
Comprendre les structures de tarification du LLM : Entrées, sorties et fenêtres contextuelles



Pour les stratégies d'IA des entreprises, il est essentiel de comprendre les structures de tarification des grands modèles de langage (LLM) pour une gestion efficace des coûts. Les coûts opérationnels associés aux LLM peuvent rapidement augmenter en l'absence d'une surveillance adéquate, ce qui peut entraîner des hausses de coûts inattendues susceptibles de faire dérailler les budgets et d'entraver l'adoption généralisée de l'IA. T
e billet de blog se penche sur les éléments clés des structures de tarification du LLM et fournit des informations qui vous aideront à optimiser votre utilisation du LLM et à contrôler vos dépenses.
La tarification du LLM s'articule généralement autour de trois éléments principaux : jetons d'entrée, jetons de sortie et fenêtres contextuelles. Chacun de ces éléments joue un rôle important dans la détermination du coût global de l'utilisation des LLM dans vos applications. En acquérant une compréhension approfondie de ces composants, vous serez mieux équipé pour prendre des décisions éclairées sur la sélection des modèles, les modèles d'utilisation et les stratégies d'optimisation.
Éléments de base de la tarification du LLM
Jetons d'entrée
Les jetons d'entrée représentent le texte introduit dans le LLM pour traitement. Il s'agit de vos invites, de vos instructions et de tout contexte supplémentaire fourni au modèle. Le nombre de jetons d'entrée a un impact direct sur le coût de chaque appel d'API, car le traitement d'un plus grand nombre de jetons nécessite davantage de ressources informatiques.
Jetons de sortie
Les jetons de sortie sont le texte généré par le LLM en réponse à vos données. Le prix des jetons de sortie diffère souvent de celui des jetons d'entrée, reflétant l'effort de calcul supplémentaire requis pour la génération de texte. La gestion de l'utilisation des jetons de sortie est essentielle pour contrôler les coûts, en particulier dans les applications qui génèrent de grands volumes de texte.
Fenêtres contextuelles
Les fenêtres contextuelles font référence à la quantité de texte précédent que le modèle peut prendre en compte pour générer des réponses. Des fenêtres contextuelles plus larges permettent une compréhension plus complète, mais ont un coût plus élevé en raison de l'utilisation accrue de jetons et des exigences en matière de calcul.
Jetons de saisie : Ce qu'ils sont et comment ils sont facturés
