
Prompt à l'action et réglage fin du LLM pour les solutions d'IA générative



Le véritable potentiel des grands modèles de langage (LLM) ne réside pas seulement dans leur vaste base de connaissances, mais aussi dans leur capacité à s'adapter à des tâches et à des domaines spécifiques avec un minimum de formation supplémentaire. C'est là que les concepts d'incitation et de réglage fin entrent en jeu, améliorant la façon dont nous exploitons la puissance des LLM dans les scénarios du monde réel.
Bien que les LLM soient formés sur des ensembles de données massifs englobant un large spectre de connaissances, ils ont souvent des difficultés lorsqu'ils sont confrontés à des tâches hautement spécialisées ou à un jargon spécifique à un domaine. Les approches traditionnelles d'apprentissage supervisé nécessitent de grandes quantités de données étiquetées pour adapter ces modèles, ce qui est souvent peu pratique ou impossible dans de nombreuses situations du monde réel. Ce défi a conduit les chercheurs et les praticiens à explorer des méthodes plus efficaces pour adapter les LLM à des cas d'utilisation spécifiques en utilisant seulement un petit nombre d'exemples.
Bref aperçu de l'incitation à quelques coups et du réglage fin
Il existe deux techniques puissantes pour relever ce défi : l'incitation à l'utilisation d'un petit nombre d'exemples et le réglage fin. Cette dernière consiste à élaborer des invites de saisie intelligentes comprenant un petit nombre d'exemples, afin de guider le modèle dans l'exécution d'une tâche spécifique sans formation supplémentaire. Le réglage fin, quant à lui, consiste à mettre à jour les paramètres du modèle à l'aide d'une quantité limitée de données spécifiques à une tâche, ce qui lui permet d'adapter ses vastes connaissances à un domaine ou à une application particulière.
Ces deux approches s'inscrivent dans le cadre de l'apprentissage à court terme, un paradigme qui permet aux modèles d'apprendre de nouvelles tâches ou de s'adapter à de nouveaux domaines en utilisant seulement quelques exemples. En tirant parti de ces techniques, nous pouvons améliorer considérablement les performances et la polyvalence des LLM, ce qui en fait des outils plus pratiques et plus efficaces pour un large éventail d'applications dans le traitement du langage naturel et au-delà.
Promesse de quelques coups de feu : Libérer le potentiel du LLM
Les messages-guides à quelques reprises sont une technique puissante qui nous permet de guider les LLM vers des tâches ou des domaines spécifiques sans avoir besoin d'une formation supplémentaire. Cette méthode tire parti de la capacité inhérente du modèle à comprendre et à suivre des instructions, en "programmant" efficacement le LLM grâce à des messages-guides soigneusement élaborés.
A la base, l'incitation à quelques coups implique de fournir au LLM un petit nombre d'exemples (typiquement 1-5) qui démontrent la tâche désirée, suivi d'une nouvelle entrée pour laquelle nous voulons que le modèle génère une réponse. Cette approche exploite la capacité du modèle à reconnaître des modèles et à adapter son comportement en fonction des exemples donnés, ce qui lui permet d'effectuer des tâches pour lesquelles il n'a pas été explicitement formé.
Le principe clé derrière l'incitation à quelques coups est qu'en présentant au modèle un modèle clair d'entrées et de sorties, nous pouvons le guider pour qu'il applique un raisonnement similaire à de nouvelles entrées inédites. Cette technique exploite la capacité d'apprentissage en contexte du LLM, ce qui lui permet de s'adapter rapidement à de nouvelles tâches sans mettre à jour ses paramètres.
Types de messages-guides à court terme (zéro, un, quelques)
L'incitation à l'utilisation d'un nombre restreint d'exemples englobe un éventail d'approches, chacune étant définie par le nombre d'exemples fournis :
Invitation sans coup férir : Dans ce scénario, aucun exemple n'est fourni. Au lieu de cela, le modèle reçoit une instruction ou une description claire de la tâche. Par exemple, "Traduisez le texte anglais suivant en français : [texte d'entrée]".
