
Comment construire des applications LLM puissantes avec des bases de données vectorielles + RAG - AI&YOU#55



La statistique/le fait de la semaine : 30% des entreprises utiliseront des bases de données vectorielles pour fonder leurs modèles d'IA générative d'ici 2026, contre 2% en 2023. (Gartner)
Les LLM tels que GPT-4, Claude et Llama 3 se sont imposés comme des outils puissants pour les entreprises qui mettent en œuvre le NLP, démontrant des capacités remarquables dans la compréhension et la génération de textes semblables à ceux des humains. Cependant, ils ont souvent du mal à tenir compte du contexte et à être précis, en particulier lorsqu'ils traitent des informations spécifiques à un domaine.
C'est pourquoi, dans l'édition de AI&YOU de cette semaine, nous explorons la manière dont ces défis sont relevés à travers trois blogs que nous avons publiés :
Combiner les bases de données vectorielles et RAG pour des applications LLM puissantes
Les 10 principaux avantages de l'utilisation d'une base de données vectorielles open-source
Les 5 meilleures bases de données vectorielles pour votre entreprise
Combiner les bases de données vectorielles et RAG pour des applications LLM puissantes - AI&YOU #55
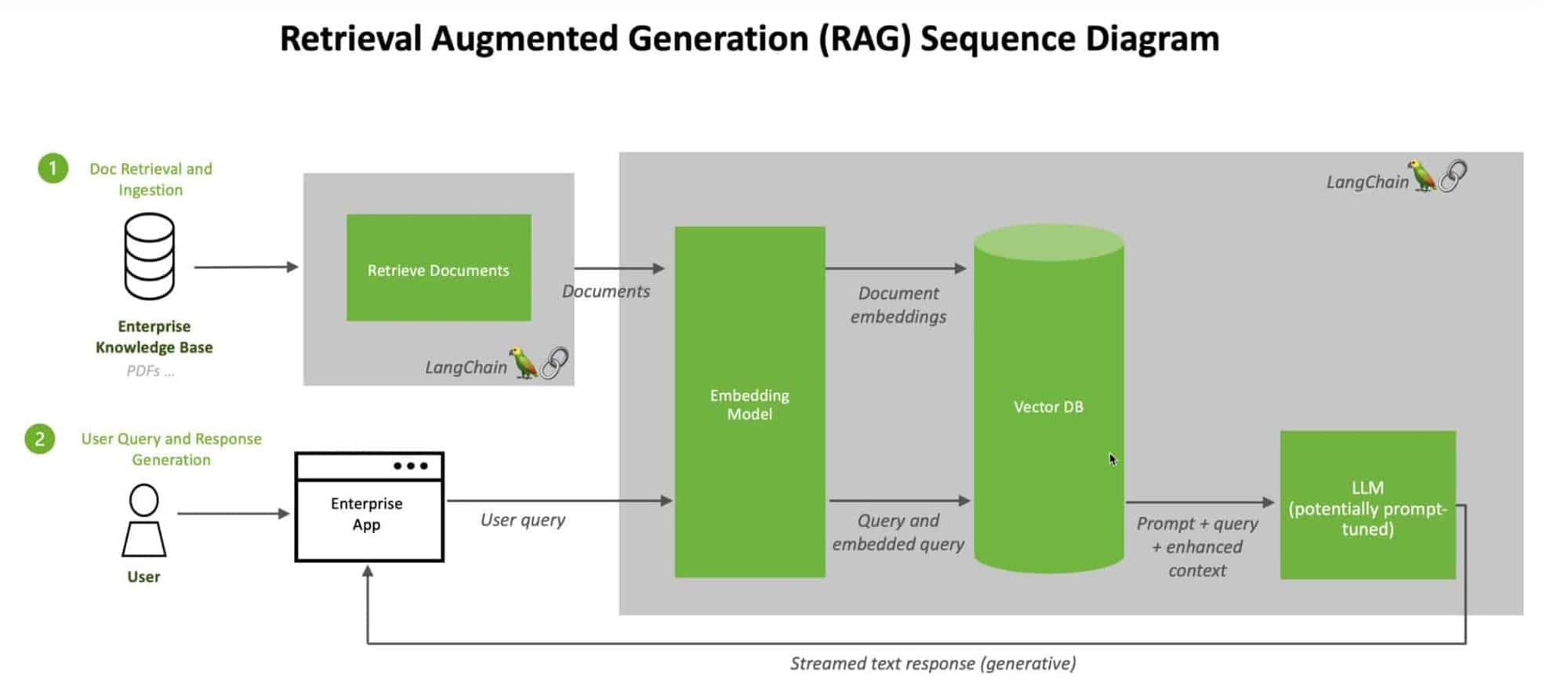
Pour relever ces défis, les chercheurs et les développeurs se sont tournés vers des techniques innovantes telles que la Génération Augmentée de Récupération (RAG) et les bases de données vectorielles. Le RAG améliore les LLM en leur permettant d'accéder à des bases de connaissances externes et d'en extraire des informations pertinentes, tandis que les bases de données vectorielles offrent une solution efficace et évolutive pour le stockage et l'interrogation de représentations de données à haute dimension.
