
Llama 3.1 vs. LLMs propriétaires : Une analyse coûts-avantages pour les entreprises



Le paysage des grands modèles de langage (LLM) est devenu un champ de bataille entre les modèles à poids ouvert comme le Le lama de Meta 3.1 et les offres propriétaires des géants de la technologie comme OpenAI. Alors que les entreprises naviguent sur ce terrain complexe, la décision d'adopter un modèle ouvert ou d'investir dans une solution à source fermée a des implications significatives pour l'innovation, les coûts et la stratégie à long terme en matière d'IA.
Llama 3.1, en particulier sa formidable version avec le paramètre 405B, s'est imposé comme un concurrent de taille face aux principaux modèles à code source fermé tels que GPT-4o et Claude 3.5. Cette évolution a contraint les entreprises à réévaluer leur approche de la mise en œuvre de l'IA, en tenant compte de facteurs allant au-delà des simples mesures de performance.
Dans cette analyse, nous nous pencherons sur les compromis coûts-avantages entre Llama 3.1 et les LLM propriétaires, en fournissant aux décideurs d'entreprise un cadre complet pour faire des choix éclairés concernant leurs investissements dans l'IA.
Comparaison des coûts
Frais de licence : Modèles propriétaires ou ouverts
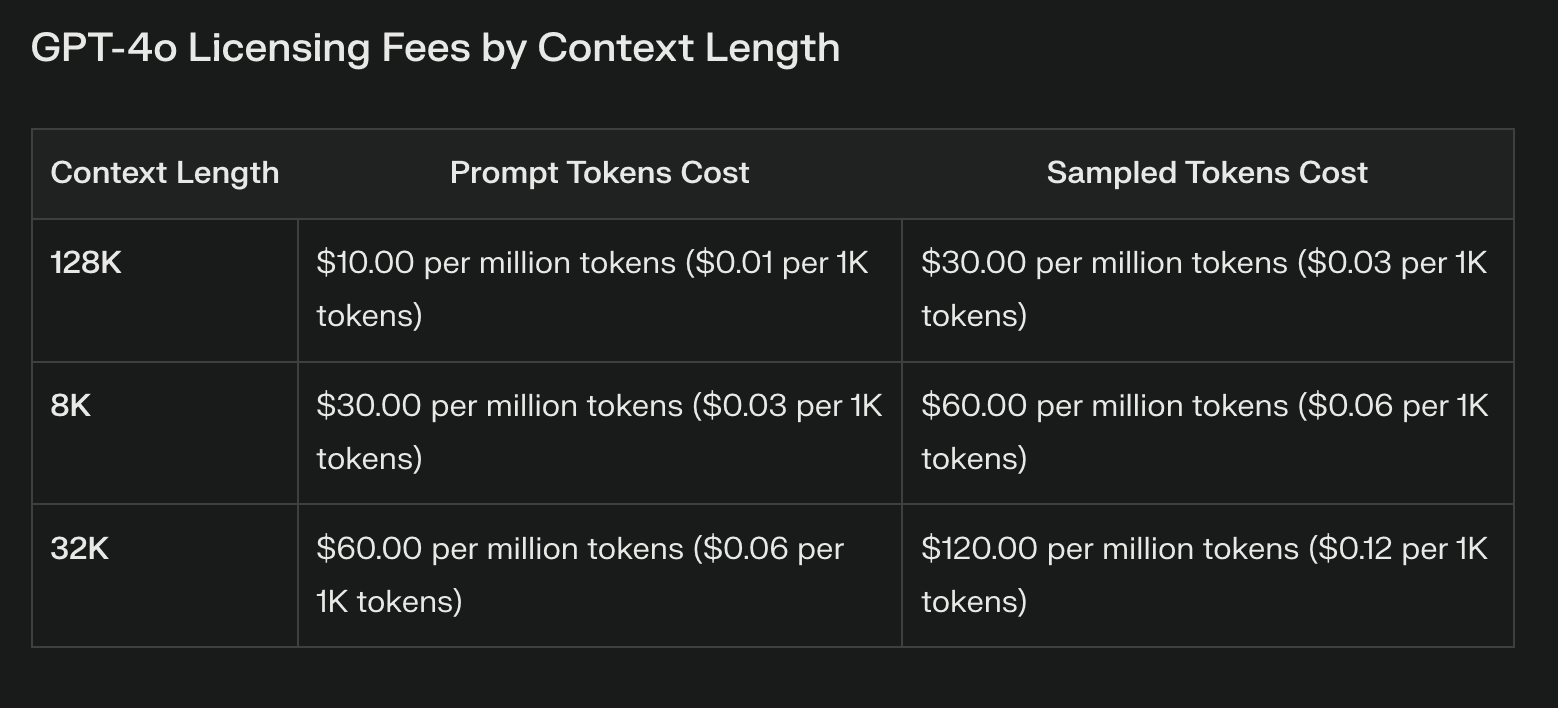
La différence de coût la plus apparente entre Llama 3.1 et les modèles propriétaires réside dans les frais de licence. Les LLM propriétaires s'accompagnent souvent de coûts récurrents substantiels, qui peuvent augmenter considérablement en fonction de l'utilisation. Ces frais, bien qu'ils donnent accès à une technologie de pointe, peuvent grever les budgets et limiter l'expérimentation.