Incitation en une seule fois : Ici, un seul exemple est fourni avant l'entrée réelle. Cela donne au modèle un exemple concret de la relation entrée-sortie attendue. Voici un exemple : "Classer le sentiment de l'avis suivant comme positif ou négatif. Exemple : "Ce film était fantastique" - Entrée positive : "Je n'ai pas supporté l'intrigue". - [le modèle génère la réponse]".
Incitation à quelques coups de feu : Cette approche fournit plusieurs exemples (généralement 2 à 5) avant l'entrée réelle. Cela permet au modèle de reconnaître des modèles plus complexes et des nuances dans la tâche. Par exemple : "Classez les phrases suivantes comme des questions ou des affirmations : 'Le ciel est bleu'. - Énoncé "Quelle heure est-il ?" - Question "J'aime les glaces". - Entrée d'énoncé : "Où puis-je trouver le restaurant le plus proche ?" - [le modèle génère la réponse]".
Concevoir des messages-guides efficaces
Concevoir des messages-guides efficaces est à la fois un art et une science. Voici quelques principes clés à prendre en compte :
Clarté et cohérence : Veillez à ce que vos exemples et vos instructions soient clairs et suivent un format cohérent. Cela permet au modèle de reconnaître plus facilement le modèle.
La diversité : Lorsque vous utilisez plusieurs exemples, essayez de couvrir un éventail d'entrées et de sorties possibles afin de donner au modèle une compréhension plus large de la tâche.
Pertinence : Choisissez des exemples étroitement liés à la tâche ou au domaine spécifique que vous visez. Cela permet au modèle de se concentrer sur les aspects les plus pertinents de ses connaissances.
Concision : S'il est important de fournir suffisamment de contexte, il faut éviter les questions trop longues ou trop complexes qui risquent d'embrouiller le modèle ou de diluer les informations essentielles.
Expérimentation : N'ayez pas peur d'itérer et d'expérimenter avec différents rapide et des exemples pour trouver ce qui convient le mieux à votre cas d'utilisation spécifique.
En maîtrisant l'art des messages courts, nous pouvons libérer tout le potentiel des LLM, en leur permettant de s'attaquer à un large éventail de tâches avec un minimum d'informations ou de formation supplémentaires.
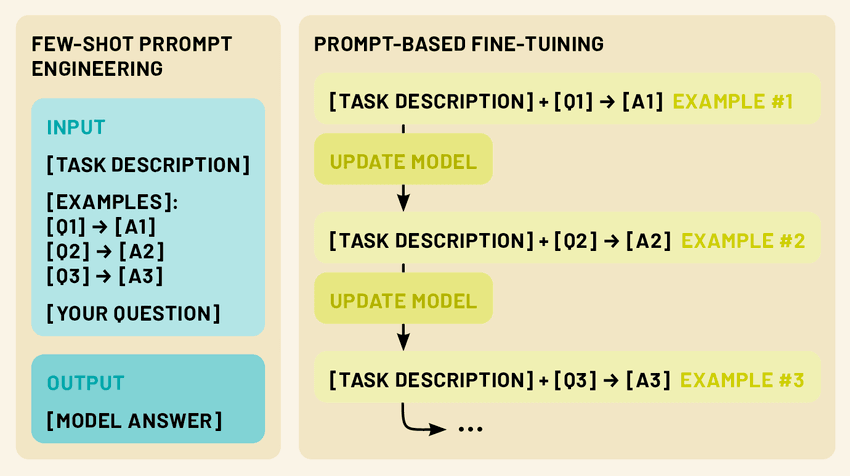
Ajustement fin des LLM : Adapter les modèles avec des données limitées
Alors que l'incitation à quelques essais est une technique puissante pour adapter les LLM à de nouvelles tâches sans modifier le modèle lui-même, le réglage fin offre un moyen de mettre à jour les paramètres du modèle pour une performance encore meilleure sur des tâches ou des domaines spécifiques. Le réglage fin nous permet d'exploiter les vastes connaissances encodées dans les LLM pré-entraînés tout en les adaptant à nos besoins spécifiques en n'utilisant qu'une petite quantité de données spécifiques à la tâche.
