
Les 5 meilleures bases de données vectorielles pour les applications d'IA et de LLM en entreprise



La capacité à stocker, gérer et rechercher efficacement de vastes quantités de données à haute dimension est devenue primordiale pour les entreprises d'aujourd'hui. Les bases de données vectorielles sont apparues comme une solution puissante, permettant aux organisations de libérer le plein potentiel des applications alimentées par l'IA. Ces bases de données spécialisées sont conçues pour traiter des données vectorielles complexes, facilitant la recherche rapide de similarités, les recommandations et d'autres fonctionnalités avancées. Alors que l'IA continue d'imprégner tous les aspects de la technologie moderne, les bases de données vectorielles sont devenues un outil indispensable pour les entreprises qui cherchent à acquérir un avantage concurrentiel.
Dans ce blog, nous aborderons les 5 principales bases de données vectorielles du marché :
1. Pomme de pin
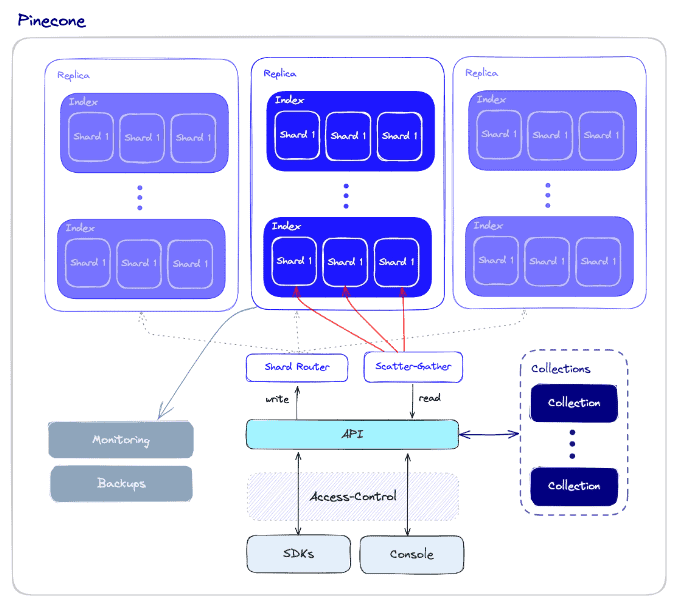
Pinecone est une base de données vectorielles entièrement gérée qui privilégie les performances élevées et la facilité d'utilisation. Elle combine des algorithmes avancés de recherche vectorielle avec des fonctionnalités telles que le filtrage et l'infrastructure distribuée pour fournir une recherche vectorielle rapide et fiable à n'importe quelle échelle.
L'un des principaux avantages de Pinecone est sa nature sans serveur, qui évite aux développeurs d'avoir à approvisionner ou à maintenir l'infrastructure. Ils peuvent ainsi se concentrer sur la création d'applications tandis que Pinecone s'occupe des complexités liées à la gestion et à la mise à l'échelle de la base de données. Pinecone s'intègre de manière transparente avec les cadres d'apprentissage automatique et les sources de données les plus courants, ce qui en fait un choix polyvalent pour un large éventail d'applications, notamment la recherche sémantique, les recommandations, la détection d'anomalies et les réponses aux questions.
2. Chroma

Chroma est une base de données vectorielles conçue pour une intégration transparente avec des modèles et des cadres d'apprentissage automatique. Son objectif principal est de simplifier le processus de création d'applications alimentées par l'IA en fournissant des capacités efficaces de stockage, de récupération et de recherche de similarité des vecteurs.
L'une des principales caractéristiques de Chroma est l'indexation en temps réel, qui permet aux développeurs d'intégrer rapidement de nouvelles données dans leurs applications. En outre, Chroma prend en charge le stockage des métadonnées, ce qui permet d'associer des informations contextuelles aux vecteurs. Le déploiement est facilité par l'interface conviviale et la documentation complète de Chroma. En prenant en charge différentes mesures de distance et différents algorithmes d'indexation, Chroma garantit des performances optimales dans différents cas d'utilisation, tels que la recherche sémantique, les systèmes de recommandation et la détection d'anomalies.