La synergie entre les bases de données vectorielles et RAG
Les bases de données vectorielles et RAG forment une synergie puissante qui améliore les capacités des grands modèles de langage. Au cœur de cette synergie se trouve le stockage et l'extraction efficaces de l'intégration des bases de connaissances. Les bases de données vectorielles sont conçues pour traiter des représentations vectorielles de données à haute dimension. Elles permettent une recherche rapide et précise des similarités, ce qui permet aux LLM d'extraire rapidement des informations pertinentes de vastes bases de connaissances.
En intégrant les bases de données vectorielles à RAG, nous pouvons créer un pipeline transparent pour augmenter les réponses LLM avec des connaissances externes. Lorsqu'un LLM reçoit une requête, RAG peut rechercher efficacement la base de données vectorielle pour trouver les informations les plus pertinentes en fonction de l'intégration de la requête. Ces informations sont ensuite utilisées pour enrichir le contexte du LLM, ce qui lui permet de générer des réponses plus précises et plus informatives en temps réel.
Avantages de la combinaison des bases de données vectorielles et de RAG
La combinaison des bases de données vectorielles et de RAG offre plusieurs avantages significatifs pour les applications de modèles linguistiques de grande taille :
Amélioration de la précision et réduction des hallucinations
L'un des principaux avantages de la combinaison des bases de données vectorielles et du RAG est l'amélioration significative de la précision des réponses du LLM. En permettant aux MFR d'accéder à des connaissances externes pertinentes, les RAG contribuent à réduire l'occurrence des "hallucinations", c'est-à-dire les cas où le modèle génère des informations incohérentes ou incorrectes sur le plan factuel. En ayant la possibilité de récupérer et d'incorporer des informations spécifiques à un domaine à partir de sources fiables, les LLM peuvent produire des résultats plus précis et plus fiables.
Évolutivité et performance
Les bases de données vectorielles sont conçues pour s'adapter efficacement, ce qui leur permet de traiter de grands volumes de données à haute dimension. Cette évolutivité est cruciale lorsqu'il s'agit de traiter des bases de connaissances étendues qui doivent être recherchées et extraites en temps réel. En tirant parti de la puissance des bases de données vectorielles, RAG peut effectuer des recherches de similarité rapides et efficaces, ce qui permet aux LLM de générer des réponses rapidement sans compromettre la qualité des informations extraites.
Permettre des applications spécifiques à un domaine
La combinaison de bases de données vectorielles et de RAG ouvre de nouvelles possibilités pour la création d'applications LLM spécifiques à un domaine. En conservant des bases de connaissances spécifiques à divers domaines, les LLM peuvent être adaptés pour fournir des informations précises et pertinentes dans ces contextes. Cela permet de développer des assistants d'IA spécialisés, des chatbots et des systèmes de gestion des connaissances qui peuvent répondre aux besoins uniques de différents secteurs et cas d'utilisation.