Comprendre le réglage fin dans le contexte des LLM
Le réglage fin d'un LLM consiste à prendre un modèle pré-entraîné et à l'entraîner davantage sur un ensemble de données plus petit et spécifique à une tâche. Ce processus permet au modèle d'adapter les représentations apprises aux nuances de la tâche ou du domaine cible. Le principal avantage du réglage fin est qu'il s'appuie sur la richesse des connaissances et la compréhension de la langue déjà présentes dans le modèle pré-entraîné, ce qui nécessite beaucoup moins de données et de ressources informatiques que l'entraînement d'un modèle à partir de zéro.
Dans le contexte des LLM, le réglage fin se concentre généralement sur l'ajustement des poids des couches supérieures du réseau, qui sont responsables des caractéristiques les plus spécifiques à la tâche, tout en laissant les couches inférieures (qui capturent des modèles linguistiques plus généraux) largement inchangées. Cette approche, souvent appelée "apprentissage par transfert", permet au modèle de conserver sa compréhension générale du langage tout en développant des capacités spécialisées pour la tâche cible.
Techniques d'ajustement de quelques tirs
Le réglage fin à quelques reprises pousse le concept de réglage fin un peu plus loin en tentant d'adapter le modèle à l'aide d'un très petit nombre d'exemples - généralement de l'ordre de 10 à 100 échantillons par classe ou par tâche. Cette approche est particulièrement utile lorsque les données étiquetées pour la tâche cible sont rares ou coûteuses à obtenir. Parmi les techniques clés de la mise au point à l'aide d'un petit nombre d'exemples, on peut citer les suivantes :
Mise au point basée sur des invites : Cette méthode combine les idées des messages-guides à quelques secondes d'intervalle avec les mises à jour des paramètres. Le modèle est affiné sur un petit ensemble de données où chaque exemple est formaté comme une paire invite-complétion, similaire aux messages-guides à quelques secondes d'intervalle.
Approches de méta-apprentissage : Des techniques telles que Méta-apprentissage agnostique (MAML) peuvent être adaptées à la mise au point des LLM à quelques reprises. Ces méthodes visent à trouver un bon point d'initialisation qui permet au modèle de s'adapter rapidement à de nouvelles tâches avec un minimum de données.
Réglage fin basé sur l'adaptateur : Au lieu de mettre à jour tous les paramètres du modèle, cette approche introduit de petits modules "adaptateurs" entre les couches du modèle pré-entraîné. Seuls ces adaptateurs sont formés à la nouvelle tâche, ce qui réduit le nombre de paramètres pouvant être formés et le risque d'oubli catastrophique.
Apprentissage en contexte : Certaines approches récentes tentent d'affiner les LLM pour mieux réaliser l'apprentissage en contexte, en améliorant leur capacité à s'adapter à de nouvelles tâches par le seul biais de messages-guides.
L'incitation à quelques coups de feu ou la mise au point : Choisir la bonne approche
Lorsqu'il s'agit d'adapter les LLM à des tâches spécifiques, l'incitation à quelques coups et le réglage fin offrent tous deux des solutions puissantes. Cependant, chaque méthode a ses propres forces et limites, et le choix de la bonne approche dépend de plusieurs facteurs.
Atouts et limites de chaque méthode
Prompt à l'action : Points forts :
Ne nécessite aucune mise à jour des paramètres du modèle, ce qui permet de conserver le modèle original.
Très flexible et adaptable à la volée
Pas de temps de formation ou de ressources informatiques supplémentaires nécessaires
Utile pour le prototypage et l'expérimentation rapides
Limites:
Les performances peuvent être moins régulières, en particulier pour les tâches complexes.
