきめ細かな洞察により、単純なタスクに高価なモデルを使いすぎている部門や、冗長なクエリのパターンなど、非効率を特定することができます。このデータを分析することで、貴重なコスト削減戦略を発見し、LLMの消費量全体を最適化することができます。
3.プロンプトエンジニアリングの最適化
プロンプトエンジニアリングのテクニックを磨くことで、トークンの使用量を大幅に削減し、LLMの効率を向上させます。プロンプトに明確で簡潔な指示を作成し、追加クエリなしで一般的な問題に対処するためのエラー処理を実装し、特定のタスクのために実績のあるプロンプトテンプレートを利用します。不要な文脈を避け、箇条書きのような書式設定テクニックを使用し、組み込み関数を活用して出力の長さを制御することで、プロンプトを効率的に構成します。
これらの最適化により、トークンの消費量と関連コストを大幅に削減しながら、LLM出力の品質を維持、あるいは向上させることができます。
4.専門化のための微調整を活用する
微調整の力を使って、特定のニーズに合わせたより小型で効率的なモデルを作る。初期投資は必要ですが、このアプローチは長期的に大きな節約につながります。ファインチューニングされたモデルは、同等またはそれ以上の結果を得るために、より少ないトークンで済むことが多く、推論コストを削減し、再試行や修正の必要性を低減します。
事前に訓練された小規模なモデルから開始し、微調整のために高品質なドメイン固有のデータを使用し、パフォーマンスとコスト効率を定期的に評価します。この継続的な最適化により、運用コストを抑えながらモデルの価値を継続的に高めることができます。
5.無料・低料金のオプションを探す
無料または低コストのLLMオプションを活用することで、特に開発およびテストフェーズにおいて、品質を損なうことなく費用を大幅に削減することができます。このような選択肢は、プロトタイピング、開発者のトレーニング、クリティカルでないサービスや内部向けのサービスにおいて特に価値があります。
ただし、データのプライバシー、セキュリティへの影響、機能やカスタマイズの潜在的な制限を考慮し、トレードオフを慎重に評価する必要があります。長期的なスケーラビリティと移行経路を評価し、コスト削減策が将来の成長計画に合致し、将来的に障害とならないようにする。
6.コンテキストウィンドウ管理の最適化
