
Répartition des documents de recherche sur l'IA pour ChainPoll : une méthode très efficace pour la détection des hallucinations LLM



Dans cet article, nous allons analyser un important document de recherche qui aborde l'un des défis les plus pressants auxquels sont confrontés les grands modèles de langage (LLM) : les hallucinations. L'article, intitulé "ChainPoll : une méthode très efficace pour la détection des hallucinations LLMprésente une nouvelle approche pour identifier et atténuer ces inexactitudes générées par l'IA.
L'article ChainPoll, rédigé par des chercheurs de Galileo Technologies Inc. présente une nouvelle méthode de détection des hallucinations dans les sorties LLM. Cette méthode, appelée ChainPoll, surpasse les alternatives existantes en termes de précision et d'efficacité. En outre, l'article présente RealHall, un ensemble de données de référence soigneusement sélectionnées et conçues pour évaluer les mesures de détection des hallucinations de manière plus efficace que les références précédentes.
Les hallucinations dans les LLM se réfèrent à des cas où ces modèles d'IA génèrent des textes qui sont factuellement incorrects, absurdes ou sans rapport avec les données d'entrée. Les LLM étant de plus en plus intégrés dans diverses applications, des chatbots aux outils de création de contenu, le risque de propagation d'informations erronées par le biais de ces hallucinations augmente de manière exponentielle. Ce problème pose un défi important à la fiabilité et à la fiabilité du contenu généré par l'IA.
La capacité à détecter avec précision et à atténuer les hallucinations est cruciale pour le déploiement responsable des systèmes d'IA. Cette recherche fournit une méthode plus robuste pour identifier ces erreurs, ce qui peut améliorer la fiabilité du contenu généré par l'IA, renforcer la confiance des utilisateurs dans les applications d'IA et réduire le risque de diffusion de fausses informations par les systèmes d'IA. En s'attaquant au problème de l'hallucination, cette recherche ouvre la voie à des applications d'IA plus fiables et plus dignes de confiance dans divers secteurs.

Contexte et problématique
La détection des hallucinations dans les sorties LLM est une tâche complexe en raison de plusieurs facteurs. Le volume de texte que les LLM peuvent générer, combiné à la nature souvent subtile des hallucinations, les rend difficiles à distinguer des informations exactes. En outre, la nature contextuelle de nombreuses hallucinations et l'absence d'une "vérité de base" complète permettant de vérifier tout le contenu généré compliquent encore le processus de détection.
Avant l'article de ChainPoll, les méthodes existantes de détection des hallucinations présentaient plusieurs limites. Nombre d'entre elles manquaient d'efficacité dans diverses tâches et domaines, tandis que d'autres étaient trop coûteuses en termes de calcul pour des applications en temps réel. Certaines méthodes dépendaient d'architectures de modèles ou de données d'entraînement spécifiques, et la plupart avaient du mal à distinguer les différents types d'hallucinations, tels que les erreurs factuelles ou contextuelles.
En outre, les repères utilisés pour évaluer ces méthodes ne reflètent souvent pas les véritables défis posés par les LLM de pointe dans les applications du monde réel. Beaucoup étaient basés sur des modèles plus anciens et plus faibles ou se concentraient sur des tâches étroites et spécifiques qui ne représentaient pas la gamme complète des capacités et des hallucinations potentielles des LLM.
Pour résoudre ces problèmes, les chercheurs à l'origine de l'article de ChainPoll ont adopté une approche à deux volets :
Développement d'une nouvelle méthode de détection des hallucinations plus efficace (ChainPoll)
Créer une série de tests plus pertinents et plus stimulants (RealHall)
Cette approche globale visait non seulement à améliorer la détection des hallucinations, mais aussi à établir un cadre plus solide pour évaluer et comparer les différentes méthodes de détection.
Principales contributions du document
L'article de ChainPoll apporte trois contributions principales au domaine de la recherche et du développement en matière d'intelligence artificielle, chacune abordant un aspect essentiel du défi que représente la détection des hallucinations.
