
Qu'est-ce que l'apprentissage par petites touches ?



Dans le domaine de l'IA, la capacité à apprendre efficacement à partir de données limitées est devenue cruciale. L'apprentissage Few Shot est une approche qui améliore la manière dont les modèles d'IA acquièrent des connaissances et s'adaptent à de nouvelles tâches.
Mais qu'est-ce que l'apprentissage par petites touches ?
Définir l'apprentissage par petites touches
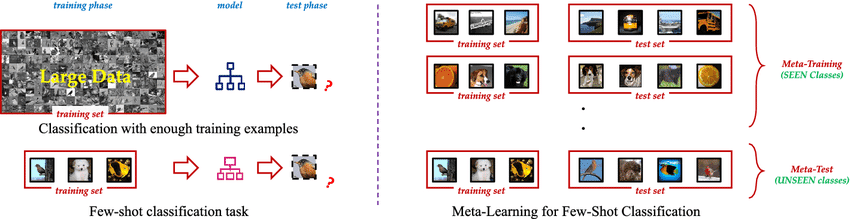
Few Shot Learning est un programme innovant de apprentissage automatique qui permet aux modèles d'intelligence artificielle d'apprendre de nouveaux concepts ou de nouvelles tâches à partir de quelques exemples seulement. Contrairement aux méthodes traditionnelles d'apprentissage supervisé qui nécessitent de grandes quantités de données d'apprentissage étiquetées, les techniques d'apprentissage Few Shot permettent aux modèles de se généraliser efficacement en utilisant seulement un petit nombre d'échantillons. Cette approche imite la capacité humaine à saisir rapidement de nouvelles idées sans qu'il soit nécessaire de les répéter à l'infini.
L'essence même de l'apprentissage à petite échelle réside dans sa capacité à exploiter les connaissances antérieures et à s'adapter rapidement à de nouveaux scénarios. En utilisant des techniques telles que le méta-apprentissage, où le modèle "apprend à apprendre", les algorithmes de Few Shot Learning peuvent s'attaquer à un large éventail de tâches avec un minimum de formation supplémentaire. Cette flexibilité en fait un outil inestimable dans les scénarios où les données sont rares, coûteuses à obtenir ou en constante évolution.
Le défi de la rareté des données dans l'IA
Toutes les données ne sont pas égales et les données étiquetées de haute qualité peuvent être une denrée rare et précieuse. Cette rareté constitue un défi de taille pour les approches traditionnelles d'apprentissage supervisé, qui nécessitent généralement des milliers, voire des millions d'exemples étiquetés pour obtenir des performances satisfaisantes.
Le problème de la rareté des données est particulièrement aigu dans les domaines spécialisés tels que les soins de santé, où les maladies rares peuvent avoir un nombre limité de cas documentés, ou dans les environnements en évolution rapide où de nouvelles catégories de données apparaissent fréquemment. Dans ces scénarios, le temps et les ressources nécessaires à la collecte et à l'étiquetage de grands ensembles de données peuvent être prohibitifs, ce qui crée un goulet d'étranglement dans le développement et le déploiement de l'IA.
Apprentissage par petites touches vs. apprentissage supervisé traditionnel
Pour apprécier pleinement l'impact du Few Shot Learning, il est essentiel de comprendre en quoi il diffère des méthodes traditionnelles d'apprentissage supervisé et pourquoi cette distinction est importante dans les applications du monde réel.
Limites des approches conventionnelles
Traditionnel apprentissage supervisé repose sur un principe simple mais gourmand en données : plus un modèle voit d'exemples au cours de sa formation, plus il devient apte à reconnaître des modèles et à faire des prédictions. Si cette approche a permis d'obtenir des résultats remarquables dans divers domaines, elle présente néanmoins plusieurs inconvénients majeurs :
Dépendance des données : Les modèles conventionnels se heurtent souvent à des difficultés lorsqu'ils sont confrontés à des données d'apprentissage limitées, ce qui conduit à un surajustement ou à une mauvaise généralisation.
L'inflexibilité : Une fois formés, ces modèles ne sont généralement performants que pour les tâches spécifiques pour lesquelles ils ont été formés, et n'ont pas la capacité de s'adapter rapidement à de nouvelles tâches connexes.
Intensité des ressources : La collecte et l'étiquetage de grands ensembles de données prennent du temps, sont coûteux et souvent peu pratiques, en particulier dans les domaines spécialisés ou en évolution rapide.