コンテキストウィンドウを効果的に管理し、出力品質を維持しながらコストをコントロールする。タスクの複雑性に基づいた動的なコンテキストのサイズ設定を実装し、要約技術を使って関連情報を凝縮し、長い文書や会話にはスライディングウィンドウアプローチを採用する。コンテキストサイズと出力品質の関係を定期的に分析し、特定のタスク要件に基づいてウィンドウを調整する。
段階的なアプローチを検討し、必要なときだけ大きなコンテキストを使用する。このようにコンテキスト・ウィンドウを戦略的に管理することで、LLMアプリケーションの理解能力を犠牲にすることなく、トークンの使用量と関連コストを大幅に削減することができます。
7.マルチエージェントシステムの導入
マルチエージェントLLMアーキテクチャを実装することで、効率性と費用対効果を高める。このアプローチでは、複雑な問題を解決するために複数のAIエージェントが協力することで、リソースの割り当てを最適化し、高価で大規模なモデルへの依存を減らすことができます。
マルチエージェントシステムは、ターゲットを絞ったモデル展開を可能にし、トークンの使用量を削減しながら、システム全体の効率と応答時間を改善します。コスト効率を維持するために、エージェント間通信のロギングやトークン使用パターンの分析など、堅牢なデバッグメカニズムを実装します。
エージェント間の役割分担を最適化することで、不要なトークンの消費を最小限に抑え、分散タスク処理のメリットを最大限に生かすことができます。
8.出力フォーマットツールの活用
トークンを効率的に使用し、追加処理の必要性を最小限に抑えるために、出力フォーマットツールを活用します。正確なレスポンス・フォーマットを指定する強制関数出力を実装し、ばらつきとトークンの無駄を減らします。このアプローチにより、不正な出力の可能性が減少し、明確なAPIコールの必要性が減少します。
構造化データのコンパクトな表現、容易な構文解析、自然言語レスポンスと比較したトークン使用量の削減を実現するJSON出力の使用をご検討ください。これらのフォーマットツールを使用してLLMワークフローを合理化することにより、高品質の出力を維持しながら、トークンの使用量を大幅に最適化し、運用コストを削減することができます。
9.LLM以外のツールの統合
LLMアプリケーションをLLM以外のツールで補完し、コストと効率を最適化します。単純なデータ処理やルールベースの意思決定など、LLMの全機能を必要としないタスクには、Pythonスクリプトや従来のプログラミングアプローチを組み込みます。