Tout d'abord, le document présente ChainPollChainPoll est une nouvelle méthode de détection des hallucinations. ChainPoll exploite la puissance des LLM eux-mêmes pour identifier les hallucinations, en utilisant une technique d'incitation soigneusement conçue et une méthode d'agrégation pour améliorer la précision et la fiabilité. Il utilise une chaîne de pensée pour obtenir des explications plus détaillées et systématiques, effectue plusieurs itérations du processus de détection pour augmenter la fiabilité et s'adapte aux scénarios de détection d'hallucinations dans les domaines ouverts et fermés.
Deuxièmement, reconnaissant les limites des critères de référence existants, les auteurs ont développé RealHallune nouvelle série d'ensembles de données de référence. RealHall est conçu pour fournir une évaluation plus réaliste et plus difficile des méthodes de détection des hallucinations. Il comprend quatre ensembles de données soigneusement sélectionnés qui sont difficiles même pour les LLM de pointe, se concentre sur des tâches pertinentes pour les applications LLM du monde réel, et couvre à la fois des scénarios d'hallucinations en domaine ouvert et en domaine fermé.
Enfin, le document présente une comparaison approfondie de ChainPoll avec un large éventail de méthodes existantes de détection des hallucinations. Cette évaluation complète s'appuie sur la nouvelle série de critères de référence RealHall, inclut à la fois des mesures établies et des innovations récentes dans le domaine, et prend en compte des facteurs tels que la précision, l'efficacité et le rapport coût-efficacité. Grâce à cette évaluation, le document démontre la supériorité des performances de ChainPoll pour différentes tâches et différents types d'hallucinations.
En offrant ces trois contributions clés, l'article de ChainPoll ne fait pas seulement progresser l'état de l'art en matière de détection des hallucinations, mais fournit également un cadre plus solide pour la recherche et le développement futurs dans ce domaine critique de la sécurité et de la fiabilité de l'IA.
La méthodologie de ChainPoll à la loupe
À la base, ChainPoll exploite les capacités des grands modèles de langage eux-mêmes pour identifier les hallucinations dans les textes générés par l'IA. Cette approche se distingue par sa simplicité, son efficacité et sa capacité d'adaptation à différents types d'hallucinations.
Comment fonctionne ChainPoll
La méthode ChainPoll repose sur un principe simple mais puissant. Elle utilise un LLM (en particulier, GPT-3.5-turbo dans les expériences de l'article) pour évaluer si un texte donné contient des hallucinations.
Le processus comprend trois étapes clés :
Tout d'abord, le système invite le LLM à évaluer la présence d'hallucinations dans le texte cible, à l'aide d'un outil d'évaluation des hallucinations soigneusement conçu. rapide.
Ensuite, ce processus est répété plusieurs fois, généralement cinq fois, pour garantir la fiabilité.
Enfin, le système calcule un score en divisant le nombre de réponses "oui" (indiquant la présence d'hallucinations) par le nombre total de réponses.
Cette approche permet à ChainPoll d'exploiter les capacités de compréhension linguistique des LLM tout en atténuant les erreurs d'évaluation individuelles grâce à l'agrégation.
Le rôle de l'incitation à la réflexion en chaîne
Une innovation cruciale de ChainPoll est son utilisation de la chaîne de pensée (CoT). Cette technique encourage le LLM à fournir une explication étape par étape de son raisonnement lorsqu'il détermine si un texte contient des hallucinations. Les auteurs ont constaté qu'une invite "CoT détaillée" soigneusement élaborée suscitait systématiquement des explications plus systématiques et plus fiables de la part du modèle.
En incorporant CoT, ChainPoll améliore non seulement la précision de la détection des hallucinations, mais fournit également des informations précieuses sur le processus de prise de décision du modèle. Cette transparence peut s'avérer cruciale pour comprendre pourquoi certains textes sont signalés comme contenant des hallucinations, ce qui pourrait contribuer au développement de LLM plus robustes à l'avenir.
