
Quelques encouragements, apprentissage et mise au point pour les LLM - AI&YOU #67 Quelques encouragements, apprentissage et mise au point pour les LLM - AI&YOU #67



Quelques encouragements, apprentissage et réglage fin pour les LLM - AI&YOU #67 Quelques encouragements, apprentissage et réglage fin pour les LLM - AI&YOU #67
La statistique de la semaine : Les recherches menées par MobiDev sur l'apprentissage à partir de quelques images pour la classification des pièces de monnaie ont montré qu'en utilisant seulement 4 exemples d'images par dénomination de pièce, il était possible d'obtenir une précision d'environ 70%.
Dans le domaine de l'IA, la capacité à apprendre efficacement à partir de données limitées est devenue cruciale. C'est pourquoi il est important pour les entreprises de comprendre l'apprentissage à partir de peu de données, l'incitation à l'apprentissage à partir de peu de données et le réglage fin des LLM.
Dans l'édition de cette semaine d'AI&YOU, nous explorons les perspectives de trois blogs que nous avons publiés sur ces sujets :
Promesses, apprentissage et réglage fin pour les LLM - AI&YOU #67
Le Few Shot Learning est un paradigme innovant d'apprentissage automatique qui permet aux modèles d'intelligence artificielle d'apprendre de nouveaux concepts ou de nouvelles tâches à partir de quelques exemples seulement. Contrairement aux méthodes traditionnelles d'apprentissage supervisé qui nécessitent de grandes quantités de données d'apprentissage étiquetées, les techniques d'apprentissage Few Shot permettent aux modèles de se généraliser efficacement en utilisant seulement un petit nombre d'échantillons. Cette approche imite la capacité humaine à saisir rapidement de nouvelles idées sans avoir à les répéter longuement.
L'essence même de l'apprentissage à petite échelle réside dans sa capacité à exploiter les connaissances antérieures et à s'adapter rapidement à de nouveaux scénarios. En utilisant des techniques telles que le méta-apprentissage, où le modèle "apprend à apprendre", les algorithmes de Few Shot Learning peuvent s'attaquer à un large éventail de tâches avec un minimum de formation supplémentaire. Cette flexibilité en fait un outil inestimable dans les scénarios où les données sont rares, coûteuses à obtenir ou en constante évolution.

Le défi de la rareté des données dans l'IA
Toutes les données ne sont pas égales et les données étiquetées de haute qualité peuvent être une denrée rare et précieuse. Cette rareté constitue un défi de taille pour les approches traditionnelles d'apprentissage supervisé, qui nécessitent généralement des milliers, voire des millions d'exemples étiquetés pour obtenir des performances satisfaisantes.
Le problème de la rareté des données est particulièrement aigu dans les domaines spécialisés tels que les soins de santé, où les maladies rares peuvent avoir un nombre limité de cas documentés, ou dans les environnements en évolution rapide où de nouvelles catégories de données apparaissent fréquemment. Dans ces scénarios, le temps et les ressources nécessaires à la collecte et à l'étiquetage de grands ensembles de données peuvent être prohibitifs, ce qui crée un goulet d'étranglement dans le développement et le déploiement de l'IA.
Apprentissage par petites touches vs. apprentissage supervisé traditionnel
Il est essentiel de comprendre la distinction entre le Few Shot Learning et l'apprentissage supervisé traditionnel pour saisir son impact dans le monde réel.
Traditionnel apprentissage superviséBien que puissant, ce système présente des inconvénients :
Dépendance des données : Difficultés avec des données de formation limitées.
L'inflexibilité : N'obtient de bons résultats que pour des tâches spécifiques.
Intensité des ressources : Nécessite des ensembles de données volumineux et coûteux.
Mise à jour continue : Nécessite de fréquents recyclages dans des environnements dynamiques.
Apprentissage en quelques coups offre un changement de paradigme :
Efficacité de l'échantillon : Généralisation à partir de quelques exemples grâce au méta-apprentissage.
Adaptation rapide : S'adapte rapidement à de nouvelles tâches avec un minimum d'exemples.
Optimisation des ressources : Réduit les besoins en matière de collecte de données et d'étiquetage.
Apprentissage continu : Convient pour intégrer de nouvelles connaissances sans oublier.