ワークフローを設計する際には、タスクの複雑さ、要求される精度、潜在的なコスト削減に基づいて、LLMと従来のツールのバランスを慎重にとる。開発コスト、処理時間、精度、長期的なスケーラビリティなどの要素を考慮し、徹底的なコスト・ベネフィット分析を行う。このハイブリッド・アプローチは、性能とコスト効率の両面で最良の結果をもたらすことが多い。
10.定期的な監査と最適化
継続的なLLMコスト管理を確実にするために、定期的な監査と最適化の強固なシステムを導入する。LLMの使用状況を常に監視・分析し、冗長なクエリや過剰なコンテキスト・ウィンドウなどの非効率を特定します。追跡・分析ツールを使用してLLM戦略を改善し、不要なトークン消費を排除します。
LLMの使用によるコストへの影響を積極的に検討し、最適化の機会を模索するようチームに奨励し、組織内でコストを意識する文化を醸成する。コスト効率を共有責任とすることで、AI投資の価値を最大化しつつ、長期的に費用を抑制することができる。
LLMの価格体系を理解する:インプット、アウトプット、コンテクスト・ウィンドウ
企業のAI戦略にとって、LLMの価格体系を理解することは、効果的なコスト管理のために極めて重要である。LLMに関連する運用コストは、適切な監視が行われないとすぐに膨れ上がる可能性があり、予期せぬコスト高騰を招き、予算を狂わせ、普及を妨げる可能性がある。
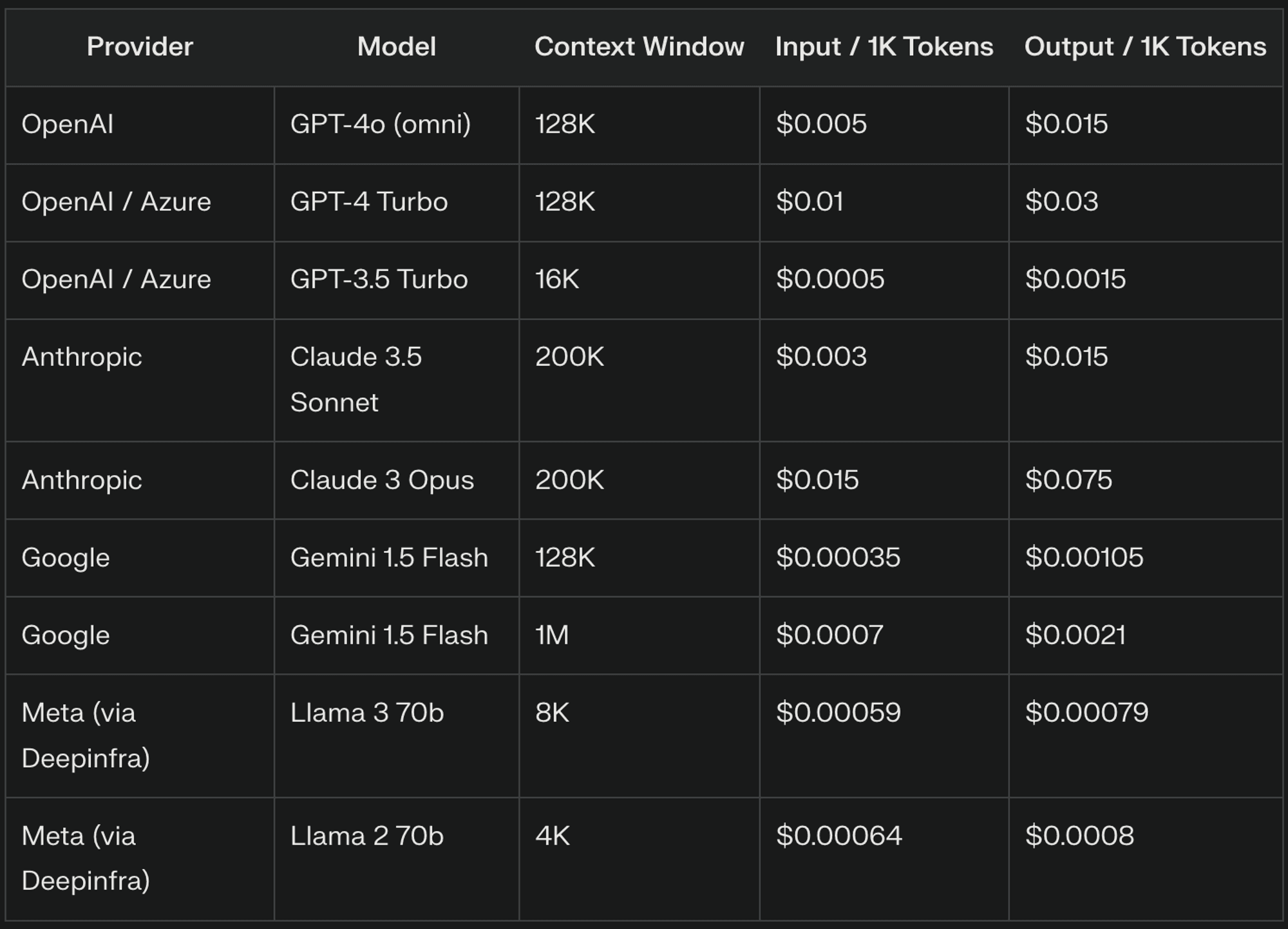
LLMの価格設定は通常、3つの主要な要素を中心に展開される: 入力トークン、出力トークン、コンテキスト・ウィンドウ。 これらの各要素は、LLMを活用する際の全体的なコストを決定する上で重要な役割を果たします。
インプット・トークン:インプットトークンとは何か?
入力トークンはLLMが処理するテキストの基本単位で、通常は単語の一部に対応する。たとえば、"The quick brown fox" は ["The", "quick", "bro", "wn", "fox"] とトークン化され、5 つの入力トークンになります。LLMプロバイダーは一般に、1,000トークンあたりの料金に基づいて入力トークンの料金を請求しますが、その価格はプロバイダーやモデルのバージョンによって大きく異なります。
インプット・トークンの使用を最適化し、コストを削減するには、以下の戦略を検討してください:
簡潔なプロンプトを作成する: 明確で直接的な指示に集中する。
効率的なエンコーディングを使用する: より少ないトークンでテキストを表現するメソッドを選択する。
プロンプト・テンプレートを導入する: 一般的なタスクに最適化された構造を開発する。