Les jetons d'entrée sont les unités fondamentales du texte traité par un LLM. Ils correspondent généralement à des parties de mots, les mots courants étant souvent représentés par un seul jeton et les mots moins courants étant divisés en plusieurs jetons. Par exemple, la phrase "Le renard brun rapide" peut être symbolisée par ["Le", "rapide", "bro", "wn", "renard"], ce qui donne 5 jetons d'entrée.
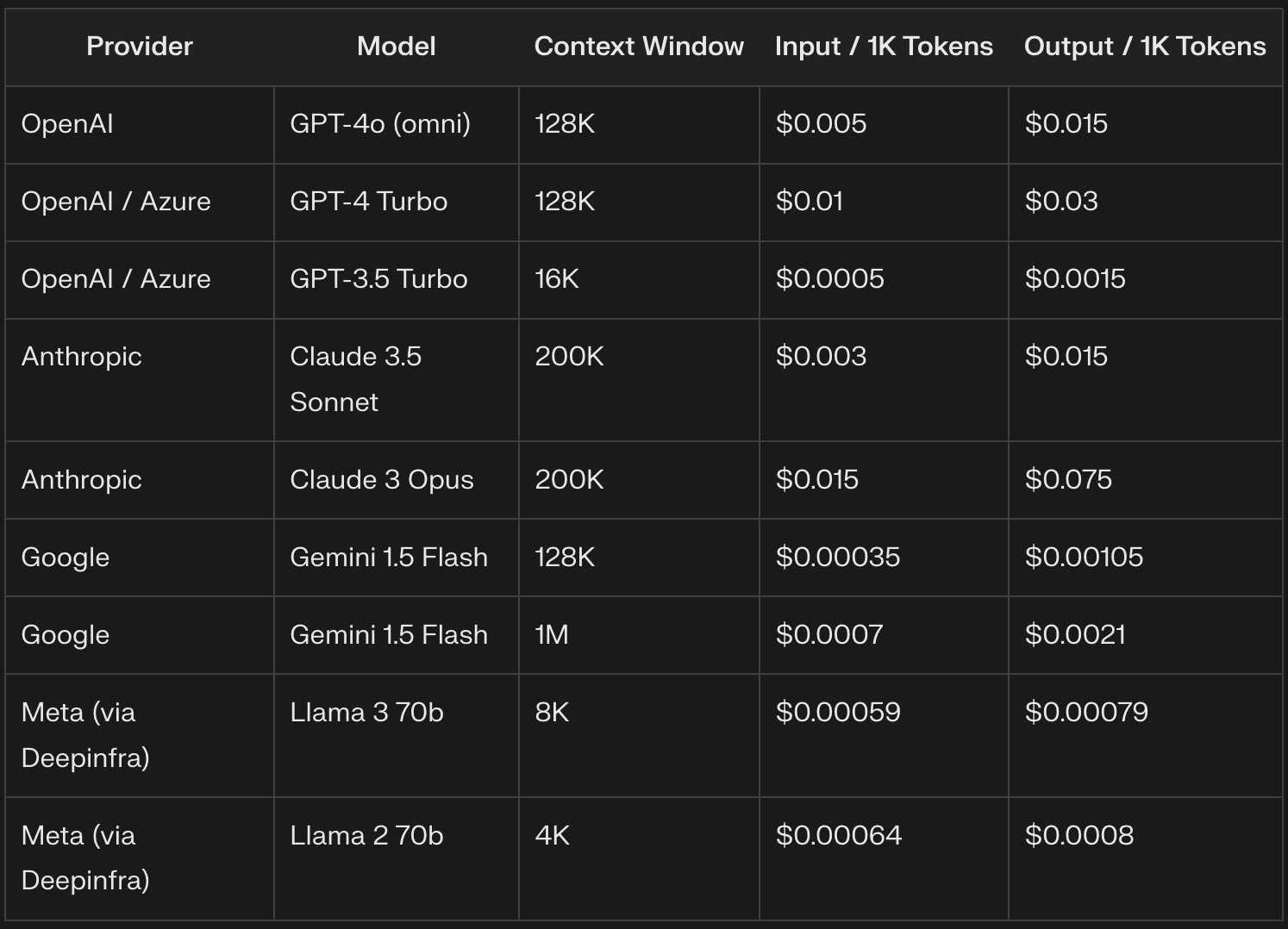
Les fournisseurs de LLM facturent souvent les jetons d'entrée sur la base d'un taux par millier de jetons. Par exemple, GPT-4o facture $5 pour 1 million de jetons d'entrée, ce qui équivaut à $0,005 pour 1 000 jetons d'entrée. La tarification exacte peut varier considérablement d'un fournisseur à l'autre et d'une version du modèle à l'autre, les modèles les plus avancés affichant généralement des tarifs plus élevés.
Pour gérer efficacement les coûts du LLM, envisagez les stratégies suivantes pour optimiser l'utilisation des jetons d'entrée :
Rédiger des messages-guides concis: Éliminez les mots inutiles et concentrez-vous sur des instructions claires et directes.
Utiliser un encodage efficace : Choisissez une méthode d'encodage qui représente votre texte avec moins de tokens.
Mettre en place des modèles d'invite : Développer et réutiliser des structures optimisées pour les tâches courantes.
En gérant soigneusement vos jetons d'entrée, vous pouvez réduire de manière significative les coûts associés à l'utilisation des LLM tout en maintenant la qualité et l'efficacité de vos applications d'IA.
Jetons de sortie : Comprendre les coûts
Les jetons de sortie représentent le texte généré par le LLM en réponse à votre entrée. Comme pour les jetons d'entrée, les jetons de sortie sont calculés en fonction du processus de tokénisation du modèle. Cependant, le nombre de jetons de sortie peut varier considérablement en fonction de la tâche et de la configuration du modèle. Par exemple, une question simple peut générer une réponse brève avec peu de jetons, alors qu'une demande d'explication détaillée peut donner lieu à des centaines de jetons.
Les fournisseurs de LLM tarifient souvent les jetons de sortie différemment des jetons d'entrée, généralement à un taux plus élevé en raison de la complexité informatique de la génération de texte. Par exemple, OpenAI facture $15 pour 1 million de jetons ($0,015 pour 1 000 jetons) pour le GPT-4o.
Optimiser l'utilisation des jetons de sortie et contrôler les coûts :
Définissez des limites claires de longueur de sortie dans vos invites ou appels API.