Polyvalence : Applicable dans divers domaines, de la vision par ordinateur au NLP.
En s'attaquant à ces défis, Few Shot Learning permet de créer des modèles d'IA plus adaptables et plus efficaces, ouvrant ainsi de nouvelles possibilités de développement de l'IA.
Le spectre de l'apprentissage par échantillonnage
Un éventail fascinant d'approches vise à minimiser les données de formation requises, notamment l'apprentissage à zéro, à un coup et à quelques coups.
Apprentissage à partir de zéro : Apprentissage sans exemples
Reconnaît les classes non vues à l'aide d'informations auxiliaires telles que des descriptions textuelles.
Précieux lorsque les exemples étiquetés pour toutes les classes sont peu pratiques ou impossibles.
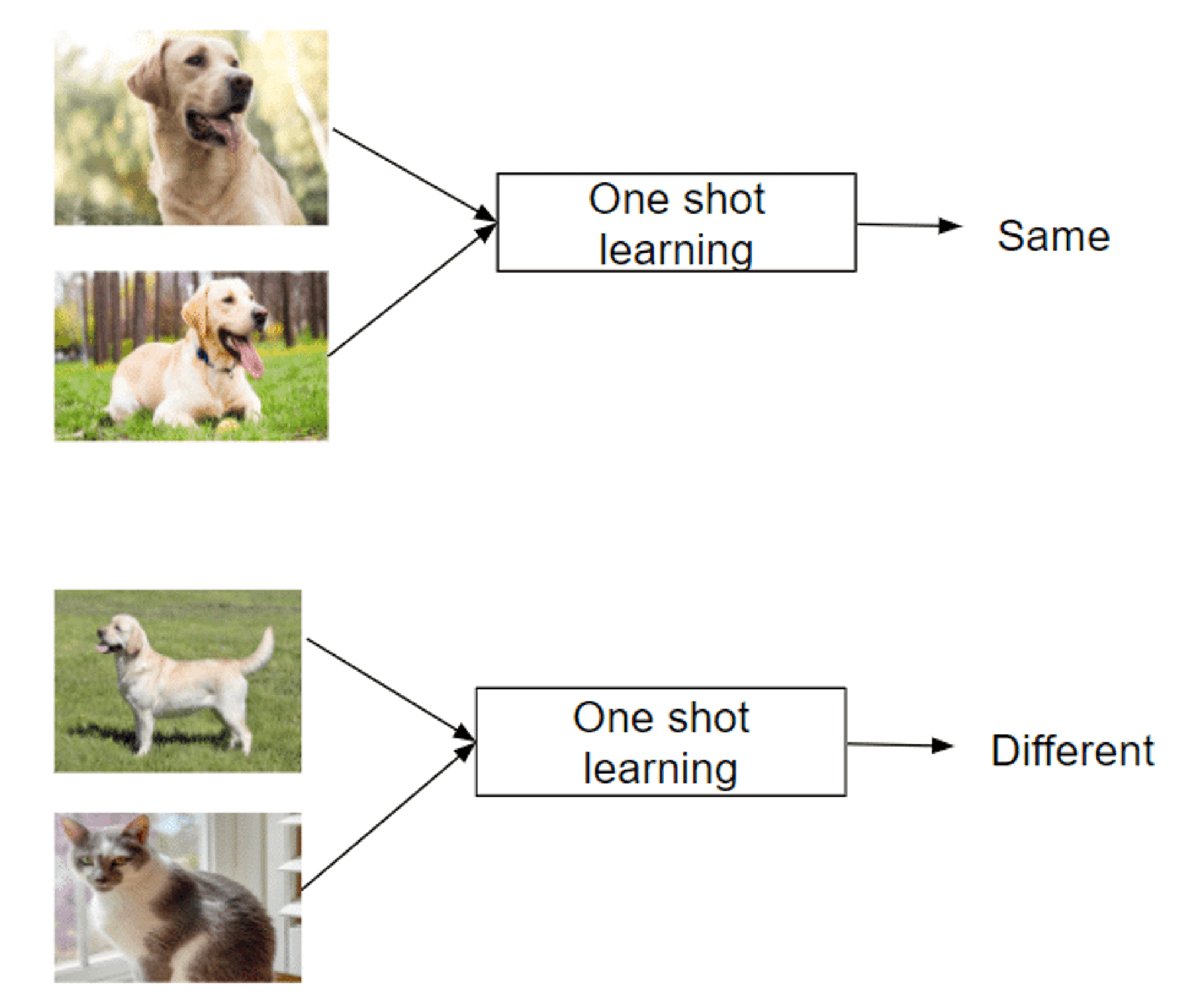
Apprentissage à partir d'une seule instance : Apprentissage à partir d'une seule instance
Reconnaître de nouvelles classes à partir d'un seul exemple
Imite la capacité humaine à saisir rapidement les concepts
Succès dans des domaines tels que la reconnaissance faciale
Apprentissage en quelques coups : Maîtriser des tâches avec un minimum de données
Utilise 2 à 5 exemples étiquetés par nouvelle classe
Équilibre entre l'efficacité extrême des données et les méthodes traditionnelles
Permet une adaptation rapide à de nouvelles tâches ou classes
Exploite les stratégies de méta-apprentissage pour apprendre à apprendre
Cet éventail d'approches offre des capacités uniques pour relever le défi de l'apprentissage à partir d'exemples limités, ce qui les rend inestimables dans les domaines où les données sont rares.