圧縮技術を活用する: 重要な情報を失うことなく、入力サイズを縮小。
アウトプットのトークン:コストを理解する
出力トークンは、入力に応じて LLM が生成するテキストを表します。出力トークンの数は、タスクとモデル構成によって大きく異なります。LLM プロバイダーは、テキスト生成の計算の複雑さから、出力トークンの価格を入力トークンよりも高く設定することがよくあります。
出力トークンの使用を最適化し、コストを管理する:
プロンプトまたはAPIコールに明確な出力長制限を設定する。
数発学習」を使って、モデルを簡潔な回答に導く。
不要なコンテンツを削る後処理を実施する。
頻繁にリクエストされる情報のキャッシュを検討する。
トークンを効率的に使用するために、出力フォーマットツールを活用する。
コンテキストウィンドウ隠れたコストドライバー
文脈ウィンドウは、LLMが応答を生成する際に、どの程度前のテキストを考慮するかを決定する。コンテキスト・ウィンドウを大きくすると、処理される入力トークンの数が増え、コストが高くなる。たとえば、8,000トークンのコンテキスト・ウィンドウでは、会話中の7,000トークンに対して課金されるかもしれないが、4,000トークンのウィンドウでは3,000トークンに対してしか課金されないかもしれない。
コンテキストウィンドウの使用を最適化する:
タスク要件に基づく動的なコンテキストのサイジングを実装する。
要約のテクニックを使って、関連する情報を凝縮する。
長い文書にはスライディングウィンドウアプローチを採用する。
限られたコンテキストしか必要としないタスクには、より小型の専用モデルを検討する。
コンテキストの大きさとアウトプットの質の関係を定期的に分析する。
LLMの価格体系を構成するこれらの要素を注意深く管理することで、企業はAIアプリケーションの品質を維持しながら運用コストを削減することができる。
結論
LLMの価格体系を理解することは、企業のAIアプリケーションにおける効果的なコスト管理に不可欠です。入力トークン、出力トークン、コンテキストウィンドウのニュアンスを把握することで、企業はモデルの選択と使用パターンについて十分な情報に基づいた意思決定を行うことができます。トークン使用量の最適化やキャッシュの活用など、戦略的なコスト管理手法を導入することで、大幅なコスト削減が可能になります。
メタのラマ3.1:オープンソースAIの限界に挑む
