
Les 5 principales erreurs et défis de la mise en œuvre de LangChain



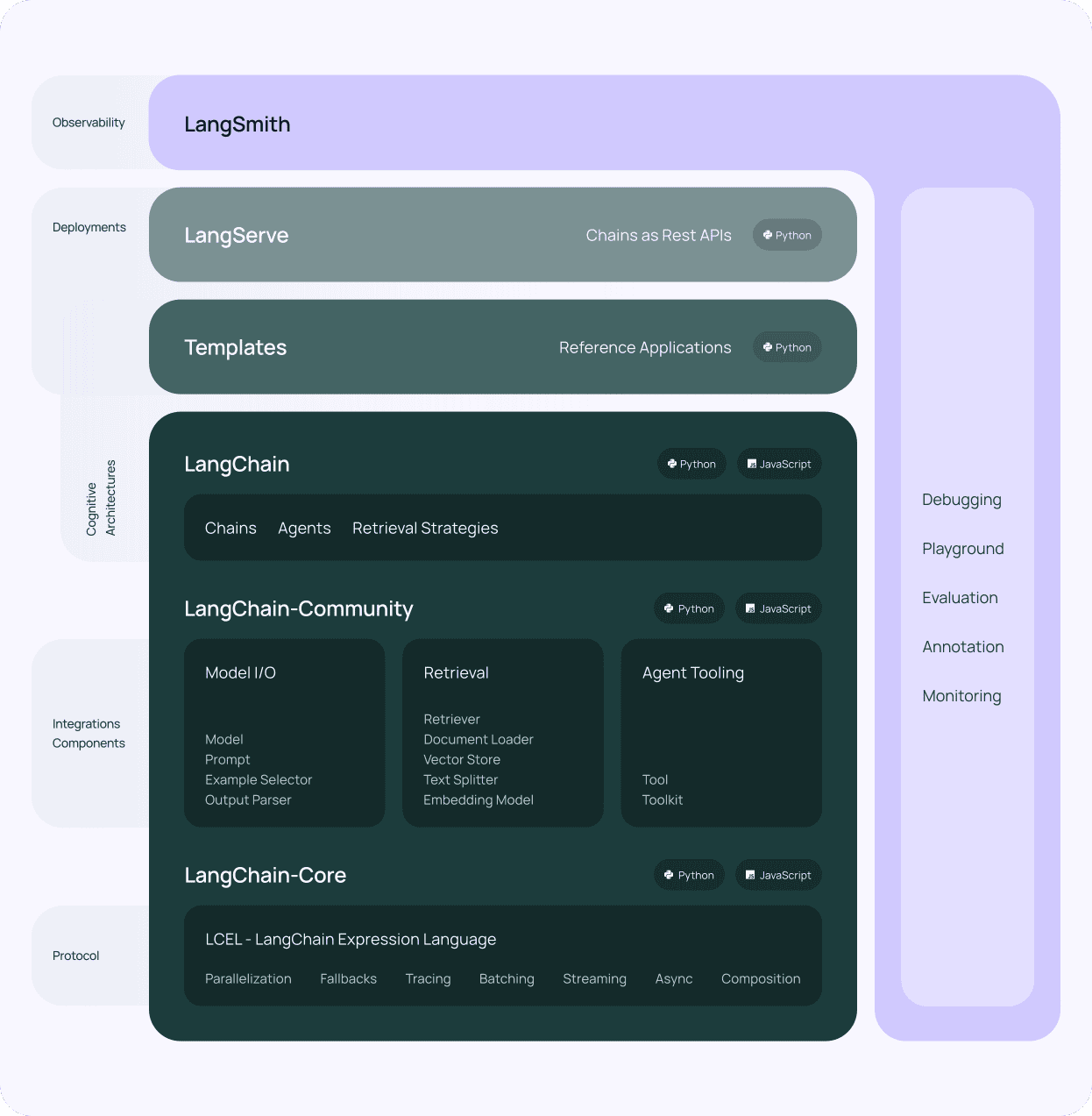
LangChainLangChain, un cadre populaire pour la création d'applications basées sur des modèles de langage, a connu un succès important dans la communauté de l'intelligence artificielle. Sa promesse de simplifier la création de systèmes complexes de traitement du langage naturel a attiré les développeurs et les entreprises. Cependant, comme pour toute nouvelle technologie, il existe des erreurs et des défis communs qui peuvent entraver la réussite [...]
