
10 stratégies éprouvées pour réduire les coûts de votre LLM - AI&YOU #65



La statistique de la semaine : L'utilisation de LLM plus petits comme GPT-J dans une cascade peut réduire le coût global de 80% tout en améliorant la précision de 1,5% par rapport à GPT-4. (Dataiku)
Alors que les entreprises s'appuient de plus en plus sur de grands modèles de langage (LLM) pour diverses applications, les coûts opérationnels associés au déploiement et à la maintenance de ces modèles peuvent rapidement devenir incontrôlables en l'absence d'une supervision et de stratégies d'optimisation adéquates.
Meta a également publié Llama 3.1, qui a fait couler beaucoup d'encre ces derniers temps parce qu'il s'agit du LLM open-source le plus avancé à ce jour.
Dans l'édition de cette semaine d'AI&YOU, nous explorons les perspectives de trois blogs que nous avons publiés sur ces sujets :
Comprendre les structures de tarification du LLM : Entrées, sorties et fenêtres contextuelles
Le lama de Meta 3.1 : Repousser les limites de l'IA Open-Source
10 stratégies éprouvées pour réduire les coûts de votre LLM - AI&YOU #65
Cet article de blog explore dix stratégies éprouvées pour aider votre entreprise à gérer efficacement les coûts des LLM, vous permettant ainsi d'exploiter tout le potentiel de ces modèles tout en maintenant la rentabilité et le contrôle des dépenses.
1. Sélection d'un modèle intelligent
Optimisez vos coûts LLM en adaptant soigneusement la complexité du modèle aux exigences de la tâche. Toutes les applications n'ont pas besoin du modèle le plus récent et le plus grand. Pour les tâches plus simples telles que la classification de base ou les questions-réponses directes, envisagez d'utiliser des modèles pré-entraînés plus petits et plus efficaces. Cette approche permet de réaliser des économies substantielles sans compromettre les performances.
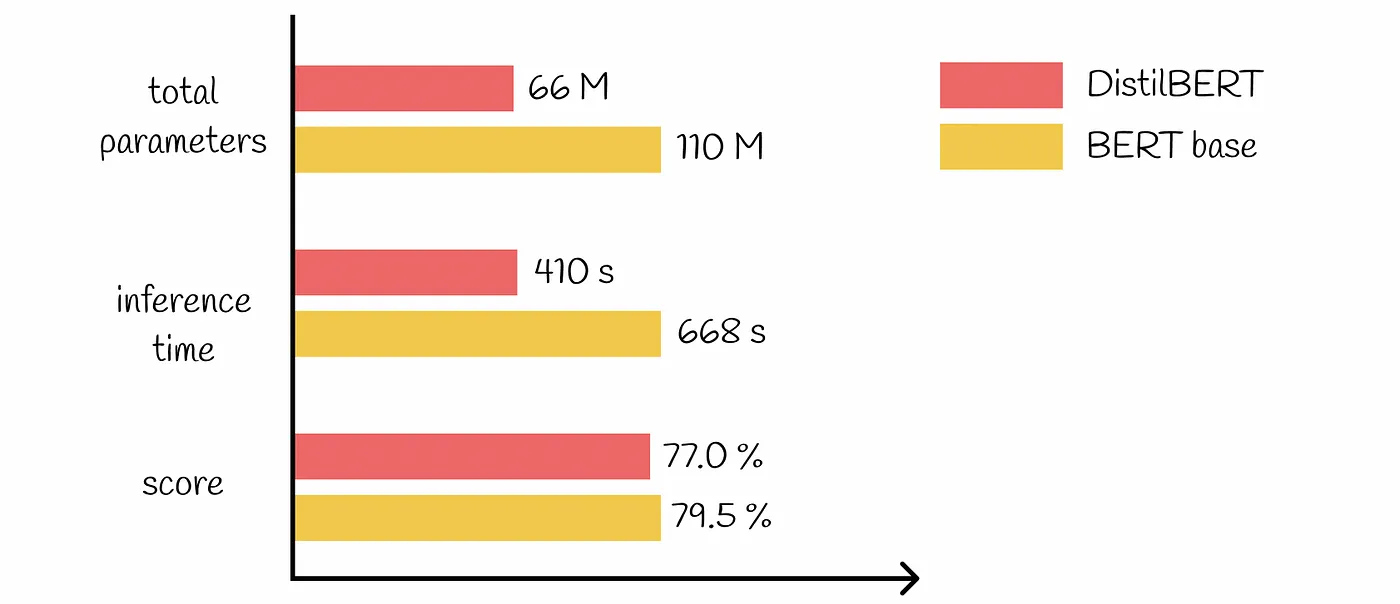
Par exemple, l'utilisation de DistilBERT pour l'analyse des sentiments au lieu de BERT-Large peut réduire de manière significative la charge de calcul et les dépenses associées tout en maintenant une grande précision pour la tâche spécifique à accomplir.