Mise en œuvre de RAG avec des bases de données vectorielles
Pour exploiter la puissance de la combinaison des bases de données vectorielles et du RAG, il est essentiel de comprendre le processus de mise en œuvre.
Examinons les principales étapes de la mise en place d'un système RAG avec une base de données vectorielle :
Indexation et stockage des enchâssements de bases de connaissances : La première étape consiste à convertir les données textuelles de la base de connaissances en vecteurs à haute dimension à l'aide de modèles d'intégration tels que BERT, puis à indexer et à stocker ces intégrations dans la base de données vectorielle pour une recherche et une récupération efficaces des similarités.
Recherche d'informations pertinentes dans la base de données vectorielles: Lorsqu'un LLM reçoit une requête, le système RAG transforme la requête en une représentation vectorielle utilisant le même modèle d'intégration, et la base de données vectorielle effectue une recherche de similarité pour récupérer les intégrations de base de connaissances les plus pertinentes sur la base d'une métrique de similarité choisie.
Intégration de l'information récupérée dans les réponses au programme de gestion du cycle de vie (LLM) : Les informations pertinentes extraites de la base de données vectorielle sont intégrées dans le processus de génération de réponses du LLM, soit en les concaténant avec la requête originale, soit en utilisant des techniques telles que les mécanismes d'attention, ce qui permet au LLM de générer des réponses plus précises et plus informatives basées sur le contexte augmenté.
Choisir la bonne base de données vectorielle pour votre application : Le choix de la base de données vectorielle appropriée est crucial, car il doit tenir compte de facteurs tels que l'évolutivité, les performances, la facilité d'utilisation et la compatibilité avec votre pile technologique existante, ainsi que de vos exigences spécifiques telles que la taille de la base de connaissances, le volume des requêtes et le temps de latence souhaité pour les réponses.
Bonnes pratiques et considérations
Pour garantir le succès de votre mise en œuvre de RAG avec des bases de données vectorielles, il y a plusieurs bonnes pratiques et considérations à garder à l'esprit.
Optimisation de l'intégration des bases de connaissances pour la recherche :
La qualité de l'intégration des bases de connaissances est cruciale et nécessite l'expérimentation de différents modèles et techniques d'intégration, une mise au point sur des données spécifiques au domaine, ainsi qu'une mise à jour et une extension régulières de l'intégration au fur et à mesure que de nouvelles informations sont disponibles, afin de maintenir la pertinence et la précision des données.
Équilibrer la vitesse et la précision de l'extraction :
Il existe un compromis entre la vitesse d'extraction et la précision, ce qui nécessite des techniques telles que la recherche approximative du plus proche voisin pour accélérer l'extraction tout en conservant une précision acceptable, ainsi que la mise en cache d'incorporations fréquemment consultées et la mise en œuvre de stratégies d'équilibrage de la charge pour optimiser les performances.
Garantir la sécurité et la confidentialité des données :
La mise en place d'un stockage sécurisé des données, de contrôles d'accès et de techniques de cryptage telles que le cryptage homomorphique est essentielle pour empêcher les accès non autorisés et protéger les données sensibles dans les enchâssements de la base de connaissances, tout en respectant les réglementations en vigueur en matière de protection des données.
Surveillance et maintenance du système :
La surveillance continue de paramètres tels que la latence des requêtes, la précision de la recherche et l'utilisation des ressources, la mise en œuvre de mécanismes automatisés de surveillance et d'alerte, et l'établissement d'un programme de maintenance solide, comprenant des sauvegardes, des mises à jour et des réglages de performance, sont essentiels pour garantir la performance et la fiabilité à long terme du système RAG.
Exploiter la puissance des bases de données vectorielles et de RAG dans votre entreprise
Alors que l'IA continue de façonner notre avenir, il est crucial pour votre entreprise de rester à la pointe de ces avancées technologiques. En explorant et en mettant en œuvre des techniques de pointe telles que les bases de données vectorielles et RAG, vous pouvez exploiter tout le potentiel des grands modèles de langage et créer des systèmes d'IA plus intelligents, plus adaptables et offrant un meilleur retour sur investissement.