Llama 3.1, avec ses poids ouverts, élimine complètement les frais de licence. Cette économie peut être substantielle, en particulier pour les entreprises qui prévoient de vastes déploiements d'IA. Toutefois, il est essentiel de noter que l'absence de frais de licence n'équivaut pas à des coûts nuls.
Coûts d'infrastructure et de déploiement
Si Llama 3.1 permet d'économiser sur les licences, il exige d'importantes ressources de calcul, en particulier pour le modèle des paramètres 405B. Les entreprises doivent investir dans une infrastructure matérielle solide, comprenant souvent des grappes de GPU haut de gamme ou des ressources informatiques en nuage. Par exemple, l'exécution efficace du modèle 405B complet peut nécessiter plusieurs GPU NVIDIA H100, ce qui représente une dépense d'investissement substantielle.
Les modèles propriétaires, généralement accessibles par le biais d'API, déchargent le fournisseur de ces coûts d'infrastructure. Cela peut être avantageux pour les entreprises qui ne disposent pas des ressources ou de l'expertise nécessaires pour gérer une infrastructure d'IA complexe. Toutefois, les appels d'API en grand nombre peuvent aussi rapidement accumuler des coûts, qui risquent de dépasser les économies initiales réalisées sur l'infrastructure.

Maintenance et mises à jour continues
Le maintien d'un modèle de poids ouvert tel que Llama 3.1 nécessite un investissement continu en expertise et en ressources. Les entreprises doivent allouer un budget pour :
Mises à jour et ajustements réguliers du modèle
Correctifs de sécurité et gestion des vulnérabilités
Optimisation des performances et amélioration de l'efficacité
Les modèles propriétaires incluent souvent ces mises à jour dans le cadre de leur service, ce qui réduit potentiellement la charge des équipes internes. Toutefois, cette commodité s'accompagne d'un contrôle réduit sur le processus de mise à jour et de perturbations potentielles pour les modèles affinés.