2. Mettre en œuvre un suivi robuste de l'utilisation
Obtenez une vue d'ensemble de votre Utilisation du LLM en mettant en œuvre des mécanismes de suivi à plusieurs niveaux. Surveillez l'utilisation des jetons, les temps de réponse et les appels de modèle au niveau de la conversation, de l'utilisateur et de l'entreprise. Exploitez les tableaux de bord analytiques intégrés des fournisseurs de LLM ou mettez en œuvre des solutions de suivi personnalisées intégrées à votre infrastructure.
Cette vision granulaire vous permet d'identifier les inefficacités, telles que l'utilisation excessive par les départements de modèles coûteux pour des tâches simples ou des schémas de requêtes redondantes. En analysant ces données, vous pouvez découvrir des stratégies précieuses de réduction des coûts et optimiser votre consommation globale de LLM.
3. Optimiser l'ingénierie rapide
Affinez vos techniques d'ingénierie des invites pour réduire de manière significative l'utilisation des jetons et améliorer l'efficacité du LLM. Rédigez des instructions claires et concises dans vos invites, mettez en œuvre une gestion des erreurs pour résoudre les problèmes courants sans requêtes supplémentaires et utilisez des modèles d'invites éprouvés pour des tâches spécifiques. Structurez efficacement vos invites en évitant les contextes inutiles, en utilisant des techniques de formatage telles que les puces et en exploitant les fonctions intégrées pour contrôler la longueur de la sortie.
Ces optimisations peuvent réduire considérablement la consommation de jetons et les coûts associés tout en maintenant, voire en améliorant, la qualité de vos résultats LLM.
4. Tirer parti du réglage fin pour la spécialisation
Utilisez la puissance du réglage fin pour créer des modèles plus petits et plus efficaces, adaptés à vos besoins spécifiques. Bien qu'elle nécessite un investissement initial, cette approche peut permettre de réaliser d'importantes économies à long terme. Les modèles affinés nécessitent souvent moins de jetons pour obtenir des résultats égaux ou meilleurs, ce qui réduit les coûts d'inférence et la nécessité d'effectuer de nouvelles tentatives ou des corrections.
Commencez par un modèle pré-entraîné plus petit, utilisez des données de haute qualité spécifiques au domaine pour l'affiner et évaluez régulièrement les performances et le rapport coût-efficacité. Cette optimisation continue garantit que vos modèles continuent à apporter de la valeur tout en maîtrisant les coûts opérationnels.
5. Explorer les options gratuites ou peu coûteuses
Exploiter les options de LLM gratuites ou peu coûteuses, en particulier pendant les phases de développement et de test, afin de réduire considérablement les dépenses sans compromettre la qualité. Ces solutions sont particulièrement intéressantes pour le prototypage, la formation des développeurs et les services non critiques ou internes.
Toutefois, il convient d'évaluer soigneusement les compromis, en tenant compte de la confidentialité des données, des implications en matière de sécurité et des limitations potentielles en termes de capacités ou de personnalisation. Évaluez l'évolutivité à long terme et les voies de migration pour vous assurer que vos mesures de réduction des coûts s'alignent sur les plans de croissance futurs et ne deviennent pas des obstacles en cours de route.