Promesse de quelques coups ou réglage fin LLM
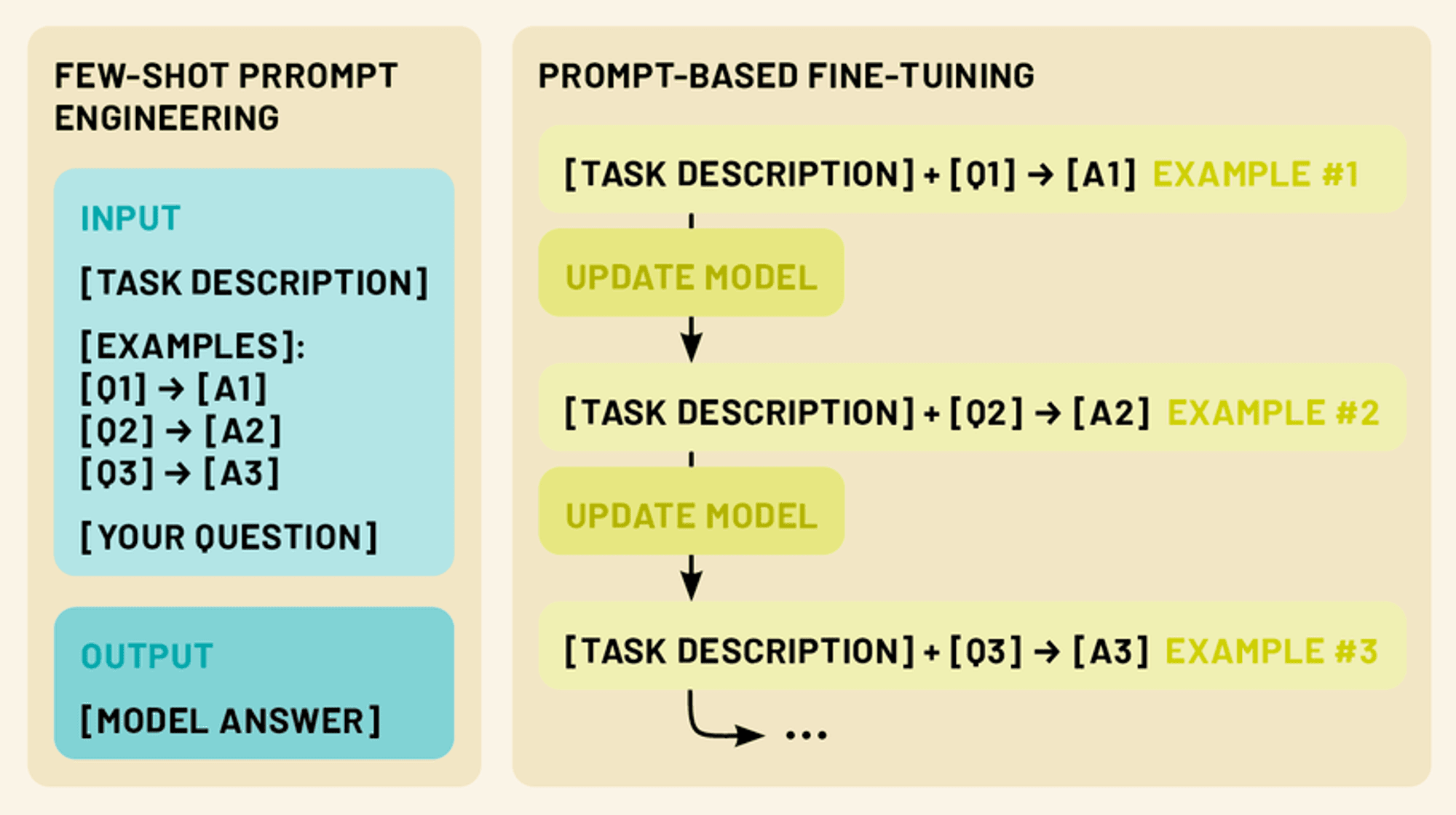
Il existe deux techniques plus puissantes dans ce domaine : l'incitation à la saisie d'un petit nombre d'exemples et le réglage fin. Le "Few-shot prompting" consiste à élaborer des invites de saisie intelligentes comprenant un petit nombre d'exemples, afin de guider le modèle dans l'exécution d'une tâche spécifique sans formation supplémentaire. Le réglage fin, quant à lui, consiste à mettre à jour les paramètres du modèle à l'aide d'une quantité limitée de données spécifiques à une tâche, ce qui lui permet d'adapter ses vastes connaissances à un domaine ou à une application particulière.
Ces deux approches relèvent de l'apprentissage à court terme. En tirant parti de ces techniques, nous pouvons améliorer considérablement les performances et la polyvalence des LLM, ce qui en fait des outils plus pratiques et plus efficaces pour un large éventail d'applications dans le domaine du traitement du langage naturel et au-delà.
Promesse de quelques coups de feu : Libérer le potentiel du LLM
L'invite à quelques coups tire parti de la capacité du modèle à comprendre les instructions, en "programmant" efficacement le LLM à l'aide d'invitations personnalisées.
Des messages-guides à quelques reprises fournissent de 1 à 5 exemples démontrant la tâche souhaitée, en tirant parti de la reconnaissance des modèles et de l'adaptabilité du modèle. Cela permet d'effectuer des tâches pour lesquelles il n'y a pas eu de formation explicite, en exploitant la capacité d'apprentissage en contexte du LLM.
En présentant des schémas d'entrée-sortie clairs, l'incitation par quelques images guide le LLM pour qu'il applique un raisonnement similaire à de nouvelles entrées, ce qui permet une adaptation rapide à de nouvelles tâches sans mise à jour des paramètres.