Comparaison des performances
Résultats de l'analyse comparative de diverses tâches
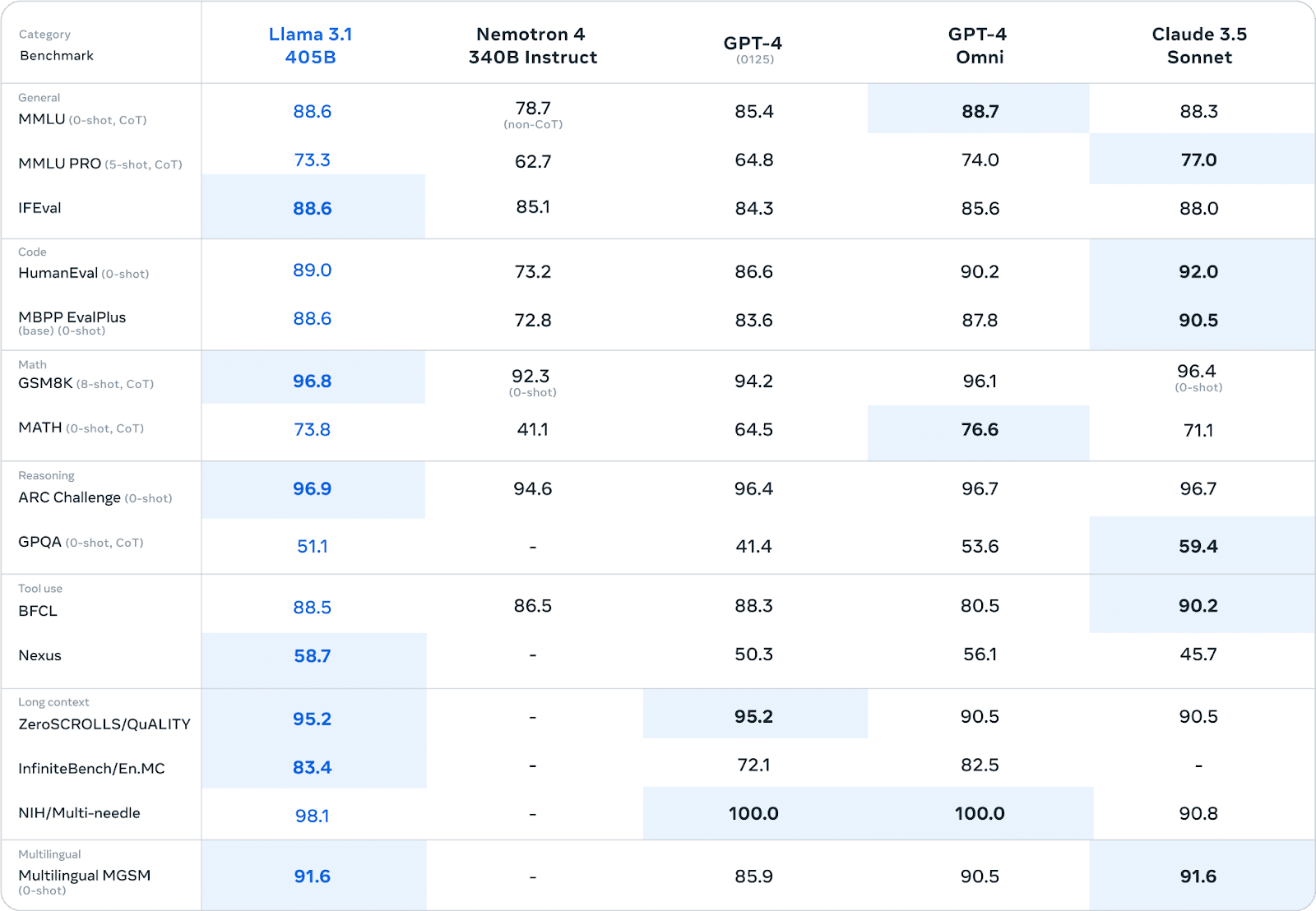
Llama 3.1 a démontré des performances impressionnantes dans divers benchmarks, rivalisant souvent avec les modèles propriétaires, voire les surpassant. Lors d'évaluations humaines approfondies et de tests automatisés, la version des paramètres 405B a montré des performances comparables à celles des principaux modèles à code source fermé dans des domaines tels que :
Connaissances générales et raisonnement
Génération de code et débogage
Résolution de problèmes mathématiques
Compétence multilingue
Par exemple, dans le test MMLU (Massive Multitask Language Understanding), Llama 3.1 405B a obtenu un score de 86,4%, ce qui le place en concurrence directe avec des modèles comme le GPT-4.
Performances réelles en entreprise
Si les critères de référence fournissent des informations précieuses, les performances réelles dans les entreprises constituent le véritable test des capacités d'un LLM.