Les 10 principaux avantages de l'utilisation d'une base de données vectorielles open-source
Parmi les solutions de bases de données vectorielles, les bases de données vectorielles open-source offrent une combinaison convaincante de flexibilité, d'évolutivité et de rentabilité. En exploitant la puissance collective de la communauté open-source, ces bases de données vectorielles spécialisées redéfinissent la façon dont les organisations abordent la gestion et l'analyse des données.
Cette semaine, notre blog a également exploré les 10 principaux avantages de l'utilisation d'une base de données vectorielles open-source :
L'évolutivité et la rentabilité permettent une croissance transparente sans coûts élevés, en éliminant le verrouillage des fournisseurs et en fournissant une solution économique.
La flexibilité et la personnalisation permettent d'adapter la base de données à des besoins spécifiques, de modifier les fonctionnalités et d'intégrer les systèmes existants.
Le traitement efficace des données non structurées s'appuie sur des techniques telles que le NLP et l'intégration de vecteurs pour un stockage, une recherche et une analyse efficaces.
Une recherche vectorielle de similarité puissante facilite la récupération précise basée sur la similarité sémantique, permettant des applications telles que les recommandations personnalisées et la découverte intelligente de contenu.
L'intégration dans des écosystèmes à code source ouvert garantit l'interopérabilité avec des outils et des cadres complémentaires, ce qui améliore la productivité et favorise la collaboration.
Des mesures robustes de sécurité et de confidentialité des données donnent la priorité à la transparence, au cryptage, au contrôle d'accès et au respect des normes de conformité.
Les performances élevées et la gestion efficace des données permettent une exécution rapide des requêtes et une polyvalence pour diverses charges de travail.
La compatibilité avec l'analyse avancée et l'apprentissage automatique permet une intégration transparente avec des techniques et des cadres de pointe.
L'architecture évolutive et à l'épreuve du temps permet une croissance et une adaptation transparentes aux technologies émergentes et à l'évolution des besoins en matière de données.
L'innovation et le soutien de la communauté favorisent l'amélioration continue, le partage des connaissances et des ressources inestimables pour tirer parti de ces outils puissants.
Les 5 meilleures bases de données vectorielles pour votre entreprise
Outre les principaux avantages, nous avons également publié cette semaine un blog sur les 5 meilleures bases de données vectorielles pour votre entreprise :
1. Chroma
Chroma est conçu pour une intégration transparente avec des modèles et des cadres d'apprentissage automatique, ce qui simplifie le processus de création d'applications basées sur l'IA. Il offre un stockage vectoriel efficace, la récupération, la recherche de similarité, l'indexation en temps réel et le stockage des métadonnées. Il prend en charge diverses mesures de distance et algorithmes d'indexation pour des performances optimales dans des cas d'utilisation tels que la recherche sémantique, les recommandations et la détection d'anomalies.

2. Pomme de pin
Pinecone est une base de données vectorielles entièrement gérée, sans serveur, qui donne la priorité à la haute performance et à la facilité d'utilisation. Elle combine des algorithmes avancés de recherche vectorielle avec un filtrage et une infrastructure distribuée pour une recherche vectorielle rapide et fiable à grande échelle. Elle s'intègre de manière transparente avec des cadres d'apprentissage automatique et des sources de données pour des applications telles que la recherche sémantique, les recommandations, la détection d'anomalies et les réponses aux questions.