6. Optimiser la gestion des fenêtres contextuelles
Gérer efficacement les fenêtres contextuelles pour contrôler les coûts tout en maintenant la qualité des résultats. Mettre en œuvre un dimensionnement dynamique du contexte en fonction de la complexité de la tâche, utiliser des techniques de résumé pour condenser les informations pertinentes et employer des approches de fenêtres coulissantes pour les longs documents ou les conversations. Analyser régulièrement la relation entre la taille du contexte et la qualité du résultat, en ajustant les fenêtres en fonction des exigences spécifiques de la tâche.
Envisagez une approche à plusieurs niveaux, en utilisant des contextes plus larges uniquement lorsque cela est nécessaire. Cette gestion stratégique des fenêtres contextuelles peut réduire considérablement l'utilisation des jetons et les coûts associés sans sacrifier les capacités de compréhension de vos applications LLM.
7. Mettre en œuvre des systèmes multi-agents
Améliorer l'efficacité et la rentabilité en mettant en œuvre des architectures LLM multi-agents. Cette approche implique la collaboration de plusieurs agents d'intelligence artificielle pour résoudre des problèmes complexes, ce qui permet d'optimiser l'allocation des ressources et de réduire la dépendance à l'égard de modèles coûteux et à grande échelle.
Les systèmes multi-agents permettent un déploiement ciblé des modèles, améliorant l'efficacité globale du système et les temps de réponse tout en réduisant l'utilisation des jetons. Pour maintenir le rapport coût-efficacité, il convient de mettre en œuvre des mécanismes de débogage robustes, notamment en enregistrant les communications entre agents et en analysant les schémas d'utilisation des jetons.
En optimisant la répartition du travail entre les agents, vous pouvez minimiser la consommation inutile de jetons et maximiser les avantages de la gestion des tâches distribuées.
8. Utiliser les outils de formatage des sorties
Exploiter les outils de formatage des sorties pour garantir une utilisation efficace des jetons et minimiser les besoins de traitement supplémentaires. Mettre en œuvre des sorties de fonction forcées pour spécifier des formats de réponse exacts, en réduisant la variabilité et le gaspillage de jetons. Cette approche réduit la probabilité de sorties mal formées et la nécessité de clarifier les appels à l'API.
Pensez à utiliser les sorties JSON pour leur représentation compacte des données structurées, leur analyse facile et leur utilisation réduite de jetons par rapport aux réponses en langage naturel. En rationalisant vos flux de travail LLM à l'aide de ces outils de formatage, vous pouvez optimiser de manière significative l'utilisation des jetons et réduire les coûts opérationnels tout en conservant des résultats de haute qualité.
9. Intégrer des outils non-LLM
Complétez vos applications LLM avec des outils non LLM pour optimiser les coûts et l'efficacité. Incorporez des scripts Python ou des approches de programmation traditionnelles pour les tâches qui ne requièrent pas toutes les capacités d'un LLM, telles que le traitement de données simples ou la prise de décision basée sur des règles.
Lors de la conception des flux de travail, il convient d'équilibrer soigneusement le LLM et les outils conventionnels en fonction de la complexité de la tâche, de la précision requise et des économies potentielles. Effectuez des analyses approfondies des coûts et des avantages en tenant compte de facteurs tels que les coûts de développement, le temps de traitement, la précision et l'évolutivité à long terme. Cette approche hybride donne souvent les meilleurs résultats en termes de performance et de rentabilité.
10. Audit et optimisation réguliers
Mettez en place un système solide d'audit et d'optimisation réguliers pour assurer une gestion continue des coûts du LLM. Surveillez et analysez constamment votre utilisation du LLM pour identifier les inefficacités, telles que les requêtes redondantes ou les fenêtres contextuelles excessives. Utilisez des outils de suivi et d'analyse pour affiner vos stratégies LLM et éliminer la consommation inutile de jetons.