Ici, la situation est plus nuancée :
Avantage de la personnalisation : Les entreprises qui utilisent Llama 3.1 font état d'avantages significatifs liés à l'affinement du modèle sur des données spécifiques à un domaine. Cette personnalisation se traduit souvent par des performances supérieures à celles des modèles propriétaires disponibles sur le marché pour des tâches spécialisées.
Génération de données synthétiques : La capacité de Llama 3.1 à générer des données synthétiques s'est avérée précieuse pour les entreprises qui cherchent à augmenter leurs ensembles de données de formation ou à simuler des scénarios complexes.
Compromis d'efficacité: Certaines entreprises ont constaté que si les modèles propriétaires peuvent avoir un léger avantage en termes de performance, la possibilité de créer des modèles spécialisés et efficaces grâce à des techniques telles que la distillation de modèles avec Llama 3.1 permet d'obtenir de meilleurs résultats globaux dans les environnements de production.
Considérations relatives à la latence : Les modèles propriétaires accessibles via l'API peuvent offrir une latence plus faible pour les requêtes individuelles, ce qui peut être crucial pour les applications en temps réel. Toutefois, les entreprises qui utilisent Llama 3.1 sur du matériel dédié font état de performances plus régulières en cas de charge élevée.
Il convient de noter que les comparaisons de performances dépendent fortement des cas d'utilisation spécifiques et des détails de la mise en œuvre. Les entreprises doivent procéder à des tests approfondis dans leurs environnements spécifiques afin d'évaluer précisément les performances.
Considérations à long terme
Le développement futur des LLM est un facteur critique dans la prise de décision. Llama 3.1 bénéficie d'une itération rapide menée par une communauté mondiale de chercheurs, ce qui peut conduire à des améliorations décisives. Les modèles propriétaires, soutenus par des entreprises bien financées, offrent des mises à jour régulières et la possibilité d'intégrer des technologies propriétaires.
Les Marché du LLM est susceptible d'être perturbé. Comme les modèles ouverts tels que Llama 3.1 approchent ou dépassent les performances des alternatives propriétaires, nous pourrions assister à une tendance à la banalisation des modèles de base et à une spécialisation accrue. Les nouvelles réglementations en matière d'IA pourraient également avoir un impact sur la viabilité des différentes approches de LLM.
Il est essentiel de s'aligner sur les stratégies d'entreprise plus larges en matière d'IA. L'adoption de Llama 3.1 peut favoriser le développement d'une expertise interne en matière d'IA, tandis que l'engagement en faveur de modèles propriétaires peut conduire à des partenariats stratégiques avec des géants de la technologie.
Cadre décisionnel
Les scénarios qui favorisent le Llama 3.1 sont les suivants :
Applications industrielles hautement spécialisées nécessitant une personnalisation poussée
Entreprises disposant de solides équipes internes d'IA capables de gérer des modèles
Les entreprises privilégient la souveraineté des données et le contrôle total des processus d'IA.
Les scénarios favorisant les modèles propriétaires sont les suivants :
Nécessité d'un déploiement immédiat avec une infrastructure minimale
Nécessité d'une assistance étendue de la part des fournisseurs et d'accords de niveau de service (SLA) garantis
Intégration avec les écosystèmes d'IA propriétaires existants
Le bilan
Le choix entre Llama 3.1 et les LLM propriétaires représente un point de décision critique pour les entreprises qui naviguent dans le paysage de l'IA. Bien que Llama 3.1 offre une flexibilité sans précédent, un potentiel de personnalisation et des économies sur les frais de licence, il exige un investissement important dans l'infrastructure et l'expertise. Les modèles propriétaires offrent une facilité d'utilisation, un support solide et des mises à jour régulières, mais au prix d'un contrôle réduit et d'un verrouillage potentiel du fournisseur. En fin de compte, la décision dépend des besoins spécifiques de l'entreprise, de ses ressources et de sa stratégie à long terme en matière d'IA. En pesant soigneusement les facteurs décrits dans cette analyse, les décideurs peuvent tracer la voie qui correspond le mieux aux objectifs et aux capacités de leur organisation.