Mise à jour continue : Dans des environnements dynamiques où de nouvelles catégories de données apparaissent fréquemment, les modèles traditionnels peuvent nécessiter un recyclage constant pour rester pertinents.
Comment l'apprentissage par tir à la volée relève-t-il ces défis ?
Few Shot Learning propose un changement de paradigme en s'attaquant à ces limitations, en fournissant une approche plus flexible et plus efficace de l'apprentissage automatique :
Efficacité de l'échantillon : En tirant parti des techniques de méta-apprentissage, les modèles de Few Shot Learning peuvent généraliser à partir de quelques exemples seulement, ce qui les rend très efficaces dans les scénarios où les données sont rares.
Adaptation rapide : Ces modèles sont conçus pour s'adapter rapidement à de nouvelles tâches ou catégories, et ne nécessitent souvent qu'un petit nombre d'exemples pour obtenir de bonnes performances.
Optimisation des ressources : Grâce à sa capacité à tirer des enseignements de données limitées, Few Shot Learning réduit la nécessité de collecter et d'étiqueter de nombreuses données, ce qui permet de gagner du temps et d'économiser des ressources.
Apprentissage continu : Peu d'approches de type "Shot Learning" sont intrinsèquement plus adaptées aux scénarios d'apprentissage continu, dans lesquels les modèles doivent intégrer de nouvelles connaissances sans oublier les informations apprises précédemment.
Polyvalence : Qu'il s'agisse de tâches de vision artificielle telles que la classification d'images en quelques plans ou d'applications de traitement du langage naturel, l'apprentissage en quelques plans fait preuve d'une polyvalence remarquable dans de nombreux domaines.
En relevant ces défis, Few Shot Learning ouvre de nouvelles perspectives dans le développement de l'IA, en permettant la création de modèles plus adaptables et plus efficaces.
Le spectre de l'apprentissage par échantillonnage
Il existe un éventail fascinant d'approches visant à minimiser la quantité de données d'apprentissage nécessaires. Ce spectre comprend l'apprentissage à partir de zéro (Zero Shot Learning), l'apprentissage à partir d'un seul (One Shot Learning) et l'apprentissage à partir de quelques (Few Shot Learning), chacun offrant des capacités uniques pour relever le défi de l'apprentissage à partir d'un nombre limité d'exemples.
Apprentissage à partir de zéro : Apprentissage sans exemples
À l'extrémité de l'efficacité de l'échantillonnage se trouve l'apprentissage à partir de zéro (Zero Shot Learning). Cette approche remarquable permet aux modèles de reconnaître ou de classer des instances de classes qu'ils n'ont jamais vues pendant la formation. Au lieu de s'appuyer sur des exemples étiquetés, l'apprentissage à partir de zéro exploite des informations auxiliaires, telles que des descriptions textuelles ou des représentations basées sur des attributs, pour faire des prédictions sur des classes non vues.
Par exemple, un modèle d'apprentissage par tir nul pourrait être capable de classer une nouvelle espèce animale qu'il n'a jamais rencontrée auparavant, en se basant uniquement sur une description textuelle de ses caractéristiques. Cette capacité est particulièrement précieuse dans les scénarios où l'obtention d'exemples étiquetés pour toutes les classes possibles est peu pratique ou impossible.
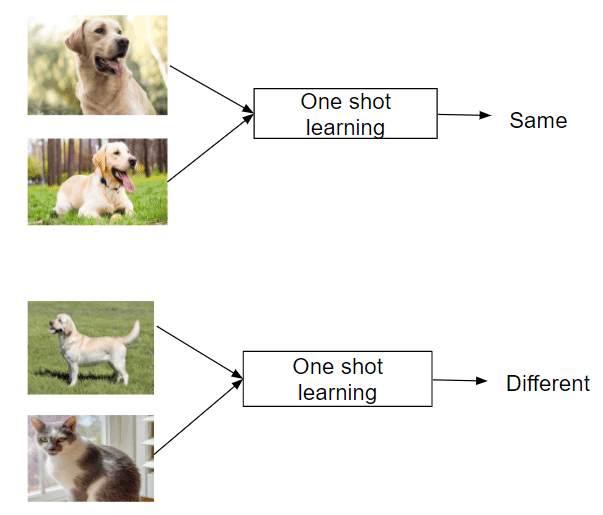
Apprentissage à partir d'une seule instance : Apprentissage à partir d'une seule instance
Le long du spectre, nous rencontrons l'apprentissage à un coup, un sous-ensemble de l'apprentissage à quelques coups dans lequel le modèle apprend à reconnaître de nouvelles classes à partir d'un seul exemple. Cette approche s'inspire de la cognition humaine, imitant notre capacité à saisir rapidement de nouveaux concepts après les avoir vus une seule fois.