3. Qdrant
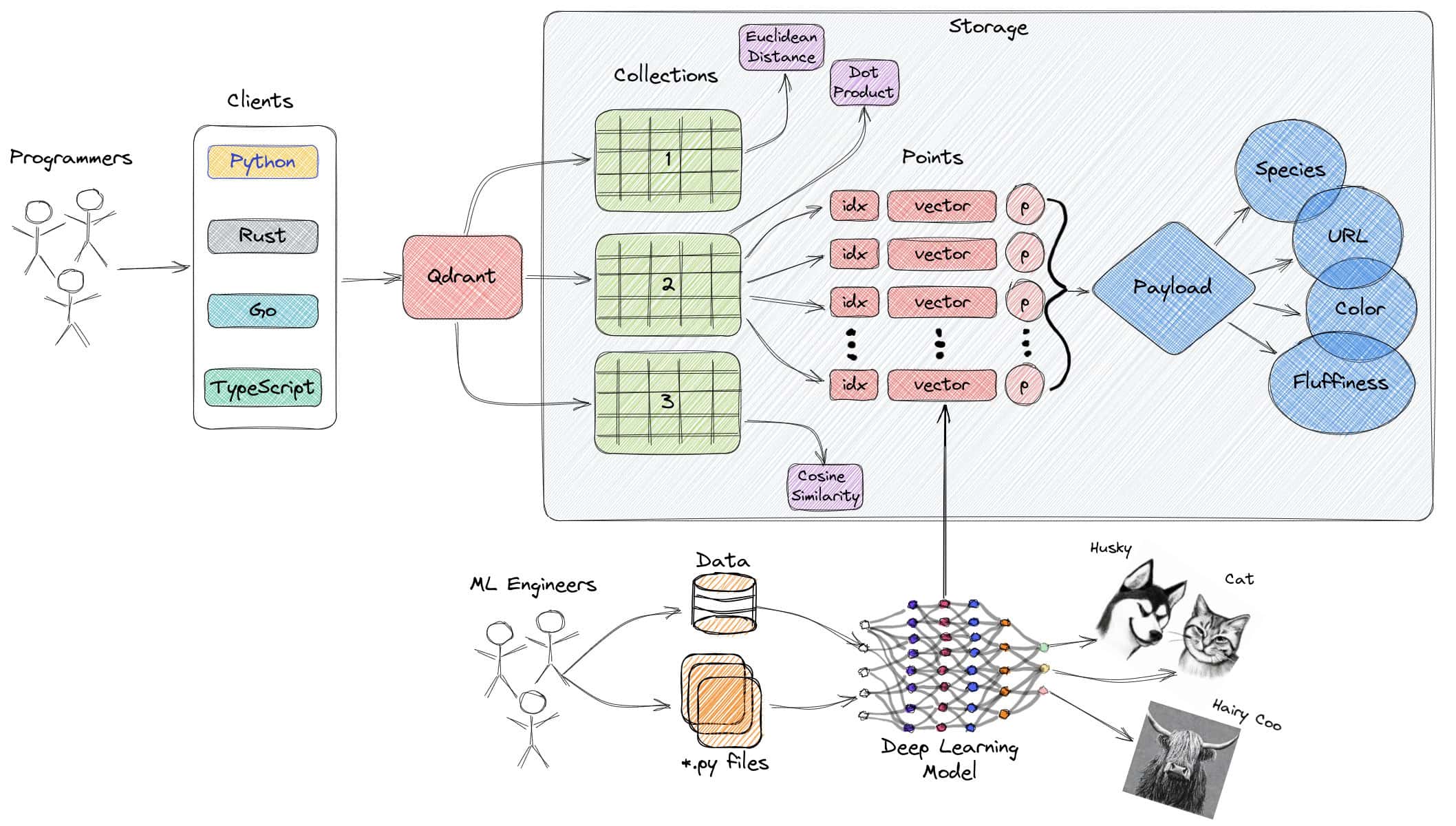
Qdrant est un moteur de recherche de similarités vectorielles open-source écrit en Rust, réputé pour sa vitesse et son évolutivité. Il fournit une API pratique pour le stockage, la recherche et la gestion des vecteurs avec des métadonnées supplémentaires, ce qui permet aux développeurs de transformer les encodeurs de réseaux neuronaux et les embeddings en applications prêtes à la production pour la mise en correspondance, la recherche, la recommandation et bien plus encore.
