
Comprendere le strutture di prezzo LLM: Ingressi, uscite e finestre di contesto



Per le strategie aziendali di intelligenza artificiale, la comprensione delle strutture dei prezzi dei modelli linguistici di grandi dimensioni (LLM) è fondamentale per una gestione efficace dei costi. I costi operativi associati agli LLM possono aumentare rapidamente senza un'adeguata supervisione, portando potenzialmente a picchi di costo inaspettati che possono far deragliare i bilanci e ostacolare l'adozione diffusa. T
Questo post del blog approfondisce le componenti chiave delle strutture tariffarie dei LLM, fornendo spunti che vi aiuteranno a ottimizzare l'utilizzo dei LLM e a controllare le spese.
Il prezzo dell'LLM si articola in genere intorno a tre componenti principali: token di input, token di output e finestre contestuali. Ognuno di questi elementi svolge un ruolo significativo nel determinare il costo complessivo dell'utilizzo degli LLM nelle vostre applicazioni. Grazie a una conoscenza approfondita di questi componenti, sarete in grado di prendere decisioni informate sulla selezione dei modelli, sui modelli di utilizzo e sulle strategie di ottimizzazione.
Componenti di base del tariffario LLM
Gettoni di ingresso
I token di input rappresentano il testo immesso nell'LLM per l'elaborazione. Comprendono le richieste, le istruzioni e qualsiasi altro contesto fornito al modello. Il numero di token di ingresso influisce direttamente sul costo di ogni chiamata API, poiché un numero maggiore di token richiede più risorse computazionali per l'elaborazione.
Gettoni di uscita
I token di output sono il testo generato dal LLM in risposta ai vostri input. Il prezzo dei token di output è spesso diverso da quello dei token di input, in quanto riflette lo sforzo computazionale aggiuntivo richiesto per la generazione del testo. La gestione dell'utilizzo dei token di output è fondamentale per controllare i costi, soprattutto nelle applicazioni che generano grandi volumi di testo.
Finestre contestuali
Le finestre di contesto si riferiscono alla quantità di testo precedente che il modello può considerare quando genera le risposte. Finestre di contesto più ampie consentono una comprensione più completa, ma hanno un costo più elevato a causa dell'aumento dell'uso dei token e dei requisiti computazionali.
Gettoni di ingresso: Cosa sono e come vengono addebitati