Favorisez une culture de prise en compte des coûts au sein de votre organisation, en encourageant les équipes à examiner activement les implications financières de leur utilisation du LLM et à rechercher des possibilités d'optimisation. En faisant de la rentabilité une responsabilité partagée, vous pouvez maximiser la valeur de vos investissements en IA tout en maîtrisant les dépenses à long terme.
Comprendre les structures de tarification du LLM : Entrées, sorties et fenêtres contextuelles
Pour les stratégies d'IA des entreprises, il est essentiel de comprendre les structures de tarification des LLM pour une gestion efficace des coûts. Les coûts opérationnels associés aux LLM peuvent rapidement augmenter en l'absence d'une surveillance adéquate, ce qui peut entraîner des hausses de coûts inattendues susceptibles de faire dérailler les budgets et d'entraver l'adoption à grande échelle.
La tarification du LLM s'articule généralement autour de trois éléments principaux : les jetons d'entrée, les jetons de sortie et les fenêtres contextuelles. Chacun de ces éléments joue un rôle important dans la détermination du coût global de l'utilisation des LLM dans vos applications.
Jetons de saisie : Ce qu'ils sont et comment ils sont facturés
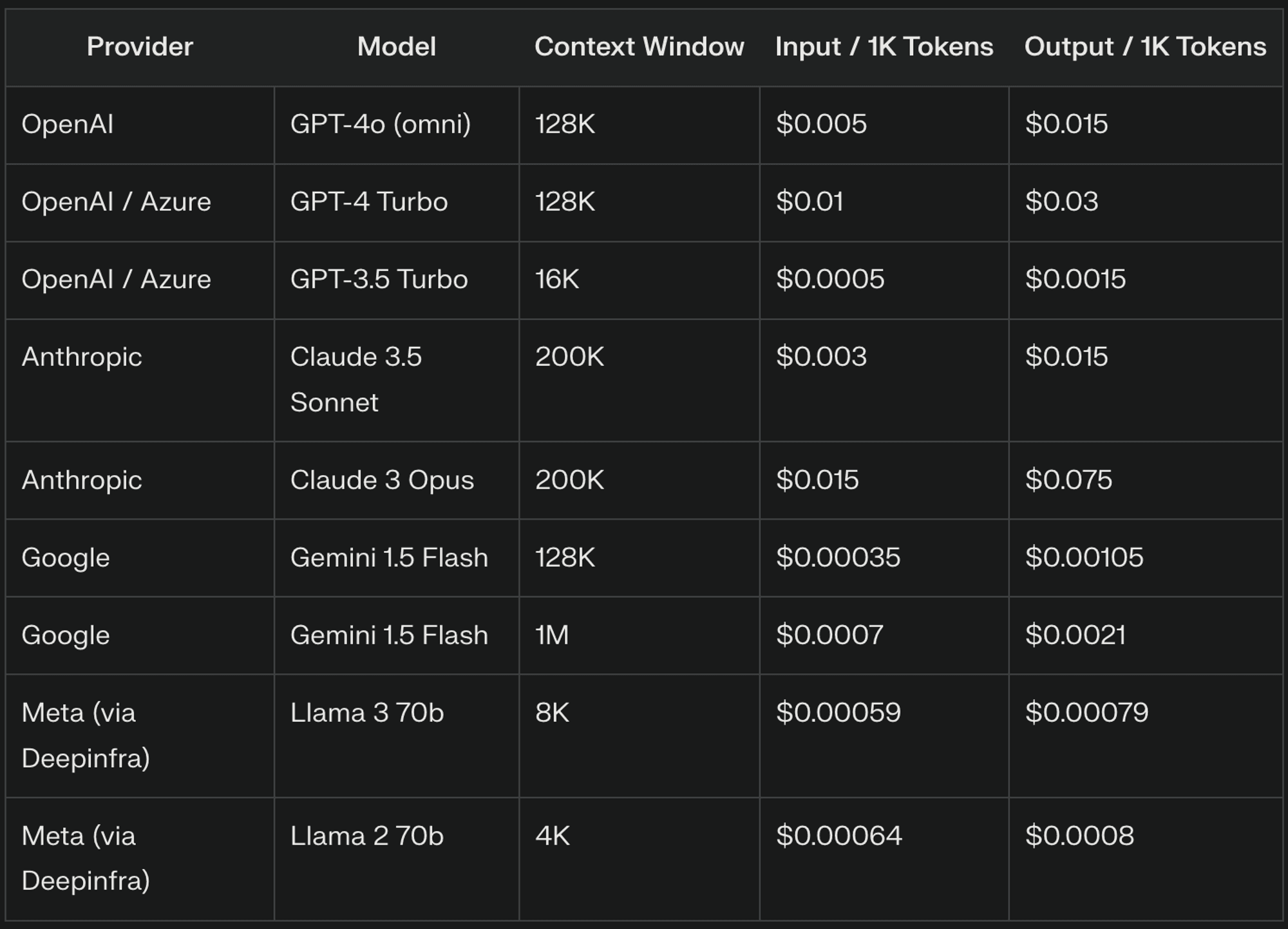
Les jetons d'entrée sont les unités fondamentales du texte traité par les LLM, correspondant généralement à des parties de mots. Par exemple, "The quick brown fox" peut être symbolisé par ["The", "quick", "bro", "wn", "fox"], ce qui donne 5 jetons d'entrée. Les fournisseurs de LLM facturent généralement les jetons d'entrée sur la base d'un taux par millier de jetons, les prix variant considérablement d'un fournisseur à l'autre et d'une version à l'autre du modèle.
Pour optimiser l'utilisation des jetons d'entrée et réduire les coûts, envisagez les stratégies suivantes :
Rédiger des messages-guides concis : Privilégiez les instructions claires et directes.
Utiliser un encodage efficace : Choisissez des méthodes qui représentent le texte avec moins de jetons.
Mettre en place des modèles d'invite : Développer des structures optimisées pour les tâches courantes.