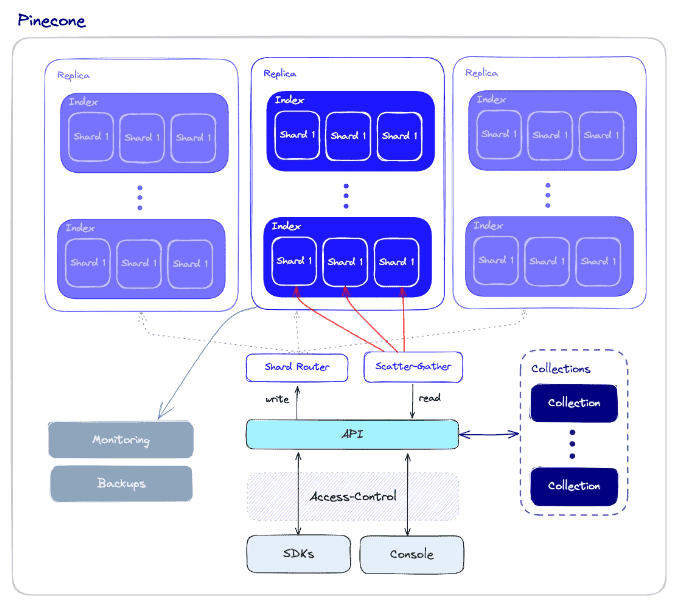
3. Qdrant
Qdrant est un moteur de recherche de similarités vectorielles open-source, rapide et évolutif, écrit en Rust. Il fournit une API pratique pour le stockage, la recherche et la gestion des vecteurs avec des métadonnées, permettant des applications prêtes à la production pour l'appariement, la recherche, la recommandation, et plus encore. Les fonctionnalités comprennent des mises à jour en temps réel, un filtrage avancé, des index distribués et des options de déploiement "cloud-native".
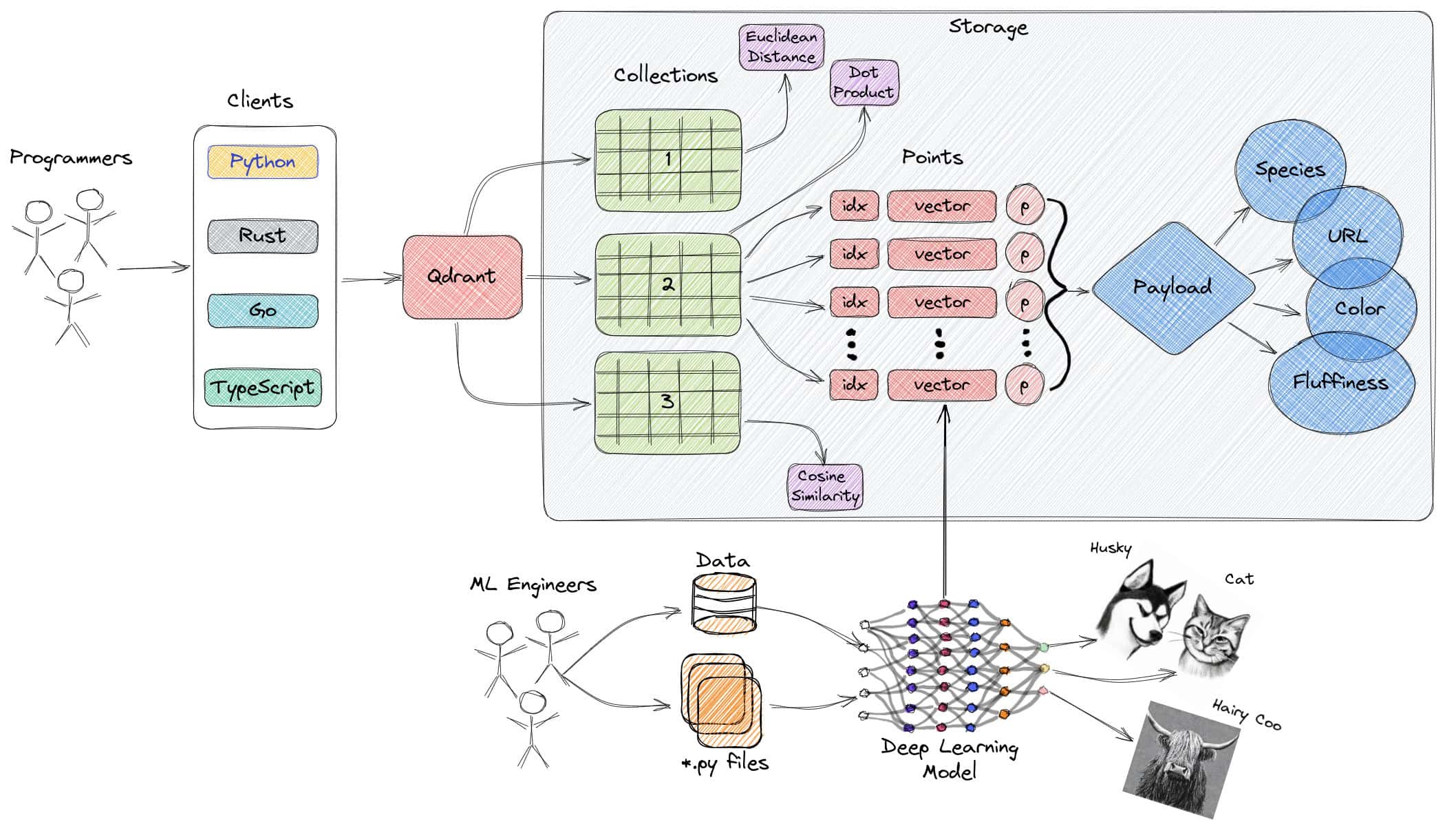
4. Weaviate
Weaviate est une base de données vectorielles open-source qui privilégie la vitesse, l'évolutivité et la facilité d'utilisation. Elle permet de stocker à la fois des objets et des vecteurs, en combinant la