I token di input sono le unità fondamentali del testo elaborato da un LLM. In genere corrispondono a parti di parole, con parole comuni spesso rappresentate da un singolo token e parole meno comuni suddivise in più token. Ad esempio, la frase "The quick brown fox" potrebbe essere tokenizzata come ["The", "quick", "bro", "wn", "fox"], ottenendo così 5 token di input.
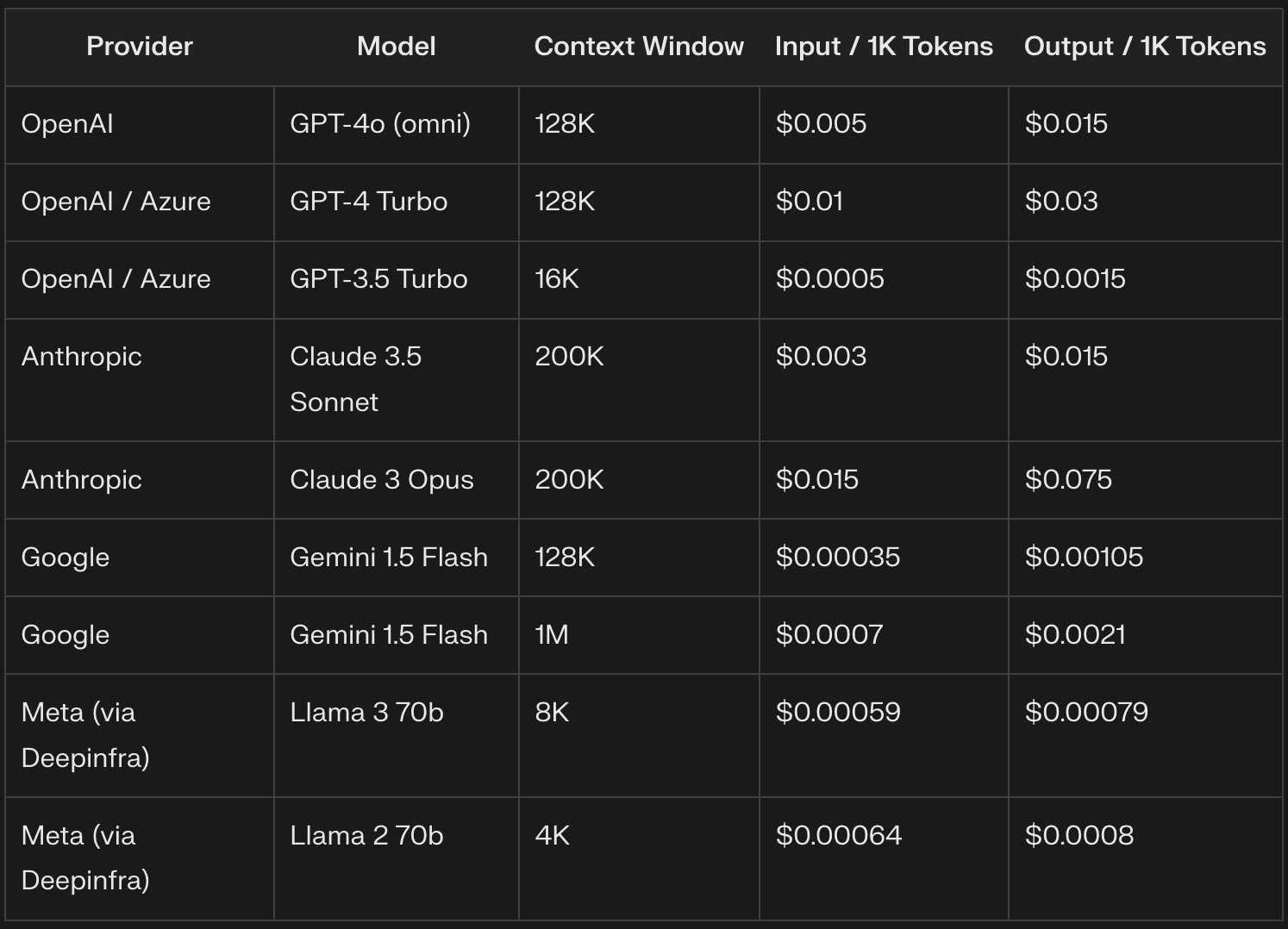
I fornitori di LLM spesso addebitano i gettoni di ingresso in base a una tariffa per migliaia di gettoni. Ad esempio, GPT-4o addebita $5 per 1 milione di gettoni di ingresso, che equivale a $0,005 per 1.000 gettoni di ingresso. I prezzi esatti possono variare in modo significativo tra i fornitori e le versioni del modello, con i modelli più avanzati che generalmente richiedono tariffe più elevate.
Per gestire efficacemente i costi dell'LLM, considerate queste strategie per ottimizzare l'uso dei token di ingresso:
Creare suggerimenti concisi: Eliminate le parole inutili e concentratevi su istruzioni chiare e dirette.
Utilizzare una codifica efficiente: Scegliere un metodo di codifica che rappresenti il testo con un numero inferiore di token.
Implementare i modelli di richiesta: Sviluppare e riutilizzare strutture di prompt ottimizzate per compiti comuni.
Grazie a un'attenta gestione dei token di input, è possibile ridurre in modo significativo i costi associati all'uso di LLM, mantenendo la qualità e l'efficacia delle applicazioni di IA.
Gettoni di uscita: Comprendere i costi
I token di output rappresentano il testo generato dal LLM in risposta all'input dell'utente. Come i token di input, anche quelli di output sono calcolati in base al processo di tokenizzazione del modello. Tuttavia, il numero di token di output può variare in modo significativo a seconda del compito e della configurazione del modello. Ad esempio, una semplice domanda può generare una risposta breve con pochi token, mentre una richiesta di spiegazione dettagliata può produrre centinaia di token.
I fornitori di LLM spesso applicano prezzi diversi per i token di output rispetto a quelli di input, in genere con una tariffa più alta a causa della complessità computazionale della generazione del testo. Ad esempio, OpenAI fa pagare $15 per 1 milione di token ($0,015 per 1.000 token) per GPT-4o.
Per ottimizzare l'utilizzo dei gettoni di uscita e controllare i costi:
Impostare limiti chiari di lunghezza dell'output nei prompt o nelle chiamate API.