Exploiter les techniques de compression : Réduire la taille des données sans perdre d'informations essentielles.
Jetons de sortie : Comprendre les coûts
Les jetons de sortie représentent le texte généré par le LLM en réponse à votre entrée. Le nombre de jetons de sortie peut varier considérablement en fonction de la tâche et de la configuration du modèle. Les fournisseurs de LLM fixent souvent un prix plus élevé pour les jetons de sortie que pour les jetons d'entrée en raison de la complexité informatique de la génération de texte.
Optimiser l'utilisation des jetons de sortie et contrôler les coûts :
Définissez des limites claires de longueur de sortie dans vos invites ou appels API.
Utilisez l'"apprentissage à quelques coups" pour guider le modèle vers des réponses concises.
Mettre en œuvre un post-traitement pour éliminer le contenu inutile.
Envisagez de mettre en cache les informations fréquemment demandées.
Utiliser les outils de formatage des résultats pour garantir une utilisation efficace des jetons.
Fenêtres contextuelles : Le facteur de coût caché
Les fenêtres contextuelles déterminent la quantité de texte précédent que le LLM prend en compte lors de la génération d'une réponse, ce qui est crucial pour maintenir la cohérence et faire référence à des informations antérieures. Des fenêtres contextuelles plus grandes augmentent le nombre de jetons d'entrée traités, ce qui entraîne des coûts plus élevés. Par exemple, une fenêtre contextuelle de 8 000 tokens peut être facturée pour 7 000 tokens dans une conversation, tandis qu'une fenêtre de 4 000 tokens peut être facturée pour 3 000 tokens seulement.
Pour optimiser l'utilisation de la fenêtre contextuelle :
Mettre en œuvre un dimensionnement dynamique du contexte en fonction des exigences de la tâche.
Utiliser des techniques de synthèse pour condenser les informations pertinentes.
Utiliser des fenêtres coulissantes pour les documents longs.
Envisager des modèles plus petits et spécialisés pour les tâches nécessitant un contexte limité.
Analyser régulièrement la relation entre la taille du contexte et la qualité des résultats.