Utilisez des techniques telles que l'"apprentissage par petites touches" pour guider le modèle vers des réponses plus concises.
Mettre en œuvre un post-traitement pour éliminer le contenu inutile des résultats du programme LLM.
Envisager de mettre en cache les informations fréquemment demandées afin de réduire les appels redondants au LLM.
Fenêtres contextuelles : Le facteur de coût caché
Les fenêtres contextuelles déterminent la quantité de texte précédent que le LLM peut prendre en compte lors de la génération d'une réponse. Cette fonction est cruciale pour maintenir la cohérence des conversations et permettre au modèle de se référer à des informations antérieures. La taille de la fenêtre contextuelle peut avoir un impact significatif sur les performances du modèle, en particulier pour les tâches nécessitant une mémoire à long terme ou un raisonnement complexe.
Des fenêtres contextuelles plus grandes augmentent directement le nombre de jetons d'entrée traités par le modèle, ce qui entraîne des coûts plus élevés. Par exemple :
Un modèle avec une fenêtre contextuelle de 4 000 jetons traitant une conversation de 3 000 jetons facturera les 3 000 jetons.
La même conversation avec une fenêtre contextuelle de 8 000 jetons pourrait être facturée pour 7 000 jetons, y compris les parties antérieures de la conversation.
Cette mise à l'échelle peut entraîner une augmentation substantielle des coûts, en particulier pour les applications traitant de longs dialogues ou l'analyse de documents.
Pour optimiser l'utilisation de la fenêtre contextuelle :
Mettre en œuvre un dimensionnement dynamique du contexte en fonction des exigences de la tâche.
Utiliser des techniques de synthèse pour condenser les informations pertinentes issues de conversations plus longues.
Utiliser des approches de type fenêtre coulissante pour traiter les documents longs, en se concentrant sur les sections les plus pertinentes.
Envisagez d'utiliser des modèles plus petits et spécialisés pour les tâches qui ne nécessitent pas un contexte étendu.
En gérant soigneusement les fenêtres de contexte, vous pouvez trouver un équilibre entre le maintien de résultats de haute qualité et le contrôle des coûts LLM. N'oubliez pas que l'objectif est de fournir un contexte suffisant pour la tâche à accomplir sans gonfler inutilement l'utilisation des jetons et les dépenses associées.
Tendances futures en matière de tarification du LLM
Au fur et à mesure que le paysage du LLM évolue, nous pourrions assister à des changements dans les structures de prix :
Tarification à la tâche : Les modèles sont facturés en fonction de la complexité de la tâche plutôt que du nombre de jetons.
Modèles d'abonnement : Accès forfaitaire aux LLM avec des limites d'utilisation ou une tarification échelonnée.
La tarification basée sur la performance : Coûts liés à la qualité ou à la précision des résultats plutôt qu'à la quantité.
Impact des avancées technologiques sur les coûts
La recherche et le développement continus dans le domaine de l'IA peuvent conduire à.. :
Des modèles plus efficaces : Réduction des besoins de calcul, d'où une baisse des coûts opérationnels.
Techniques de compression améliorées : Méthodes améliorées pour réduire le nombre de jetons d'entrée et de sortie.
Intégration de l'informatique de pointe : Traitement local des tâches LLM, réduisant potentiellement les coûts de l'informatique en nuage.
Le bilan
Comprendre les structures de prix des LLM est essentiel pour une gestion efficace des coûts dans les applications d'IA d'entreprise. En saisissant les nuances des jetons d'entrée, des jetons de sortie et des fenêtres contextuelles, les entreprises peuvent prendre des décisions éclairées sur la sélection des modèles et les schémas d'utilisation. La mise en œuvre de techniques stratégiques de gestion des coûts, telles que l'optimisation de l'utilisation des jetons et l'exploitation de la mise en cache, peut permettre de réaliser des économies significatives.
Comme la technologie LLM continue d'évoluer, il est essentiel de rester informé des tendances en matière de prix et des stratégies d'optimisation émergentes pour maintenir des opérations d'IA rentables. N'oubliez pas que la gestion réussie des coûts du LLM est un processus continu qui nécessite une surveillance, une analyse et une adaptation permanentes pour garantir une valeur maximale de vos investissements dans l'IA.
Si vous souhaitez en savoir plus sur la manière dont votre entreprise peut exploiter plus efficacement les structures tarifaires du LLM, n'hésitez pas à nous contacter !