recherche vectorielle et le filtrage structuré. Elle propose une API basée sur GraphQL, des opérations CRUD, une mise à l'échelle horizontale et un déploiement en nuage. Incorpore des modules pour les tâches NLP, la configuration automatique des schémas et la vectorisation personnalisée.
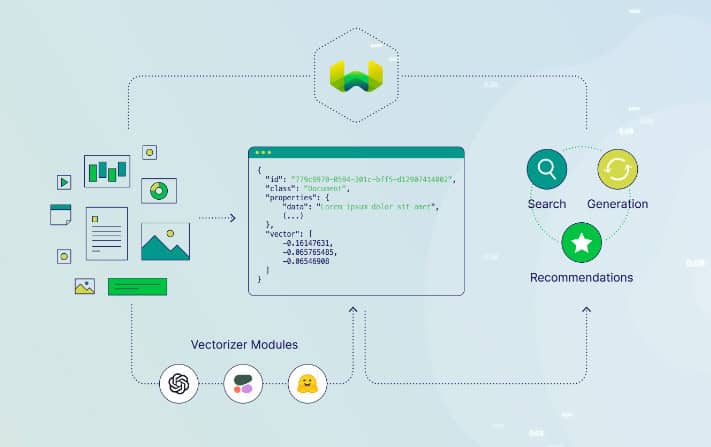
5. Milvus
Milvus est une base de données vectorielle open-source conçue pour la gestion de l'intégration, la recherche de similarités et les applications d'IA évolutives. Elle offre un support informatique hétérogène, une fiabilité de stockage, des mesures complètes et une architecture cloud-native. Elle fournit une API flexible pour les index, les mesures de distance et les types de requêtes, et peut évoluer jusqu'à des milliards de vecteurs avec des plugins personnalisés.