En gérant soigneusement ces éléments des structures de tarification du LLM, les entreprises peuvent réduire leurs coûts opérationnels tout en maintenant la qualité de leurs applications d'IA.
Le bilan
Comprendre les structures de prix des LLM est essentiel pour une gestion efficace des coûts dans les applications d'IA d'entreprise. En saisissant les nuances des jetons d'entrée, des jetons de sortie et des fenêtres contextuelles, les entreprises peuvent prendre des décisions éclairées sur la sélection des modèles et les schémas d'utilisation. La mise en œuvre de techniques stratégiques de gestion des coûts, telles que l'optimisation de l'utilisation des jetons et l'exploitation de la mise en cache, peut permettre de réaliser des économies significatives.
Le lama de Meta 3.1 : Repousser les limites de l'IA Open-Source
Dans une grande nouvelle récente, Meta a annoncé Llama 3.1La nouvelle version de l'IA est le modèle de grand langage à source ouverte le plus avancé à ce jour. Cette version marque une étape importante dans la démocratisation de la technologie de l'IA, en comblant potentiellement le fossé entre les modèles open-source et les modèles propriétaires.
Llama 3.1 s'appuie sur ses prédécesseurs avec plusieurs avancées clés :
Augmentation de la taille du modèle : L'introduction du modèle de paramètres 405B repousse les limites de ce qui est possible en matière d'IA open-source.
Extension de la durée du contexte : De 4K tokens dans Llama 2 à 128K dans Llama 3.1, permettant une compréhension plus complexe et plus nuancée des textes plus longs.
Capacités multilingues : La prise en charge élargie des langues permet des applications plus diversifiées dans différentes régions et différents cas d'utilisation.
Amélioration du raisonnement et des tâches spécialisées : Amélioration des performances dans des domaines tels que le raisonnement mathématique et la génération de code.