Qdrant offre une pléthore de fonctionnalités, notamment des mises à jour en temps réel, un filtrage avancé, des index distribués et des options de déploiement cloud-natives. Conçu pour gérer des milliards de vecteurs et des charges de requêtes élevées, Qdrant s'intègre de manière transparente avec des frameworks d'apprentissage automatique, ce qui en fait un outil puissant pour construire des solutions de recherche vectorielle dans divers cas d'utilisation, tels que la recherche sémantique, les recommandations, les chatbots, les moteurs d'appariement et la détection d'anomalie.
4. Weaviate
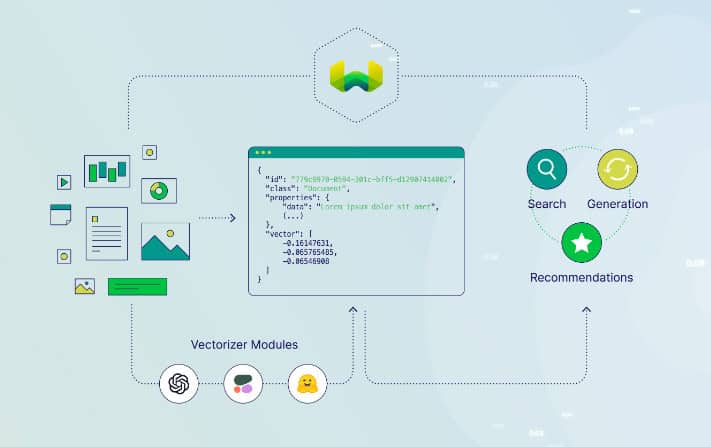
Weaviate est une base de données vectorielles open-source qui privilégie la vitesse, l'évolutivité et la facilité d'utilisation. Elle se distingue en permettant le stockage d'objets et de vecteurs, ce qui la rend bien adaptée pour combiner la recherche vectorielle avec le filtrage structuré. Weaviate propose une API basée sur GraphQL, des opérations CRUD, une mise à l'échelle horizontale et des options de déploiement cloud-native, offrant ainsi une solution flexible et évolutive aux développeurs.
En outre, Weaviate intègre des modules pour les tâches NLP, la configuration automatique des schémas et la vectorisation personnalisée, ce qui améliore encore ses capacités. Il prend en charge diverses métriques de distance et types d'index, s'intégrant de manière transparente avec les outils d'apprentissage automatique populaires, les bases de données de graphes et les environnements Kubernetes. L'architecture modulaire et les fonctionnalités étendues de Weaviate en font un outil puissant pour créer des applications de recherche vectorielle dans divers cas d'utilisation, notamment la recherche sémantique, la recherche d'images, les recommandations et les graphes de connaissances.
5. Milvus
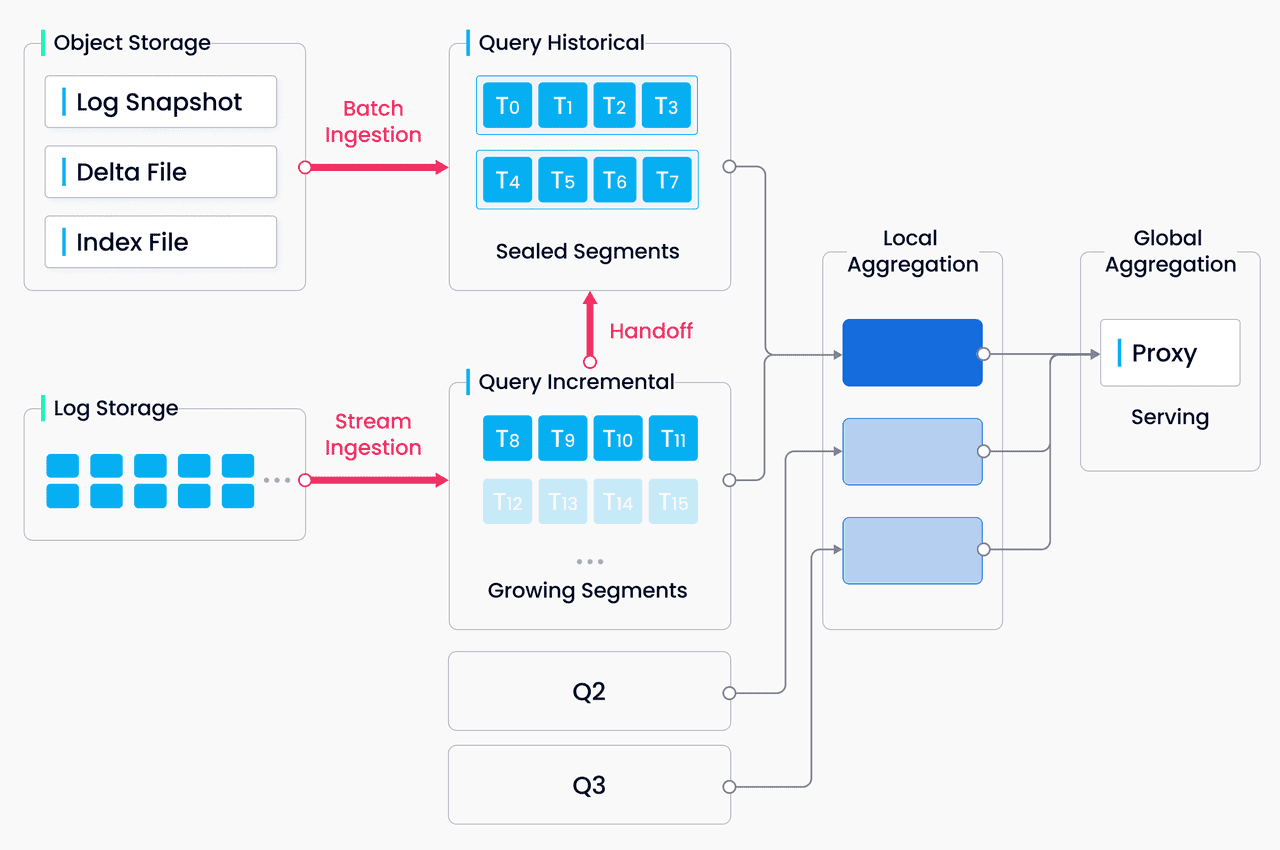
Milvus est une base de données vectorielle open-source conçue spécifiquement pour la gestion de l'intégration, la recherche de similarités et les applications d'IA évolutives. Elle offre un ensemble complet de fonctionnalités, notamment la prise en charge d'ordinateurs hétérogènes, la fiabilité du stockage, des mesures complètes et une architecture "cloud-native".