Types de messages-guides à court terme (zéro, un, quelques)
L'incitation à l'utilisation d'un petit nombre d'exemples englobe un éventail d'approches, chacune d'entre elles étant définie par le nombre d'exemples fournis. (Tout comme l'apprentissage par petites touches) :
Invitation sans coup férir : Dans ce scénario, aucun exemple n'est fourni. Au lieu de cela, le modèle reçoit une instruction ou une description claire de la tâche. Par exemple, "Traduisez le texte anglais suivant en français : [texte d'entrée]".
Incitation en une seule fois : Ici, un seul exemple est fourni avant l'entrée réelle. Cela donne au modèle un exemple concret de la relation entrée-sortie attendue. Voici un exemple : "Classer le sentiment de l'avis suivant comme positif ou négatif. Exemple : "Ce film était fantastique" - Entrée positive : "Je n'ai pas supporté l'intrigue". - [le modèle génère la réponse]".
Incitation à quelques coups de feu : Cette approche fournit plusieurs exemples (généralement 2 à 5) avant l'entrée réelle. Cela permet au modèle de reconnaître des modèles plus complexes et des nuances dans la tâche. Par exemple : "Classez les phrases suivantes comme des questions ou des affirmations : 'Le ciel est bleu'. - Énoncé "Quelle heure est-il ?" - Question "J'aime les glaces". - Entrée d'énoncé : "Où puis-je trouver le restaurant le plus proche ?" - [le modèle génère la réponse]".
Concevoir des messages-guides efficaces
Concevoir des messages-guides efficaces est à la fois un art et une science. Voici quelques principes clés à prendre en compte :
Clarté et cohérence : Veillez à ce que vos exemples et vos instructions soient clairs et suivent un format cohérent. Cela permet au modèle de reconnaître plus facilement le modèle.