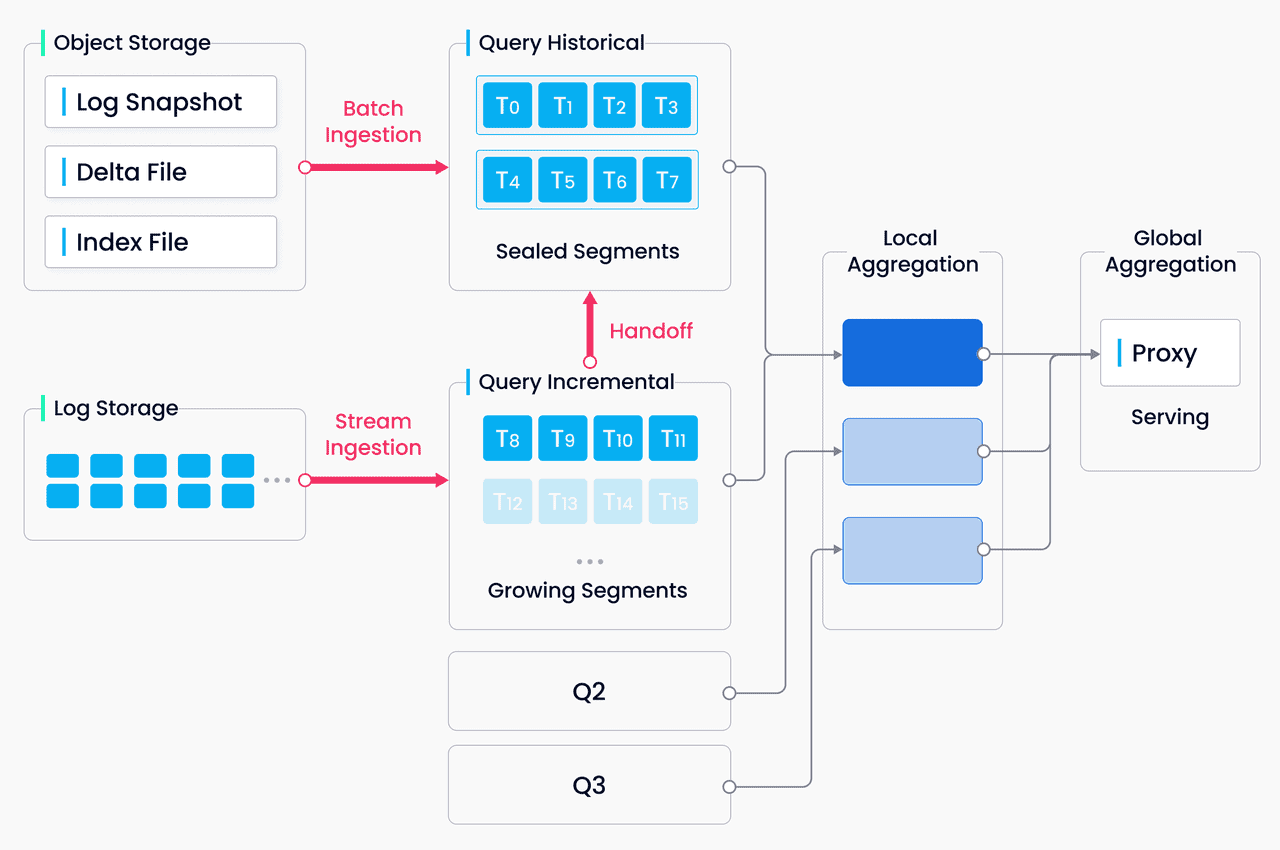
Choisir la bonne base de données vectorielle pour votre entreprise
Que vous construisiez un moteur de recherche sémantique, un système de recommandation ou toute autre application alimentée par l'IA, les bases de données vectorielles constituent la base qui permet d'exploiter tout le potentiel des modèles d'apprentissage automatique. En permettant une recherche rapide par similarité, un filtrage avancé et une intégration transparente avec les frameworks les plus courants, ces bases de données permettent aux développeurs de se concentrer sur la création de solutions innovantes sans se préoccuper des complexités sous-jacentes de la gestion des données vectorielles.
Pour obtenir encore plus de contenu sur l'IA d'entreprise, y compris des infographies, des statistiques, des guides pratiques, des articles et des vidéos, suivez Skim AI sur LinkedIn
Vous êtes un fondateur, un PDG, un investisseur en capital-risque ou un investisseur à la recherche de services de conseil ou de due diligence en matière d'IA ? Obtenez les conseils dont vous avez besoin pour prendre des décisions éclairées concernant la stratégie de votre entreprise en matière de produits d'IA ou d'opportunités d'investissement.
Nous construisons sur mesure Solutions d'IA pour les entreprises soutenues par le capital-risque et le capital-investissement dans les secteurs suivants : Technologie médicale, agrégation de nouvelles/contenu, production de films et de photos, technologie éducative, technologie juridique, Fintech & Cryptocurrency.