Différencier les hallucinations du domaine ouvert de celles du domaine fermé
L'un des points forts de ChainPoll est sa capacité à traiter à la fois les hallucinations du domaine ouvert et celles du domaine fermé. Les hallucinations du domaine ouvert se réfèrent à de fausses affirmations sur le monde en général, tandis que les hallucinations du domaine fermé impliquent des incohérences avec un texte de référence ou un contexte spécifique.
Pour traiter ces différents types d'hallucinations, les auteurs ont développé deux variantes de ChainPoll : Correction en chaîne pour les hallucinations à domaine ouvert et ChainPoll-Adherence pour les hallucinations à domaine fermé. Ces variantes diffèrent principalement par leur stratégie d'incitation, ce qui permet au système de s'adapter à différents contextes d'évaluation tout en conservant la méthodologie de base de ChainPoll.
La suite RealHall Benchmark
Conscients des limites des tests de référence existants, les auteurs ont également développé RealHall, une nouvelle suite de tests de référence conçue pour fournir une évaluation plus réaliste et plus difficile des méthodes de détection des hallucinations.
Critères de sélection des ensembles de données (défi, réalisme, diversité des tâches)
La création de RealHall a été guidée par trois principes clés :
Défi : Les ensembles de données devraient poser des difficultés significatives même pour les LLM les plus modernes, garantissant que le benchmark reste pertinent à mesure que les modèles s'améliorent.
Le réalisme : Les tâches devraient refléter étroitement les applications réelles des LLM, ce qui rendrait les résultats de l'évaluation comparative plus applicables aux scénarios pratiques.
Diversité des tâches : La suite devrait couvrir une large gamme de capacités LLM, fournissant une évaluation complète des méthodes de détection des hallucinations.
Ces critères ont conduit à la sélection de quatre ensembles de données qui, collectivement, offrent un terrain d'essai solide pour les méthodes de détection des hallucinations.
Aperçu des quatre ensembles de données de RealHall
RealHall comprend deux paires d'ensembles de données, chacune traitant d'un aspect différent de la détection des hallucinations :
RealHall fermé : Cette paire comprend l'ensemble de données COVID-QA avec extraction et l'ensemble de données DROP. Ceux-ci se concentrent sur les hallucinations du domaine fermé, testant la capacité d'un modèle à rester cohérent avec les textes de référence fournis.
RealHall Open : Cette paire se compose de l'ensemble de données Open Assistant prompts et de l'ensemble de données TriviaQA. Ils ciblent les hallucinations du domaine ouvert et évaluent la capacité d'un modèle à éviter de faire de fausses affirmations sur le monde.
Chaque jeu de données de RealHall a été choisi pour ses défis uniques et sa pertinence pour les applications LLM du monde réel. Par exemple, l'ensemble de données COVID-QA reproduit des scénarios de génération augmentée de recherche, tandis que DROP teste les capacités de raisonnement discret.
Comment RealHall répond aux limites des critères de référence précédents
RealHall représente une amélioration significative par rapport aux benchmarks précédents, et ce à plusieurs égards. Tout d'abord, il utilise des LLM plus récents et plus puissants pour générer des réponses, ce qui garantit que les hallucinations détectées sont représentatives de celles produites par les modèles de pointe actuels. Cela permet de résoudre un problème commun aux anciens bancs d'essai qui utilisaient des modèles obsolètes produisant des hallucinations facilement détectables.
Deuxièmement, l'accent mis par RealHall sur la diversité des tâches et le réalisme signifie qu'il fournit une évaluation plus complète et plus pertinente sur le plan pratique des méthodes de détection des hallucinations. Cela contraste avec de nombreux benchmarks antérieurs qui se concentrent sur des tâches étroites et spécifiques ou sur des scénarios artificiels.
Enfin, en incluant à la fois des tâches en domaine ouvert et en domaine fermé, RealHall permet une évaluation plus nuancée des méthodes de détection des hallucinations. Ceci est particulièrement important car de nombreuses applications LLM réelles nécessitent les deux types de détection d'hallucinations.
Grâce à ces améliorations, RealHall constitue une référence plus rigoureuse et plus pertinente pour l'évaluation des méthodes de détection des hallucinations, établissant ainsi une nouvelle norme dans ce domaine.