La diversité : Lorsque vous utilisez plusieurs exemples, essayez de couvrir un éventail d'entrées et de sorties possibles afin de donner au modèle une compréhension plus large de la tâche.
Pertinence : Choisissez des exemples étroitement liés à la tâche ou au domaine spécifique que vous visez. Cela permet au modèle de se concentrer sur les aspects les plus pertinents de ses connaissances.
Concision : S'il est important de fournir suffisamment de contexte, il faut éviter les questions trop longues ou trop complexes qui risquent d'embrouiller le modèle ou de diluer les informations essentielles.
Expérimentation : N'ayez pas peur d'itérer et d'expérimenter avec différentes structures d'invite et différents exemples pour trouver ce qui fonctionne le mieux pour votre cas d'utilisation spécifique.
En maîtrisant l'art des messages courts, nous pouvons libérer tout le potentiel des LLM, en leur permettant de s'attaquer à un large éventail de tâches avec un minimum d'informations ou de formation supplémentaires.
Ajustement fin des LLM : Adapter les modèles avec des données limitées
Alors que l'incitation à quelques essais est une technique puissante pour adapter les LLM à de nouvelles tâches sans modifier le modèle lui-même, le réglage fin offre un moyen de mettre à jour les paramètres du modèle pour une performance encore meilleure sur des tâches ou des domaines spécifiques. Le réglage fin nous permet d'exploiter les vastes connaissances encodées dans les LLM pré-entraînés tout en les adaptant à nos besoins spécifiques en n'utilisant qu'une petite quantité de données spécifiques à la tâche.
Comprendre le réglage fin dans le contexte des LLM
La mise au point d'un LLM implique un entraînement supplémentaire d'un modèle pré-entraîné sur un ensemble de données plus petit et spécifique à une tâche. Ce processus permet d'adapter le modèle à la tâche cible tout en s'appuyant sur les connaissances existantes, ce qui nécessite moins de données et de ressources qu'une formation à partir de zéro.
Dans les LLM, le réglage fin ajuste généralement les poids dans les couches supérieures pour les caractéristiques spécifiques à la tâche, tandis que les couches inférieures restent largement inchangées. Cette approche d'"apprentissage par transfert" permet de conserver une compréhension générale de la langue tout en développant des capacités spécialisées.
Techniques d'ajustement de quelques tirs
Le réglage fin à quelques reprises adapte le modèle en utilisant seulement 10 à 100 échantillons par classe ou tâche, ce qui est précieux lorsque les données étiquetées sont rares. Les techniques clés sont les suivantes :
Mise au point basée sur des invites : Combine des messages courts avec des mises à jour de paramètres.
Approches de méta-apprentissage : Des méthodes telles que MAML visent à trouver de bons points d'initialisation pour une adaptation rapide.
Réglage fin basé sur l'adaptateur: Introduit de petits modules "adaptateurs" entre les couches du modèle pré-entraîné, réduisant ainsi les paramètres entraînables.
Apprentissage en contexte : Ajustement des LLM afin de mieux réaliser l'adaptation par le biais de messages-guides uniquement.
Ces techniques permettent aux LLM de s'adapter à de nouvelles tâches avec un minimum de données, ce qui améliore leur polyvalence et leur efficacité.
L'incitation à quelques coups de feu ou la mise au point : Choisir la bonne approche
Lorsqu'il s'agit d'adapter les LLM à des tâches spécifiques, l'incitation à quelques coups et le réglage fin offrent tous deux des solutions puissantes. Cependant, chaque méthode a ses propres forces et limites, et le choix de la bonne approche dépend de plusieurs facteurs.
Quelques questions à la volée Points forts :
Ne nécessite aucune mise à jour des paramètres du modèle, ce qui permet de conserver le modèle original.
Très flexible et adaptable à la volée
Pas de temps de formation ou de ressources informatiques supplémentaires nécessaires
Utile pour le prototypage et l'expérimentation rapides
Limites:
Les performances peuvent être moins régulières, en particulier pour les tâches complexes.