最近の大きなニュースとして、メタが発表した。 ラマ 3.1は、これまでで最も先進的なオープンソースの大規模言語モデルです。このリリースは、AI技術の民主化における重要なマイルストーンであり、オープンソースとプロプライエタリモデルの間のギャップを埋める可能性があります。
Llama 3.1は、いくつかの重要な進化を遂げ、前作を上回るものとなっている:
モデルサイズの拡大: 405Bパラメータモデルの導入は、オープンソースAIで可能なことの限界を押し広げるものだ。
コンテキストの長さを延長: Llama 2の4KトークンからLlama 3.1の128Kトークンになり、より複雑でニュアンスのある長いテキストの理解が可能になりました。
多言語対応: 言語サポートが拡大されたことで、さまざまな地域やユースケースでより多様なアプリケーションに対応できるようになった。
推理力の向上と専門的な作業: 数学的推論やコード生成などの分野でパフォーマンスが向上。
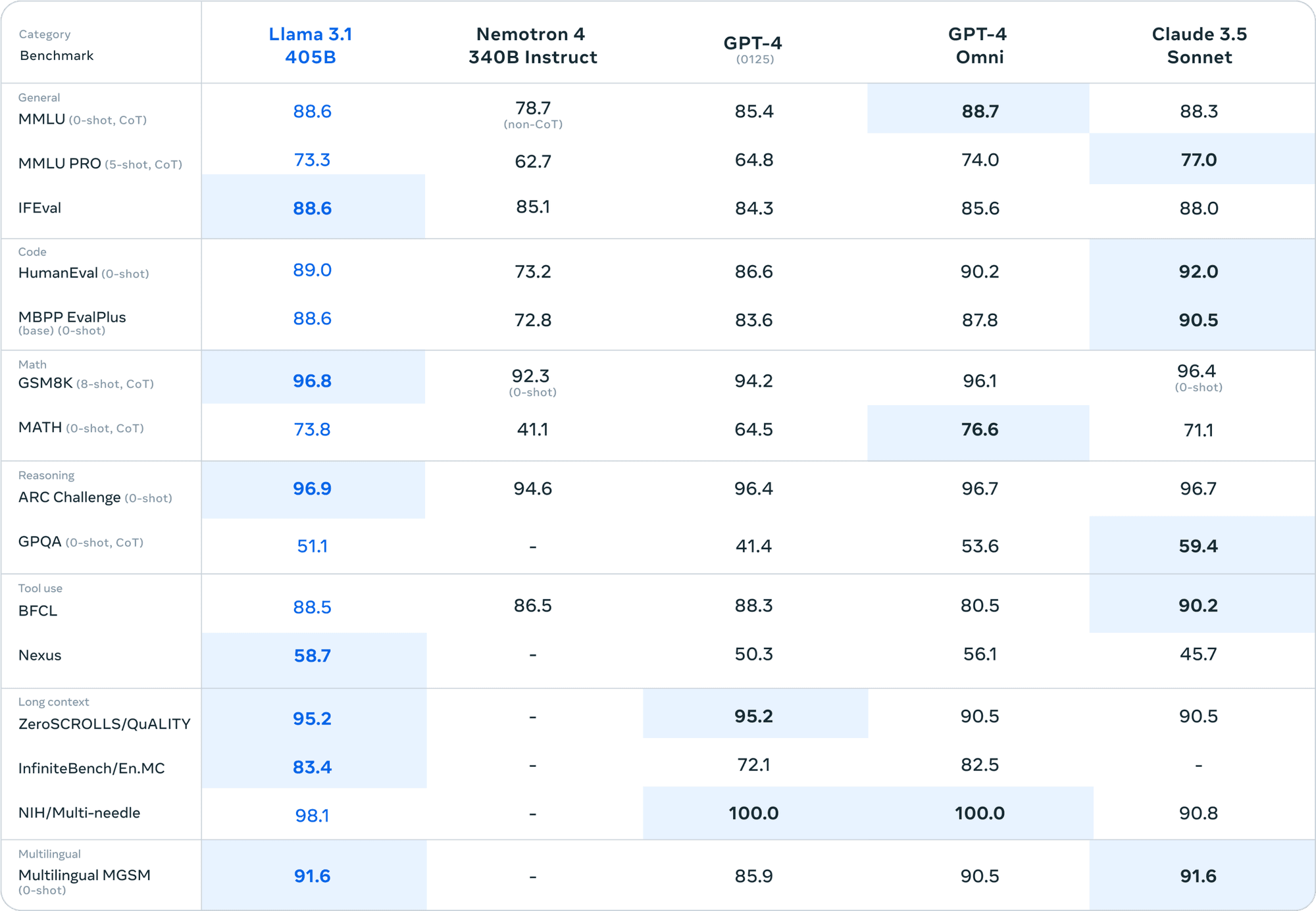
GPT-4やクロード3.5ソネットのようなクローズドソースモデルと比較した場合、ラマ3.1 405Bはさまざまなベンチマークで独自の地位を保っている。オープンソースモデルでこのレベルの性能は前例がない。
ラマ3.1の技術仕様
技術的な詳細に飛び込むと、Llama 3.1は、さまざまなニーズや計算リソースに対応できるよう、さまざまなモデルサイズを提供している:
8Bパラメータモデル: 軽量アプリケーションやエッジデバイスに適している。
70Bパラメータモデル: パフォーマンスとリソース要件のバランス。
405Bパラメータモデル: オープンソースのAI能力の限界に挑むフラッグシップモデル。
Llama 3.1の学習方法には、15兆トークンを超える膨大なデータセットが使用され、前作よりも大幅に大きくなっている。
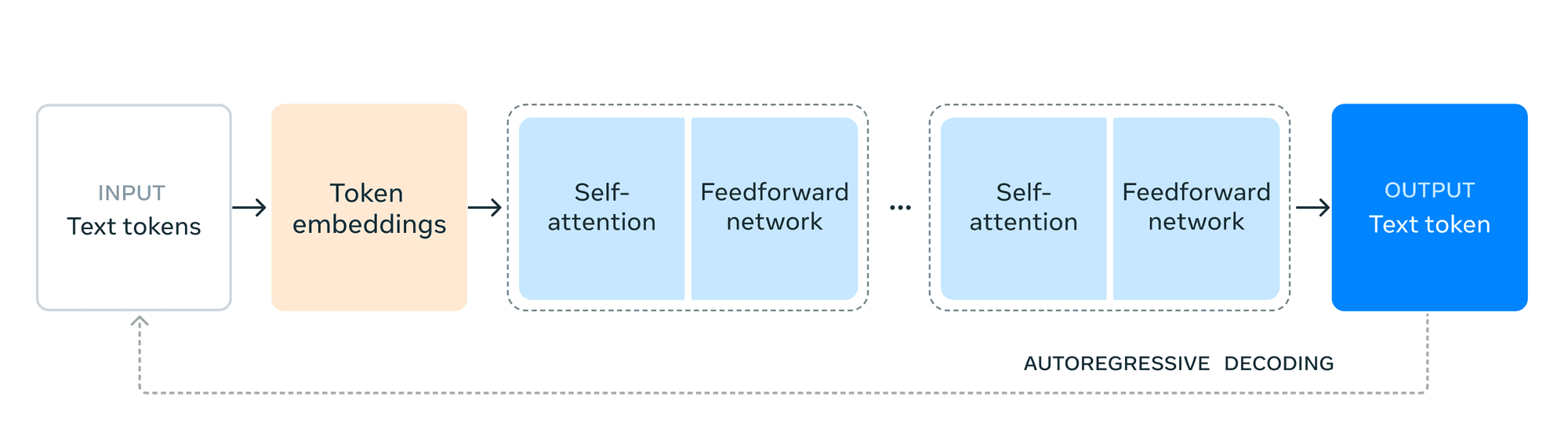
アーキテクチャ上、Llama 3.1はデコーダのみの変換モデルを維持し、mixture-of-expertsのような実験的アプローチよりも学習の安定性を優先している。
しかしMetaは、この前例のないスケールでの効率的な学習と推論を可能にするために、いくつかの最適化を行った:
スケーラブルなトレーニングインフラ: 405Bモデルのトレーニングに16,000以上のH100 GPUを使用。
反復的なポストトレーニングの手順: 特定の能力を強化するために、教師ありの微調整と直接選好最適化を採用。
量子化技術: より効率的な推論のためにモデルを16ビットから8ビットの数値に減らし、シングルサーバーノードでの展開を可能にした。