Dans cet article de blog, nous allons explorer les 5 principales erreurs et défis de LangChain, en fournissant des conseils pour vous aider à naviguer dans ces pièges et à tirer le meilleur parti de ce cadre puissant.
Erreur #1 : Compliquer à l'excès l'architecture
L'une des erreurs les plus fréquentes lorsque l'on travaille avec LangChain est de trop compliquer l'architecture. La conception de LangChain repose sur une base d'abstractions, telles que l'élément Chaîne, Agentet Outil les interfaces. Bien que ces abstractions aient pour but d'assurer la flexibilité et la réutilisation, elles peuvent également conduire à une complexité inutile si elles ne sont pas utilisées judicieusement.
Par exemple, les hiérarchies de classes de LangChain peuvent être très profondes, avec plusieurs niveaux d'héritage. La hiérarchie des classes de l'agent, par exemple, comprend Agent, AgentExecutor, ZeroShotAgentet Agent conversationnelentre autres. Ce niveau d'abstraction peut rendre difficile pour les développeurs de comprendre comment initialiser correctement un agent ou quelles méthodes remplacer pour la personnalisation.
Un autre exemple de complication excessive est l'utilisation de l'interface Callback pour accéder au cycle de vie des chaînes et des agents. La documentation ne parvient pas toujours à expliquer clairement les différentes méthodes de rappel, telles que on_chain_start, on_tool_start, et on_agent_actionet quand ils sont invoqués. Ce manque de clarté peut entraîner des confusions et des difficultés dans la mise en œuvre de la journalisation personnalisée, de la surveillance ou de la gestion des états.
L'impact d'une architecture trop compliquée est important. Elle peut entraver les efforts de personnalisation, car les développeurs ont du mal à comprendre comment modifier le cadre pour l'adapter à leurs besoins spécifiques. Le débogage devient plus difficile, car la recherche de problèmes à travers plusieurs couches d'abstraction peut prendre du temps et s'avérer frustrante. En outre, la maintenabilité en pâtit, car un code complexe est plus difficile à comprendre, à mettre à jour et à étendre au fil du temps.
Erreur #2 : négliger la documentation et les exemples
Une autre erreur fréquente lorsque l'on travaille avec LangChain est de négliger l'importance d'une documentation claire et complète. La documentation de LangChain, bien qu'étendue, manque souvent de clarté et de profondeur pour permettre aux développeurs de comprendre pleinement les capacités et les meilleures pratiques du framework.
L'une des lacunes de la documentation de LangChain est le manque d'explications détaillées sur les concepts clés, les paramètres par défaut et les entrées/sorties attendues des différents composants. Les développeurs se retrouvent souvent à parcourir le code source ou à procéder par essais et erreurs pour comprendre comment utiliser efficacement certaines fonctionnalités.
En outre, les exemples fournis dans la documentation sont souvent trop simplistes et ne présentent pas de cas d'utilisation réels. Si ces exemples peuvent aider les utilisateurs à démarrer, ils ne les préparent pas suffisamment aux complexités et aux nuances rencontrées dans les applications pratiques.
Les conséquences de la négligence de la documentation et des exemples sont importantes. Les développeurs qui découvrent LangChain peuvent avoir du mal à comprendre comment exploiter efficacement le framework, ce qui entraîne des frustrations et des pertes de temps. Même les utilisateurs expérimentés peuvent se retrouver à passer beaucoup de temps à comprendre comment mettre en œuvre des fonctionnalités spécifiques ou résoudre des problèmes qui auraient pu être facilement résolus avec une documentation plus claire.
En l'absence d'exemples diversifiés et concrets, les développeurs risquent également de passer à côté d'informations précieuses et de bonnes pratiques susceptibles d'améliorer leurs projets LangChain. Ils risquent de réinventer la roue par inadvertance ou de prendre des décisions de conception sous-optimales simplement parce qu'ils n'étaient pas au courant des modèles ou des approches existants.