Limité par les capacités et les connaissances initiales du modèle
Peut éprouver des difficultés dans des domaines ou des tâches hautement spécialisés
Affiner les points forts :
Obtient souvent de meilleurs résultats dans des tâches spécifiques
Peut adapter le modèle à de nouveaux domaines et à un vocabulaire spécialisé
Des résultats plus cohérents pour des données similaires
Potentiel d'apprentissage et d'amélioration continus
Limites:
Nécessite un temps de formation et des ressources informatiques supplémentaires
Risque d'oubli catastrophique s'il n'est pas géré avec soin
Risque de surajustement sur les petits ensembles de données
Moins flexible ; nécessite une nouvelle formation en cas de modification importante des tâches
Les 5 meilleurs documents de recherche pour l'apprentissage en quelques minutes
Cette semaine, nous examinons également les cinq documents suivants qui ont fait progresser ce domaine de manière significative, en introduisant des approches innovantes qui redéfinissent les capacités de l'IA.

1️⃣ Matching Networks for One Shot Learning" (Vinyals et al., 2016)
Introduction d'une approche novatrice utilisant les mécanismes de la mémoire et de l'attention. La fonction d'appariement compare les exemples de la requête aux exemples de support étiquetés, établissant ainsi une nouvelle norme pour les méthodes d'apprentissage à faible impact.
2️⃣ Prototypical Networks for Few-shot Learning" (Snell et al., 2017)
a présenté une approche plus simple mais efficace, l'apprentissage d'un espace métrique où les classes sont représentées par un seul prototype. Sa simplicité et son efficacité en ont fait une base de référence populaire pour les recherches ultérieures.
3️⃣ Apprendre à comparer : Relation Network for Few-Shot Learning" (Sung et al., 2018)
Introduction d'un module de relation apprenable, permettant au modèle d'apprendre une mesure de comparaison adaptée à des tâches et à des distributions de données spécifiques. Démonstration d'une forte performance sur différents points de référence.
4️⃣ A Closer Look at Few-shot Classification" (Chen et al., 2019)
Analyse complète des méthodes existantes, en remettant en question les hypothèses communes. Proposé des modèles de base simples qui égalent ou dépassent des approches plus complexes, en soulignant l'importance des caractéristiques de base et des stratégies de formation.
5️⃣ Meta-Baseline : Exploring Simple Meta-Learning for Few-Shot Learning" (Chen et al., 2021)
Combinaison d'un préapprentissage standard et d'une étape de méta-apprentissage, permettant d'atteindre des performances de pointe. Mise en évidence des compromis entre la formation standard et les objectifs de méta-apprentissage.
Ces articles ont non seulement fait progresser la recherche universitaire, mais ils ont également ouvert la voie à des applications pratiques dans le domaine de l'IA d'entreprise. Ils représentent une progression vers des systèmes d'IA plus efficaces et adaptables, capables d'apprendre à partir de données limitées - une capacité cruciale dans de nombreux contextes commerciaux.
Le bilan
L'apprentissage ponctuel, l'incitation et la mise au point représentent des approches révolutionnaires, permettant aux LLM de s'adapter rapidement à des tâches spécialisées avec un minimum de données. Comme nous l'avons exploré, ces techniques offrent une flexibilité et une efficacité sans précédent pour adapter les LLM à diverses applications dans tous les secteurs, qu'il s'agisse d'améliorer les tâches de traitement du langage naturel ou de permettre des adaptations spécifiques à un domaine dans des domaines tels que la santé, le droit et la technologie.
Merci d'avoir pris le temps de lire AI & YOU !
Pour obtenir encore plus de contenu sur l'IA d'entreprise, y compris des infographies, des statistiques, des guides pratiques, des articles et des vidéos, suivez Skim AI sur LinkedIn
Vous êtes un fondateur, un PDG, un investisseur en capital-risque ou un investisseur à la recherche de services de conseil en IA, de développement d'IA fractionnée ou de due diligence ? Obtenez les conseils dont vous avez besoin pour prendre des décisions éclairées sur la stratégie des produits d'IA de votre entreprise et les opportunités d'investissement.
Nous construisons des solutions d'IA personnalisées pour les entreprises financées par le capital-risque et le capital-investissement dans les secteurs suivants : Technologie médicale, agrégation de nouvelles/contenu, production de films et de photos, technologie éducative, technologie juridique, Fintech & Cryptocurrency.