L'une des forces de Milvus réside dans sa capacité à fournir des performances cohérentes dans différents environnements de déploiement. Milvus fournit une API flexible qui prend en charge divers index, mesures de distance et types de requêtes, ce qui permet aux développeurs d'adapter la base de données à leurs besoins spécifiques. Elle peut s'adapter à des milliards de vecteurs et être étendue à l'aide de plugins personnalisés, ce qui garantit son évolutivité et son extensibilité. Milvus s'intègre de manière transparente aux frameworks d'apprentissage automatique, aux opérateurs Kubernetes et aux outils d'analyse, ce qui en fait un choix polyvalent pour un large éventail d'applications, telles que la recherche d'images et de vidéos, les moteurs de recommandation, les chatbots et la détection d'anomalies.
Choisir la bonne base de données vectorielle pour votre entreprise
Alors que l'adoption de l'IA et de l'apprentissage automatique continue de s'accélérer, les bases de données vectorielles se sont imposées comme un composant essentiel pour créer de puissantes applications d'IA d'entreprise. Des solutions entièrement gérées comme Pinecone aux options open-source comme Qdrant et Chroma, le paysage des bases de données vectorielles offre une gamme variée d'options adaptées aux différents besoins organisationnels et cas d'utilisation.
Que vous construisiez un moteur de recherche sémantique, un système de recommandation ou toute autre application alimentée par l'IA, les bases de données vectorielles constituent la base qui permet d'exploiter tout le potentiel des modèles d'apprentissage automatique. En permettant une recherche rapide par similarité, un filtrage avancé et une intégration transparente avec les frameworks les plus courants, ces bases de données permettent aux développeurs de se concentrer sur la création de solutions innovantes sans se préoccuper des complexités sous-jacentes de la gestion des données vectorielles.