Les techniques d'apprentissage unique reposent souvent sur la comparaison de nouvelles instances à l'exemple unique qu'elles ont vu, à l'aide de mesures de similarité sophistiquées. Cette méthode a connu un succès remarquable dans des domaines tels que la reconnaissance faciale, où un système peut apprendre à identifier une personne à partir d'une seule photo.
Apprentissage en quelques coups : Maîtriser des tâches avec un minimum de données
L'apprentissage à quelques coups étend le concept de l'apprentissage à un coup à des scénarios dans lesquels un petit nombre (généralement 2 à 5) d'exemples étiquetés est disponible pour chaque nouvelle classe. Cette approche permet de trouver un équilibre entre l'extrême efficacité en termes de données des méthodes d'apprentissage à zéro et à un coup et les méthodes traditionnelles d'apprentissage supervisé, plus gourmandes en données.
Peu de techniques de Shot Learning permettent aux modèles de s'adapter rapidement à de nouvelles tâches ou classes avec seulement quelques exemples, ce qui les rend inestimables dans les domaines où la rareté des données est un défi important. En s'appuyant sur des stratégies de méta-apprentissage, ces modèles apprennent à apprendre, ce qui leur permet de généraliser efficacement à partir de données limitées.
Concepts fondamentaux de l'apprentissage par petites touches
Pour bien saisir la puissance de l'apprentissage Few Shot, il est essentiel de comprendre certains concepts fondamentaux qui sous-tendent cette approche innovante.
Classification K-shot à N voies expliquée
Au cœur de Few Shot Learning se trouve le cadre de classification K-shot à N voies. Cette terminologie décrit la structure d'une tâche de Few Shot Learning :
N-way désigne le nombre de classes que le modèle doit distinguer dans une tâche donnée.
K-shot indique le nombre d'exemples fournis pour chaque classe.
Par exemple, une tâche de classification à 5 voies et 3 plans impliquerait de faire la distinction entre 5 classes différentes, avec 3 exemples fournis pour chaque classe. Ce cadre permet aux chercheurs et aux praticiens d'évaluer et de comparer systématiquement les différents algorithmes d'apprentissage Few Shot dans des conditions cohérentes.
Le rôle des ensembles de soutien et d'interrogation
Dans le cadre de l'apprentissage par échantillonnage, les données sont généralement organisées en deux ensembles distincts :
Ensemble de soutien : Cet ensemble contient les quelques exemples étiquetés (K plans) pour chacune des N classes. Le modèle utilise cet ensemble pour apprendre ou s'adapter à la nouvelle tâche.
Ensemble de requêtes : Il s'agit d'exemples supplémentaires des mêmes N classes, que le modèle doit classer correctement. Les performances du modèle sur l'ensemble de requêtes déterminent la qualité de son apprentissage à partir des exemples limités de l'ensemble de support.
Cette structure permet au modèle d'apprendre à partir d'un petit nombre d'exemples (l'ensemble de support) et de tester immédiatement sa capacité à se généraliser à de nouveaux exemples non vus (l'ensemble d'interrogation) dans le cadre de la même tâche.
Approches de l'apprentissage par petites touches
Les chercheurs ont mis au point diverses approches pour relever les défis de l'apprentissage par petites touches, chacune ayant ses propres atouts et applications.
Techniques au niveau des données
Les approches basées sur les données se concentrent sur l'augmentation ou la génération de données de formation supplémentaires pour compléter les exemples limités disponibles. Ces techniques comprennent :
Augmentation des données : Appliquer des transformations aux échantillons existants pour créer de nouveaux exemples synthétiques.
Modèles génératifs : L'utilisation de modèles d'intelligence artificielle avancés pour générer des exemples réalistes et artificiels sur la base des données réelles limitées disponibles.
Ces méthodes visent à augmenter la taille effective de l'ensemble d'apprentissage, en aidant les modèles à apprendre des représentations plus robustes à partir de données limitées.
Stratégies au niveau des paramètres
Les approches basées sur les paramètres se concentrent sur l'optimisation des paramètres du modèle afin de permettre une adaptation rapide aux nouvelles tâches. Ces stratégies impliquent souvent :
Techniques d'initialisation : Trouver des points de départ optimaux pour les paramètres du modèle qui permettent une adaptation rapide à de nouvelles tâches.