Limité par les capacités et les connaissances initiales du modèle
Peut éprouver des difficultés dans des domaines ou des tâches hautement spécialisés
Mise au point : Points forts :
Obtient souvent de meilleurs résultats dans des tâches spécifiques
Peut adapter le modèle à de nouveaux domaines et à un vocabulaire spécialisé
Des résultats plus cohérents pour des données similaires
Potentiel d'apprentissage et d'amélioration continus
Limites:
Nécessite un temps de formation et des ressources informatiques supplémentaires
Risque d'oubli catastrophique s'il n'est pas géré avec soin
Risque de surajustement sur les petits ensembles de données
Moins flexible ; nécessite une nouvelle formation en cas de modification importante des tâches
Facteurs à prendre en compte lors de la sélection d'une technique
Plusieurs facteurs doivent être pris en compte lors de la sélection d'une technique :
Disponibilité des données : Si vous disposez d'une petite quantité de données de haute qualité spécifiques à une tâche, il est préférable de procéder à un réglage fin. Pour les tâches pour lesquelles les données spécifiques sont très limitées, voire inexistantes, il est préférable d'opter pour des messages courts.
Complexité des tâches: Les tâches simples qui sont proches du domaine de pré-entraînement du modèle peuvent fonctionner correctement avec des messages courts. Les tâches plus complexes ou spécialisées bénéficient souvent d'un réglage fin.
Contraintes de ressources : Tenez compte des ressources informatiques disponibles et des contraintes de temps. Les messages courts sont généralement plus rapides et moins gourmands en ressources.
Exigences en matière de flexibilité: Si vous devez vous adapter rapidement à différentes tâches ou changer fréquemment d'approche, les messages à répétition offrent une plus grande flexibilité.
Exigences de performance : Pour les applications nécessitant une précision et une cohérence élevées, un réglage fin permet souvent d'obtenir de meilleurs résultats, en particulier lorsque les données spécifiques à la tâche sont suffisantes.
Vie privée et sécurité : Si l'on travaille avec des données sensibles, il peut être préférable d'utiliser des messages courts, car il n'est pas nécessaire de partager les données pour les mises à jour du modèle.
Applications pratiques des techniques Few-Shot pour les LLM
Les techniques d'apprentissage à court terme ont ouvert un large éventail d'applications pour les modèles d'apprentissage à long terme dans divers domaines, permettant à ces modèles de s'adapter rapidement à des tâches spécifiques avec un minimum d'exemples.
Tâches de traitement du langage naturel :
Classification des textes : Les techniques "Few-shot" permettent aux LLM de classer le texte dans des catégories prédéfinies avec seulement quelques exemples par catégorie. Cette technique est utile pour l'étiquetage du contenu, la détection du spam et la modélisation des sujets.
Analyse des sentiments : Les LLM peuvent s'adapter rapidement à des tâches d'analyse de sentiments spécifiques à un domaine, en comprenant les nuances de l'expression des sentiments dans différents contextes.
Reconnaissance d'entités nommées (NER) : L'apprentissage en quelques étapes permet aux LLM d'identifier et de classer des entités nommées dans des domaines spécialisés, tels que l'identification de composés chimiques dans la littérature scientifique.
Réponse aux questions : Les LLM peuvent être adaptés pour répondre à des questions dans des domaines ou des formats spécifiques, ce qui renforce leur utilité dans les systèmes de service à la clientèle et de recherche d'informations.
Adaptations spécifiques à un domaine :
Juridique : Des techniques peu complexes permettent aux LLM de comprendre et de générer des documents juridiques, de classer des affaires juridiques et d'extraire des informations pertinentes à partir de contrats avec une formation minimale spécifique au domaine.
Médical : Les LLM peuvent être adaptés à des tâches telles que le résumé de rapports médicaux, la classification de maladies à partir de symptômes et la prédiction d'interactions médicamenteuses en n'utilisant qu'un petit nombre d'exemples médicaux.
Technique : Dans des domaines tels que l'ingénierie ou l'informatique, l'apprentissage par petites touches permet aux MFR de comprendre et de produire des contenus techniques spécialisés, de déboguer des codes ou d'expliquer des concepts complexes à l'aide d'une terminologie spécifique au domaine.
Applications multilingues et interlinguistiques :
Traduction dans les langues à faibles ressources: Les techniques "Few-shot" peuvent aider les LLM à effectuer des tâches de traduction pour des langues pour lesquelles les données disponibles sont limitées.