Résultats expérimentaux et analyse
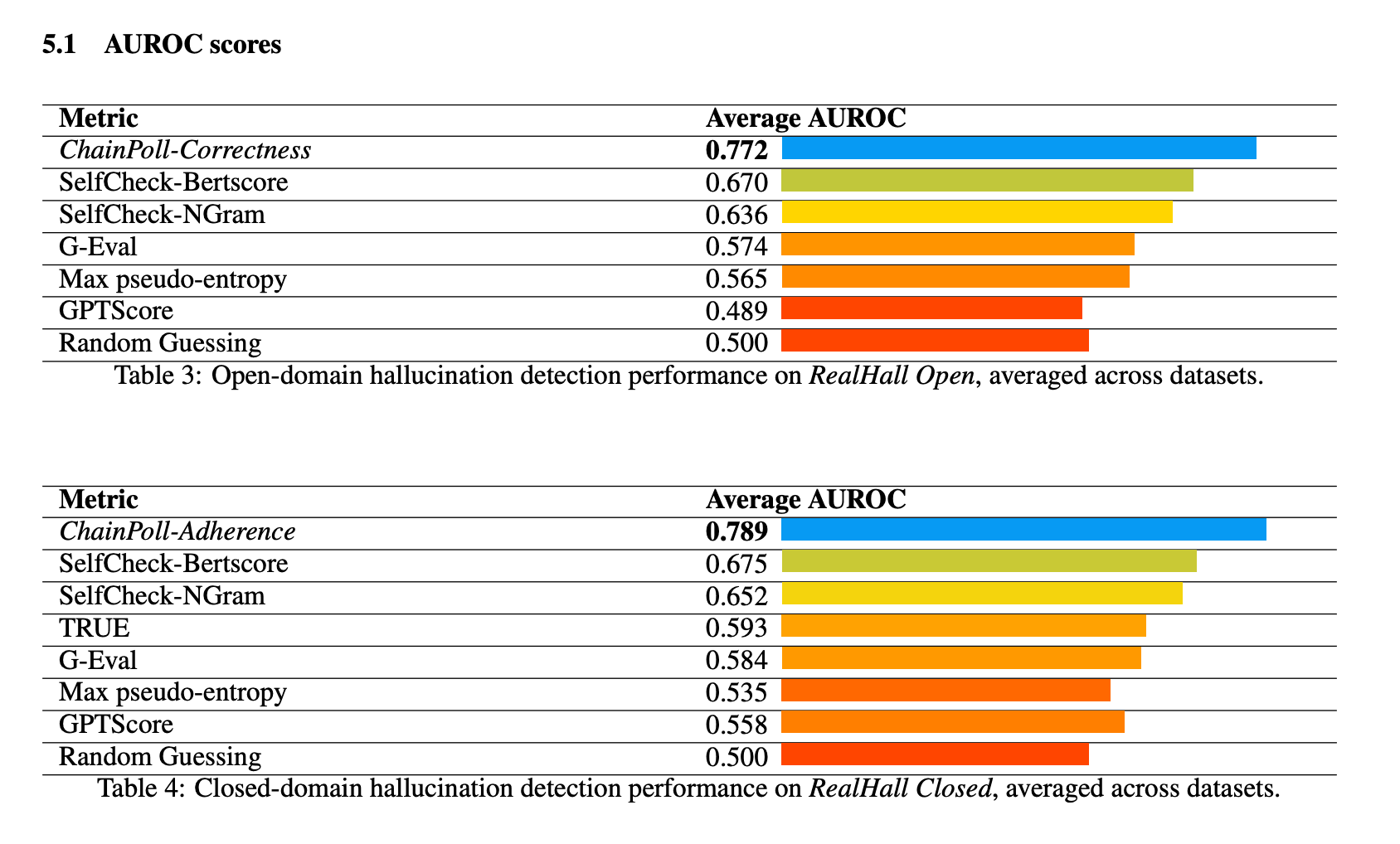
ChainPoll a démontré une performance supérieure dans tous les benchmarks de la suite RealHall. Il a obtenu un AUROC (Area Under the Receiver Operating Characteristic curve) global de 0,781, surpassant nettement la méthode suivante, SelfCheck-BertScore, qui a obtenu un score de 0,673. Cette amélioration substantielle par rapport à 10% représente un saut significatif dans la capacité de détection des hallucinations.