Erreur #3 : Ne pas tenir compte des incohérences et des comportements cachés
Une troisième erreur que les développeurs commettent souvent lorsqu'ils travaillent avec LangChain est de négliger les incohérences et les comportements cachés au sein du framework. Les composants de LangChain peuvent parfois présenter des comportements inattendus ou incohérents qui ne sont pas clairement documentés, ce qui entraîne une certaine confusion et des bogues potentiels.
Par exemple, le comportement du Mémoire tampon de conversation peut différer selon qu'il est utilisé avec un composant Chaîne de conversation ou un AgentExecutor. Dans le cas d'une chaîne de conversation, la mémoire tampon de conversation ajoute automatiquement les réponses de l'IA à la mémoire, alors que ce n'est pas le cas pour un AgentExecutor. De telles incohérences, lorsqu'elles ne sont pas explicitement documentées, peuvent conduire à des hypothèses incorrectes et à des mises en œuvre défectueuses.
Un autre exemple de comportement caché est la façon dont certaines chaînes, comme la LLMMathChainLa chaîne LLMMathChain utilise un format différent pour ses paramètres d'entrée par rapport aux autres chaînes. Au lieu d'attendre un dictionnaire d'entrées, la chaîne LLMMath attend un seul paramètre "question". Ces incohérences dans les formats d'entrée peuvent compliquer la composition et la mise en œuvre de la chaîne LLMMathChain. intégrer différentes chaînes de manière transparente.
L'impact de la négligence des incohérences et des comportements cachés est important. Les développeurs peuvent passer des heures à déboguer des problèmes qui découlent d'hypothèses incorrectes sur le comportement des composants. Le manque de cohérence dans le comportement et les formats d'entrée entre les différentes parties du framework peut rendre difficile le raisonnement sur le flux de données et la construction d'applications robustes.
En outre, les comportements cachés peuvent conduire à des bogues subtils qui peuvent passer inaperçus au cours du développement mais faire surface dans les environnements de production, provoquant des échecs inattendus ou des résultats incorrects. L'identification et la correction de ces problèmes peuvent prendre du temps et nécessiter une connaissance approfondie des éléments internes du framework.
Erreur #4 : Sous-estimer les défis de l'intégration
Une autre erreur fréquente lorsque l'on travaille avec LangChain est de sous-estimer les défis liés à l'intégration du framework dans les bases de code, les outils et les flux de travail existants. Le fait que LangChain soit conçu en fonction des opinions et qu'il s'appuie sur des modèles spécifiques, tels que l'enchaînement de méthodes et les callbacks, peut créer des frictions lorsqu'on essaie de l'incorporer dans un environnement de développement établi.
Par exemple, l'intégration de LangChain dans un cadre web tel que FastAPI peut nécessiter une traduction entre différents types de demandes, de réponses et d'exceptions. Les développeurs doivent soigneusement faire correspondre les entrées et sorties de LangChain aux conventions du cadre web, ce qui peut ajouter de la complexité et des points de défaillance potentiels.
De même, lors de l'intégration de LangChain avec des bases de données ou des files d'attente de messages, les développeurs peuvent être amenés à sérialiser et désérialiser les objets LangChain, ce qui peut s'avérer fastidieux et source d'erreurs. La dépendance du cadre à l'égard de certains modèles de conception n'est pas toujours conforme aux meilleures pratiques ou aux exigences de l'infrastructure existante.
L'utilisation par LangChain d'un état global et de singletons peut également poser des problèmes dans les environnements concurrents ou distribués. Le cadrage et l'injection corrects des dépendances peuvent nécessiter des solutions de contournement ou des modifications du comportement par défaut du framework, ce qui ajoute de la complexité au processus d'intégration.
Les conséquences d'une sous-estimation des défis de l'intégration sont importantes. Les développeurs peuvent se retrouver à passer plus de temps que prévu sur les tâches d'intégration, ce qui retarde le calendrier du projet et augmente les coûts de développement. La complexité accrue de l'intégration peut également entraîner des bogues et des problèmes de maintenabilité, la base de code devenant plus difficile à comprendre et à modifier au fil du temps.