Transfert interlinguistique : Les modèles formés dans des langues à ressources élevées peuvent être adaptés pour effectuer des tâches dans des langues à faibles ressources grâce à l'apprentissage en quelques étapes.
Adaptation des tâches multilingues : Les LLM peuvent rapidement s'adapter pour effectuer la même tâche dans plusieurs langues avec seulement quelques exemples dans chaque langue.
Défis et limites des techniques à peu d'images
Bien que les techniques à faible tir pour les LLM offrent un potentiel énorme, elles s'accompagnent également de plusieurs défis et limitations qui doivent être abordés.
Problèmes de cohérence et de fiabilité :
Variabilité des performances : Les méthodes à faible tirage peuvent parfois produire des résultats incohérents, en particulier dans le cas de tâches complexes ou de cas particuliers.
Sensibilité rapide : De petites modifications dans la formulation de l'invite ou dans le choix des exemples peuvent entraîner des variations significatives dans la qualité des résultats.
Limites spécifiques à la tâche : Certaines tâches peuvent être intrinsèquement difficiles à apprendre à partir de quelques exemples seulement, ce qui conduit à des performances sous-optimales.
Considérations éthiques et préjugés :
Amplification des préjugés : L'apprentissage en quelques étapes pourrait amplifier les biais présents dans les exemples limités fournis, ce qui pourrait conduire à des résultats injustes ou discriminatoires.
Manque de robustesse : Les modèles adaptés à l'aide de techniques à faible tirage peuvent être plus sensibles aux attaques adverses ou aux entrées inattendues.
Transparence et explicabilité : Il peut être difficile de comprendre et d'expliquer comment le modèle arrive à ses conclusions dans des scénarios à court terme.
Ressources informatiques et efficacité :
Limitations de la taille du modèle : Au fur et à mesure que les LLM se développent, les exigences de calcul pour le réglage fin deviennent de plus en plus contraignantes, ce qui peut limiter l'accessibilité.
Temps d'inférence : Les invites complexes à quelques caractères peuvent augmenter le temps d'inférence, ce qui peut avoir un impact sur les applications en temps réel.
Consommation d'énergie : Les ressources informatiques requises pour le déploiement à grande échelle des techniques à quelques coups soulèvent des questions d'efficacité énergétique et d'impact sur l'environnement.
La résolution de ces défis et limitations est cruciale pour le développement continu et le déploiement responsable des techniques d'apprentissage à court terme dans les LLM. Au fur et à mesure que la recherche progresse, nous pouvons nous attendre à voir des solutions innovantes qui améliorent la fiabilité, l'équité et l'efficacité de ces méthodes puissantes.
Le bilan
L'incitation et le réglage fin à quelques reprises représentent des approches révolutionnaires, permettant aux LLM de s'adapter rapidement à des tâches spécialisées avec un minimum de données. Comme nous l'avons exploré, ces techniques offrent une flexibilité et une efficacité sans précédent pour adapter les LLM à diverses applications dans tous les secteurs, qu'il s'agisse d'améliorer les tâches de traitement du langage naturel ou de permettre des adaptations spécifiques à un domaine dans des domaines tels que la santé, le droit et la technologie.
Bien qu'il reste des défis à relever, notamment en ce qui concerne la cohérence, les considérations éthiques et l'efficacité des calculs, le potentiel de l'apprentissage à court terme dans les LLM est indéniable. À mesure que la recherche continue de progresser, en s'attaquant aux limites actuelles et en découvrant de nouvelles stratégies d'optimisation, nous pouvons nous attendre à des applications encore plus puissantes et polyvalentes de ces techniques. L'avenir de l'IA ne réside pas seulement dans des modèles plus grands, mais aussi dans des modèles plus intelligents et plus adaptables - et l'apprentissage à court terme ouvre la voie à cette nouvelle ère de modèles de langage intelligents, efficaces et hautement spécialisés, capables de comprendre et de répondre à nos besoins en constante évolution.