Parmi les autres méthodes testées, citons SelfCheck-NGram, G-Eval et GPTScore, qui ont toutes obtenu des résultats nettement inférieurs à ceux de ChainPoll. Il est intéressant de noter que certaines méthodes qui s'étaient révélées prometteuses dans des études antérieures, telles que GPTScore, ont obtenu des résultats médiocres sur les benchmarks plus difficiles et plus diversifiés de RealHall.

Les performances de ChainPoll ont été systématiquement bonnes dans les tâches de détection d'hallucinations en domaine ouvert et en domaine fermé. Pour les tâches en domaine ouvert (en utilisant ChainPoll-Correctness), il a obtenu un AUROC moyen de 0,772, tandis que pour les tâches en domaine fermé (en utilisant ChainPoll-Adherence), il a obtenu un score de 0,789.
La méthode s'est révélée particulièrement efficace dans des ensembles de données difficiles comme DROP, qui nécessite un raisonnement discret.
Au-delà de sa précision supérieure, ChainPoll s'est également avéré plus efficace et plus rentable que de nombreuses méthodes concurrentes. Il atteint ses résultats en utilisant seulement 1/4 de l'inférence LLM que la méthode suivante, SelfCheck-BertScore. En outre, ChainPoll ne nécessite pas l'utilisation de modèles supplémentaires tels que BERT, ce qui réduit encore la charge de calcul.
Cette efficacité est cruciale pour les applications pratiques, car elle permet de détecter les hallucinations en temps réel dans les environnements de production, sans coûts ou temps de latence prohibitifs.
Implications et travaux futurs
ChainPoll représente une avancée significative dans le domaine de la détection des hallucinations pour les LLM. Son succès démontre le potentiel d'utilisation des LLM en tant qu'outils pour améliorer la sécurité et la fiabilité de l'IA. Cette approche ouvre de nouvelles voies pour la recherche sur les systèmes d'IA qui s'améliorent et se vérifient eux-mêmes.
L'efficacité et la précision de ChainPoll le rendent apte à être intégré dans un large éventail d'applications d'IA. Il pourrait être utilisé pour renforcer la fiabilité des chatbots, améliorer l'exactitude du contenu généré par l'IA dans des domaines tels que le journalisme ou la rédaction technique, et accroître la fiabilité des assistants d'IA dans des domaines critiques tels que les soins de santé ou la finance.
Bien que ChainPoll ait obtenu des résultats impressionnants, il est encore possible de poursuivre les recherches et d'apporter des améliorations. Les travaux futurs pourraient porter sur les points suivants
Adapter ChainPoll pour qu'il fonctionne avec un plus grand nombre de LLM et de tâches linguistiques
Recherche de moyens d'améliorer encore l'efficacité sans sacrifier la précision
Explorer le potentiel de ChainPoll pour d'autres types de contenus générés par l'IA que le texte
Développer des méthodes permettant non seulement de détecter, mais aussi de corriger ou de prévenir les hallucinations en temps réel
L'article ChainPoll apporte des contributions significatives au domaine de la sécurité et de la fiabilité de l'IA grâce à l'introduction d'une nouvelle méthode de détection des hallucinations et d'un critère d'évaluation plus robuste. En démontrant une performance supérieure dans la détection des hallucinations dans les domaines ouverts et fermés, ChainPoll ouvre la voie à des systèmes d'IA plus fiables. Les LLM continuant à jouer un rôle de plus en plus important dans diverses applications, la capacité à détecter avec précision et à atténuer les hallucinations devient cruciale. Cette recherche ne fait pas seulement progresser nos capacités actuelles, mais ouvre également de nouvelles voies pour l'exploration et le développement futurs dans le domaine critique de la détection des hallucinations par l'IA.