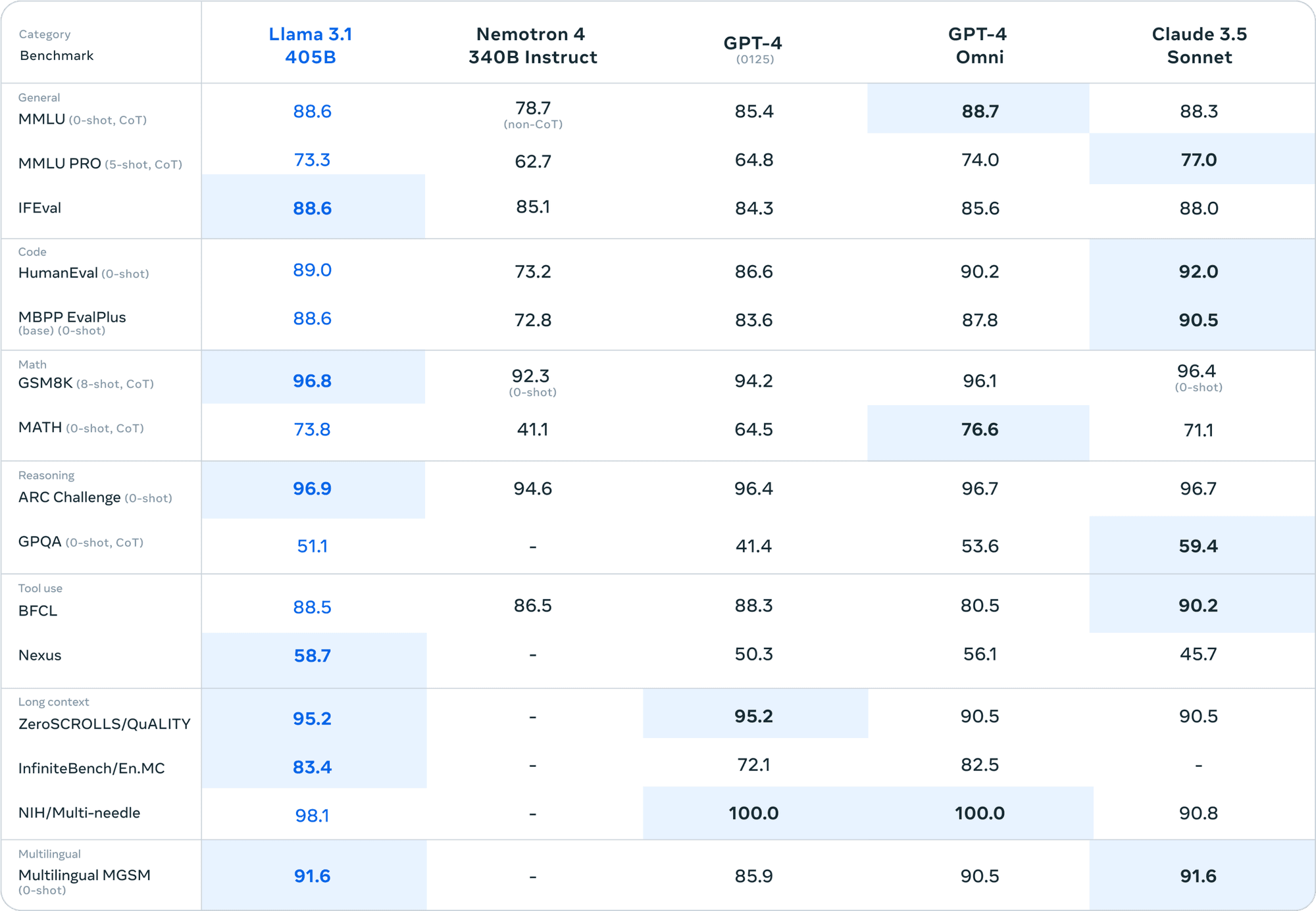
Comparée à des modèles à code source fermé tels que GPT-4 et Claude 3.5 Sonnet, la Llama 3.1 405B tient son rang dans divers benchmarks. Ce niveau de performance dans un modèle à code source ouvert est sans précédent.
Spécifications techniques de Llama 3.1
En ce qui concerne les détails techniques, Llama 3.1 offre une gamme de tailles de modèles pour répondre à différents besoins et ressources informatiques :
Modèle de paramètres 8B : Convient aux applications légères et aux appareils périphériques.
Modèle de paramètres 70B : Un équilibre entre les exigences en matière de performances et de ressources.
405B modèle de paramètres : Le modèle phare, qui repousse les limites des capacités d'IA en source ouverte.
La méthodologie d'apprentissage pour Llama 3.1 a impliqué un énorme ensemble de données de plus de 15 billions de jetons, ce qui est nettement plus important que ses prédécesseurs.
Sur le plan architectural, Llama 3.1 conserve un modèle de transformateur de décodeur uniquement, privilégiant la stabilité de l'apprentissage à des approches plus expérimentales telles que le mélange d'experts.
Cependant, Meta a mis en œuvre plusieurs optimisations pour permettre une formation et une inférence efficaces à cette échelle sans précédent :
Infrastructure de formation évolutive : Utilisation de plus de 16 000 GPU H100 pour entraîner le modèle 405B.
Procédure itérative de post-entraînement : L'utilisation de la mise au point supervisée et de l'optimisation des préférences directes pour améliorer les capacités spécifiques.
Techniques de quantification : Réduction du modèle de 16 bits à 8 bits pour une inférence plus efficace, permettant un déploiement sur un seul nœud de serveur.