Méthodes de régularisation: Contrainte de l'espace des paramètres du modèle pour éviter un surajustement sur les données limitées disponibles.
Ces approches visent à rendre le modèle plus flexible et adaptable, lui permettant d'apprendre efficacement à partir de quelques exemples seulement.
Méthodes basées sur des mesures
Les techniques d'apprentissage par métrique (Few Shot Learning) se concentrent sur l'apprentissage d'une distance ou d'une fonction de similarité permettant de comparer efficacement de nouveaux exemples aux données étiquetées limitées disponibles. Les méthodes populaires basées sur les métriques comprennent :
Réseaux siamois : Apprendre à calculer des scores de similarité entre des paires d'entrées.
Réseaux prototypiques : Calculer les prototypes de classe et classer les nouveaux exemples en fonction de leur distance par rapport à ces prototypes.
Ces méthodes excellent dans des tâches telles que la classification d'images peu nombreuses en apprenant à mesurer les similitudes d'une manière qui se généralise bien à de nouvelles classes.
Méta-apprentissage basé sur le gradient
Les approches de méta-apprentissage basées sur le gradient, illustrées par le méta-apprentissage agnostique (MAML), visent à apprendre à apprendre. Ces méthodes impliquent généralement un processus d'optimisation à deux niveaux :
Boucle intérieure : Adaptation rapide à une tâche spécifique à l'aide de quelques étapes de gradient.
Boucle extérieure : Optimisation des paramètres initiaux du modèle pour permettre une adaptation rapide à toute une série de tâches.
En apprenant un ensemble de paramètres qui peuvent être rapidement affinés pour de nouvelles tâches, ces approches permettent aux modèles de s'adapter rapidement à de nouveaux scénarios avec seulement quelques exemples.
Chacune de ces approches du Few Shot Learning offre des avantages uniques, et les chercheurs combinent souvent plusieurs techniques pour créer des modèles plus puissants et plus flexibles. Alors que nous continuons à repousser les limites de l'IA, ces méthodes d'apprentissage économes en échantillons jouent un rôle de plus en plus crucial dans le développement de systèmes d'apprentissage automatique plus adaptables et plus efficaces.
Applications dans tous les secteurs d'activité
Few Shot L'apprentissage n'est pas seulement un concept théorique, c'est une découverte. applications pratiques dans divers secteurs, ce qui change la façon dont l'IA relève les défis du monde réel.
Vision par ordinateur : De la classification d'images à la détection d'objets
Dans le domaine de la vision par ordinateur, l'apprentissage Few Shot repousse les limites de ce qui est possible avec des données limitées :
Classification des images : Quelques techniques de classification d'images permettent aux modèles de reconnaître de nouvelles catégories d'objets à partir d'une poignée d'exemples, ce qui est crucial pour des applications telles que la surveillance de la faune et de la flore ou le contrôle de la qualité industrielle.
Détection d'objets : Les méthodes de détection d'objets peu nombreux améliorent la capacité des systèmes à localiser et à identifier de nouveaux objets dans les images ou les flux vidéo, avec des applications allant des véhicules autonomes aux systèmes de sécurité.
Reconnaissance faciale : Les approches d'apprentissage en une seule fois ont considérablement amélioré les systèmes de reconnaissance faciale, leur permettant d'identifier des individus à partir d'une seule image de référence.
Traitement du langage naturel : Adaptation des modèles linguistiques
Le Few Shot Learning fait également des vagues dans le domaine du traitement du langage naturel (NLP), car il permet d'élaborer des modèles linguistiques plus souples et plus efficaces :
Classification des textes : Les modèles peuvent s'adapter rapidement à de nouvelles catégories de texte ou à des tâches d'analyse des sentiments avec un minimum d'exemples, ce qui est crucial pour des applications telles que la modération de contenu ou l'analyse des commentaires des clients.
Traduction automatique : Peu de techniques de tir améliorent la capacité des systèmes de traduction à traiter les langues à faibles ressources ou la terminologie spécifique à un domaine.
Réponse aux questions : Peu d'approches d'apprentissage par tir améliorent la capacité de l'IA à répondre à des questions sur de nouveaux sujets avec des données d'apprentissage limitées.
Robotique : Adaptation rapide à de nouveaux environnements
En robotique, la capacité d'apprendre et de s'adapter rapidement est cruciale. Few Shot Learning permet aux robots de :
Maîtriser de nouvelles tâches avec un minimum de démonstrations, ce qui accroît leur polyvalence dans les secteurs de la fabrication et des services.