De plus, les frictions causées par les défis d'intégration peuvent conduire certains développeurs à abandonner LangChain et à opter pour des solutions alternatives plus compatibles avec leur stack technologique et leurs workflows existants. Cela peut conduire à des occasions manquées d'exploiter les puissantes capacités de LangChain et potentiellement à des implémentations sous-optimales.
Erreur #5 : ignorer les considérations de performance et de fiabilité
Une cinquième erreur que les développeurs commettent souvent lorsqu'ils travaillent avec LangChain est d'ignorer les considérations de performance et de fiabilité. Si LangChain fournit un ensemble d'outils puissants pour créer des applications basées sur des modèles de langue, l'optimisation de ces applications pour des cas d'utilisation en production nécessite de prêter une attention particulière aux facteurs de performance et de fiabilité.
L'un des défis de l'optimisation des applications LangChain est la complexité inhérente à l'architecture du cadre. Avec plusieurs couches d'abstraction et de nombreux composants impliqués dans le traitement des entrées et sorties de la langue, il peut être difficile d'identifier les goulets d'étranglement et les inefficacités en matière de performances. Les développeurs peuvent avoir besoin d'une compréhension approfondie des éléments internes du cadre pour profiler et optimiser efficacement leurs applications.
Un autre problème est que les paramètres par défaut de LangChain ne sont pas toujours adaptés aux environnements de production. La configuration par défaut du framework peut donner la priorité à la facilité d'utilisation et à la flexibilité plutôt qu'aux performances et à la rentabilité. Par exemple, les paramètres par défaut pour la mise en cache, l'utilisation de jetons et les appels d'API peuvent ne pas être optimisés en termes de latence ou de coût, ce qui conduit à des performances sous-optimales dans des scénarios réels.
Ignorer les considérations de performance et de fiabilité peut avoir des conséquences importantes. Les applications construites avec LangChain peuvent souffrir de temps de réponse lents, d'une latence élevée et d'une augmentation des coûts d'exploitation. Dans les applications critiques ou destinées aux utilisateurs, de mauvaises performances peuvent entraîner une dégradation de l'expérience des utilisateurs et une perte de confiance de leur part.
En outre, des problèmes de fiabilité peuvent survenir si les applications LangChain ne sont pas correctement testées et contrôlées dans des environnements de production. Des défaillances inattendues, des dépassements de délais ou des contraintes de ressources peuvent entraîner l'absence de réponse des applications ou la production de résultats incorrects. Le débogage et le dépannage de ces problèmes peuvent s'avérer difficiles, car ils nécessitent une connaissance approfondie du cadre et de l'infrastructure sous-jacente.
Pour limiter ces risques, les développeurs doivent prendre en compte de manière proactive les facteurs de performance et de fiabilité lorsqu'ils créent des applications LangChain. Il s'agit notamment d'évaluer soigneusement l'impact sur les performances des différentes options de configuration, d'effectuer des tests de performance approfondis et de surveiller les applications en production afin d'identifier et de résoudre rapidement tout problème.
Surmonter les erreurs et les défis de LangChain avec Skim AI
Dans cet article de blog, nous avons exploré les 5 principales erreurs et défis de LangChain que les développeurs et les entreprises rencontrent souvent lorsqu'ils travaillent avec ce puissant framework. Qu'il s'agisse de compliquer à l'excès l'architecture, de négliger la documentation, d'ignorer les incohérences ou de sous-estimer les défis d'intégration, ces erreurs peuvent considérablement entraver le succès des implémentations de LangChain. De plus, ignorer les considérations de performance et de fiabilité peut conduire à des résultats sous-optimaux et même à des échecs dans les environnements de production.
Cependant, il est important de reconnaître que ces défis ne sont pas insurmontables. En abordant ces questions de manière proactive et en faisant appel à des experts, les entreprises peuvent surmonter les obstacles associés à LangChain et exploiter tout le potentiel de ce framework pour leurs applications. Avec LangChain, votre entreprise peut construire des solutions performantes, maintenables et fiables qui génèrent de la valeur et de l'innovation dans ses projets d'IA.