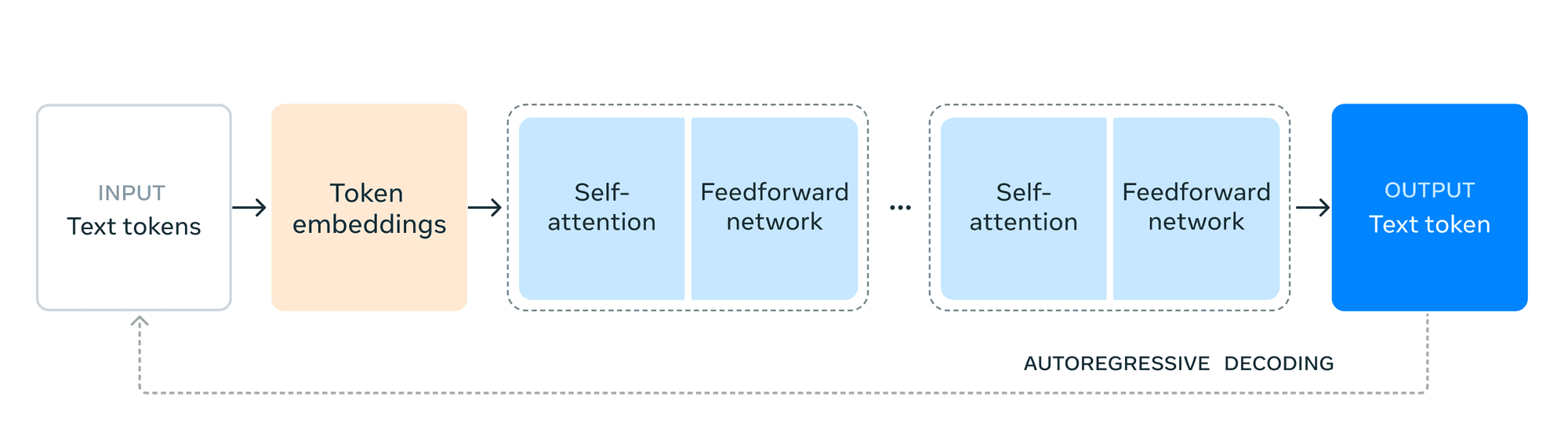
Capacités de rupture
Llama 3.1 présente plusieurs fonctionnalités révolutionnaires qui le distinguent dans le paysage de l'IA :
Contexte élargi Longueur : Le passage à une fenêtre contextuelle de 128 Ko change la donne. Cette capacité élargie permet au Llama 3.1 de traiter et de comprendre des morceaux de texte beaucoup plus longs :
Support multilingue : La prise en charge de huit langues par Llama 3.1 élargit considérablement son champ d'application à l'échelle mondiale.
Raisonnement avancé et utilisation d'outils : Le modèle démontre des capacités de raisonnement sophistiquées et l'aptitude à utiliser efficacement des outils externes.
Génération de code et prouesses mathématiques : Le lama 3.1 présente des capacités remarquables dans les domaines techniques :
Générer un code fonctionnel de haute qualité dans plusieurs langages de programmation
Résoudre des problèmes mathématiques complexes avec précision
Aide à la conception et à l'optimisation des algorithmes
Les promesses et le potentiel de Llama 3.1
La sortie de Llama 3.1 de Meta marque un tournant dans le paysage de l'IA, en démocratisant l'accès à des capacités d'IA d'avant-garde. En proposant un modèle à 405 paramètres avec des performances de pointe, un support multilingue et une longueur de contexte étendue, le tout dans un cadre open-source, Meta a établi un nouveau standard pour une IA accessible et puissante. Cette initiative remet non seulement en question la domination des modèles à source fermée, mais ouvre également la voie à une innovation et à une collaboration sans précédent dans la communauté de l'IA.
Merci d'avoir pris le temps de lire AI & YOU !
Pour obtenir encore plus de contenu sur l'IA d'entreprise, y compris des infographies, des statistiques, des guides pratiques, des articles et des vidéos, suivez Skim AI sur LinkedIn
Vous êtes un fondateur, un PDG, un investisseur en capital-risque ou un investisseur à la recherche de services de conseil en IA, de développement d'IA fractionnée ou de due diligence ? Obtenez les conseils dont vous avez besoin pour prendre des décisions éclairées sur la stratégie des produits d'IA de votre entreprise et les opportunités d'investissement.
Nous construisons des solutions d'IA personnalisées pour les entreprises financées par le capital-risque et le capital-investissement dans les secteurs suivants : Technologie médicale, agrégation de nouvelles/contenu, production de films et de photos, technologie éducative, technologie juridique, Fintech & Cryptocurrency.