画期的な能力
Llama 3.1には、AI業界をリードする画期的な機能がいくつか導入されている:
拡張コンテキストの長さ: 128Kのトークン・コンテキスト・ウィンドウへのジャンプは画期的だ。この拡張された容量によって、Llama 3.1はより長いテキストを処理し、理解することができるようになった:
多言語サポート: Llama 3.1は8ヶ国語に対応し、そのグローバルな適用範囲を大幅に広げている。
高度な推論と道具の使用: このモデルは、高度な推論能力と外部ツールを効果的に使用する能力を示している。
コード生成と計算能力:ラマ3.1は、技術的な領域で卓越した能力を発揮します:
複数のプログラミング言語にわたる高品質で機能的なコードの生成
複雑な数学的問題を正確に解く
アルゴリズム設計と最適化の支援
ラマ3.1の期待と可能性
MetaのLlama 3.1のリリースは、AIの展望において極めて重要な瞬間であり、フロンティアレベルのAI能力へのアクセスを民主化する。最先端のパフォーマンス、多言語サポート、拡張されたコンテキストの長さを持つ405Bのパラメータモデルを、すべてオープンソースのフレームワークで提供することで、Metaはアクセス可能でパワフルなAIの新たな基準を打ち立てた。この動きは、クローズドソースモデルの優位性に挑戦するだけでなく、AIコミュニティにおける前例のないイノベーションとコラボレーションへの道を開くものです。
AI & YOU』をお読みいただきありがとうございます!
インフォグラフィックス、統計、ハウツーガイド、記事、ビデオなど、エンタープライズAIに関するその他のコンテンツについては、Skim AIをフォローしてください。 LinkedIn
創業者、CEO、ベンチャーキャピタル、投資家の方で、AIアドバイザリー、AI開発、デューデリジェンスのサービスをお探しですか?貴社のAI製品戦略や投資機会について、十分な情報に基づいた意思決定を行うために必要なガイダンスを得ることができます。
企業向けAIソリューションの立ち上げにお困りですか?当社のAIワークフォースマネジメント・プラットフォームを使用して独自のAI労働者を構築することをお考えですか?ご相談ください
ベンチャーキャピタルやプライベートエクイティが支援する以下の業界の企業向けに、カスタムAIソリューションを構築しています:医療テクノロジー、ニュース/コンテンツアグリゲーション、映画/写真制作、教育テクノロジー、リーガルテクノロジー、フィンテック&暗号通貨。