S'adapter à de nouveaux environnements ou à des situations inattendues, ce qui est crucial pour le déploiement dans des environnements dynamiques du monde réel.
Apprendre de nouvelles techniques de préhension d'objets inédits, en élargissant leur utilité dans le domaine de l'entreposage et de la logistique.
Santé : S'attaquer aux maladies rares avec des données limitées
Few Shot Learning est particulièrement utile dans le domaine des soins de santé, où les données relatives aux maladies rares sont souvent rares :
Diagnostic de la maladie : Les modèles peuvent apprendre à identifier les maladies rares à partir de données d'imagerie médicale limitées, ce qui pourrait accélérer le diagnostic et le traitement.
Découverte de médicaments : De rares techniques d'injection contribuent à l'identification de candidats médicaments potentiels pour les maladies rares, là où les approches traditionnelles, gourmandes en données, risquent d'être insuffisantes.
Médecine personnalisée : En s'adaptant rapidement aux données individuelles des patients, les modèles de Few Shot Learning contribuent à l'élaboration de plans de traitement plus personnalisés.
Défis et orientations futures de l'apprentissage à partir de quelques images
Bien que l'apprentissage par petites touches ait fait des progrès remarquables, il reste encore plusieurs défis à relever et des pistes de recherche intéressantes à explorer.
Limites actuelles :
Généralisation à d'autres domaines : De nombreux modèles de Few Shot Learning rencontrent des difficultés lorsque la distribution de la nouvelle tâche diffère sensiblement des tâches d'apprentissage.
Évolutivité : Certaines approches, en particulier les méthodes basées sur les métriques, peuvent devenir coûteuses en termes de calcul lorsque le nombre de classes augmente.
Robustesse : Peu de modèles d'apprentissage par cliché peuvent être sensibles au choix des exemples de l'ensemble de support, ce qui peut conduire à des performances incohérentes.
Interprétabilité : Comme pour de nombreuses approches d'apprentissage en profondeur, le processus de prise de décision dans les modèles de Few Shot Learning peut être opaque, ce qui limite leur applicabilité dans des domaines sensibles.
Domaines de recherche prometteurs :
Apprentissage inter-domaines des petits coups : Développer des méthodes qui peuvent être généralisées dans des domaines très différents, en améliorant la polyvalence des modèles de Few Shot Learning.
Incorporation de données non étiquetées : Exploration des approches d'apprentissage semi-supervisé de type Few Shot Learning pour exploiter l'abondance de données non étiquetées disponibles dans de nombreux domaines.
Apprentissage continu de quelques coups de feu : Créer des modèles capables d'apprendre continuellement de nouvelles tâches sans oublier les informations apprises précédemment, imitant ainsi plus fidèlement l'apprentissage humain.
Apprentissage explicable à quelques coups : Développement de modèles d'apprentissage à faible tir interprétables pour améliorer la confiance et l'applicabilité dans des domaines critiques tels que les soins de santé et la finance.
Apprentissage de quelques images dans le cadre de l'apprentissage par renforcement : Étendre les principes de l'apprentissage par petites touches à des scénarios d'apprentissage par renforcement pour une adaptation plus rapide dans des environnements complexes.
Le bilan
Few Shot Learning s'est imposé comme une force transformatrice, redéfinissant la manière dont nous abordons les défis de l'apprentissage automatique. En permettant aux systèmes d'IA d'apprendre efficacement à partir de données limitées, le Few Shot Learning comble le fossé entre la flexibilité cognitive de type humain et la nature gourmande en données de l'apprentissage profond traditionnel. Qu'il s'agisse d'améliorer la vision artificielle et le traitement du langage naturel ou de faire progresser la robotique et les soins de santé, Few Shot Learning fait ses preuves dans diverses industries, ouvrant de nouvelles frontières à l'innovation.
Alors que les chercheurs continuent de s'attaquer aux limites actuelles et d'explorer des directions prometteuses, nous pouvons nous attendre à des systèmes d'IA encore plus puissants et polyvalents à l'avenir. La capacité d'apprendre et de s'adapter rapidement à partir de quelques exemples seulement sera cruciale à mesure que nous évoluerons vers une intelligence artificielle plus générale, alignant plus étroitement l'apprentissage automatique sur les capacités cognitives humaines et ouvrant de nouvelles possibilités dans notre monde en évolution rapide.