Utilizzate tecniche come il "few-shot learning" per guidare il modello verso risposte più concise.
Implementare la post-elaborazione per tagliare i contenuti non necessari dagli output di LLM.
Considerare la possibilità di memorizzare nella cache le informazioni richieste di frequente per ridurre le chiamate LLM ridondanti.
Finestre contestuali: Il fattore di costo nascosto
Le finestre di contesto determinano la quantità di testo precedente che il LLM può considerare quando genera una risposta. Questa caratteristica è fondamentale per mantenere la coerenza nelle conversazioni e per consentire al modello di fare riferimento alle informazioni precedenti. La dimensione della finestra di contesto può avere un impatto significativo sulle prestazioni del modello, soprattutto per i compiti che richiedono una memoria a lungo termine o un ragionamento complesso.
Finestre di contesto più ampie aumentano direttamente il numero di token di input elaborati dal modello, con conseguenti costi più elevati. Ad esempio:
Un modello con una finestra di contesto da 4.000 token che elabora una conversazione da 3.000 token addebiterà tutti i 3.000 token.
La stessa conversazione con una finestra contestuale di 8.000 token potrebbe essere addebitata per 7.000 token, comprese le parti precedenti della conversazione.
Questo ridimensionamento può comportare un aumento sostanziale dei costi, soprattutto per le applicazioni che gestiscono dialoghi lunghi o l'analisi di documenti.
Per ottimizzare l'uso della finestra contestuale:
Implementare il dimensionamento dinamico del contesto in base ai requisiti dell'attività.
Usare tecniche di riassunto per condensare le informazioni rilevanti di conversazioni più lunghe.
Utilizzare approcci a finestra scorrevole per l'elaborazione di documenti lunghi, concentrandosi sulle sezioni più rilevanti.
Considerate l'utilizzo di modelli più piccoli e specializzati per le attività che non richiedono un contesto esteso.
Gestendo attentamente le finestre di contesto, è possibile trovare un equilibrio tra il mantenimento di risultati di alta qualità e il controllo dei costi dell'LLM. Ricordate che l'obiettivo è fornire un contesto sufficiente per l'attività in corso senza gonfiare inutilmente l'uso dei token e le spese associate.
Tendenze future nella determinazione dei prezzi degli LLM
Con l'evolversi del panorama degli LLM, potremmo assistere a cambiamenti nella struttura dei prezzi:
Prezzi basati sui compiti: I modelli vengono addebitati in base alla complessità del compito piuttosto che al numero di token.
Modelli di abbonamento: Accesso forfettario agli LLM con limiti di utilizzo o prezzi differenziati.
Prezzi basati sulle prestazioni: Costi legati alla qualità o all'accuratezza dei risultati piuttosto che alla semplice quantità.
Impatto dei progressi tecnologici sui costi
La ricerca e lo sviluppo in corso nell'IA possono portare a:
Modelli più efficienti: Riduzione dei requisiti computazionali con conseguente riduzione dei costi operativi.
Tecniche di compressione migliorate: Metodi avanzati per ridurre il numero di token in ingresso e in uscita.
Integrazione dell'edge computing: Elaborazione locale dei compiti LLM, potenzialmente in grado di ridurre i costi del cloud computing.
Il bilancio
La comprensione delle strutture dei prezzi LLM è essenziale per una gestione efficace dei costi nelle applicazioni AI aziendali. Conoscendo le sfumature dei token di input, dei token di output e delle finestre di contesto, le organizzazioni possono prendere decisioni informate sulla selezione dei modelli e sui modelli di utilizzo. L'implementazione di tecniche strategiche di gestione dei costi, come l'ottimizzazione dell'uso dei token e lo sfruttamento del caching, può portare a risparmi significativi.
Con la continua evoluzione della tecnologia LLM, rimanere informati sulle tendenze dei prezzi e sulle strategie di ottimizzazione emergenti sarà fondamentale per mantenere le operazioni di IA efficienti dal punto di vista dei costi. Ricordate che una gestione efficace dei costi dell'LLM è un processo continuo che richiede un monitoraggio, un'analisi e un adattamento continui per garantire il massimo valore dei vostri investimenti nell'IA.
Se volete sapere come la vostra azienda può sfruttare in modo più efficace le strutture tariffarie LLM, non esitate a contattarci!


