
¿Qué es el aprendizaje profundo?



¿Qué es el aprendizaje profundo?
¿Qué es el aprendizaje profundo? El aprendizaje profundo (AD) es un subconjunto del aprendizaje automático (MA) que se centra principalmente en imitar la capacidad del cerebro humano para aprender y procesar información. En el mundo de la inteligencia artificial (IA), en rápida evolución, el aprendizaje profundo se ha convertido en una tecnología revolucionaria que está influyendo en prácticamente todos los campos, desde la sanidad a la...
Para lograr esta capacidad de aprender y procesar información, el aprendizaje profundo se basa en una compleja red de neuronas interconectadas llamadas redes neuronales artificiales (RNA). Aprovechando la potencia de las RNA y su capacidad para adaptarse y mejorar automáticamente con el tiempo, los algoritmos de aprendizaje profundo pueden descubrir patrones intrincados, extraer ideas significativas y hacer predicciones con una precisión notable.
*Antes de leer este blog sobre aprendizaje profundo, asegúrese de consultar nuestra explicación sobre IA frente a ML.
Los pilares del aprendizaje profundo
La base del aprendizaje profundo es el concepto de RNA, inspirado en la estructura y el funcionamiento del cerebro humano. Las RNA constan de varias capas de nodos o neuronas interconectadas, en las que cada neurona procesa la información y la transmite a la capa siguiente. Estas capas pueden aprender y adaptarse ajustando los pesos de las conexiones entre las neuronas.
En una RNA hay neuronas artificiales, cada una de las cuales recibe información de otra antes de procesarla y enviarla a las neuronas conectadas. La fuerza de estas conexiones entre las neuronas se conoce como pesos, y estos pesos determinan la importancia de cada entrada en el cálculo global.
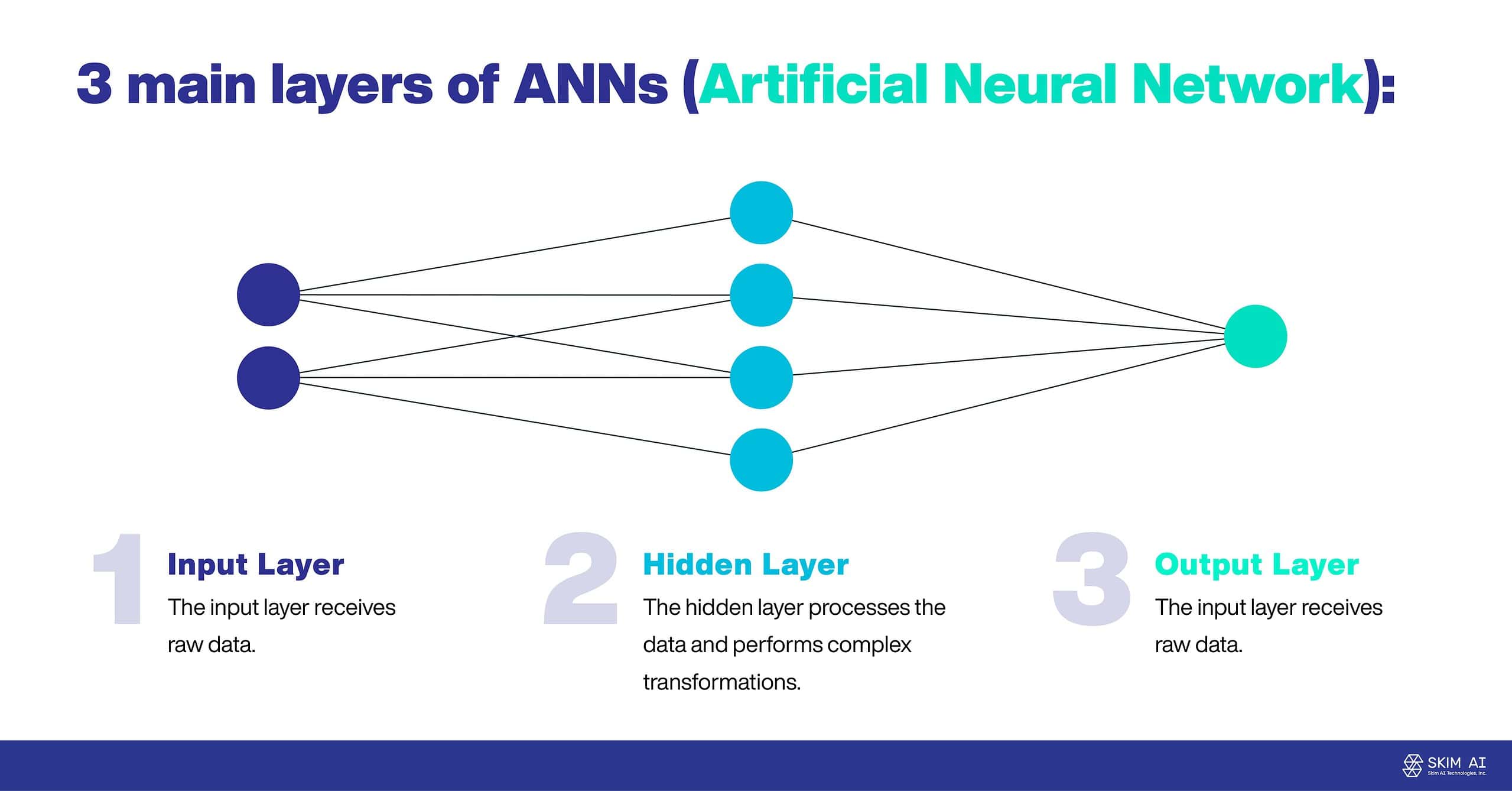
Las RNA suelen constar de tres capas principales:
Capa de entrada: La capa de entrada recibe datos sin procesar.
Capa oculta: La capa oculta procesa los datos y realiza transformaciones complejas.
Capa de salida: La capa de salida produce el resultado final.
Otro componente importante de las RNA son las funciones de activación, que determinan la salida de cada neurona en función de la entrada recibida. Estas funciones introducen la no linealidad en la red, lo que le permite aprender patrones complejos y realizar cálculos intrincados.
El aprendizaje profundo se basa en el proceso de aprendizaje, en el que la red ajusta sus pesos para minimizar el error entre sus predicciones y los resultados. Este proceso de aprendizaje suele implicar el uso de una función de pérdida, que cuantifica la diferencia entre la salida de la red y los valores reales.
Los distintos tipos de arquitecturas de aprendizaje
Dicho todo esto, el aprendizaje profundo no sigue una única arquitectura de aprendizaje. Hay algunos tipos principales de arquitecturas que se utilizan para una amplia gama de problemas. Dos de las más comunes son las redes neuronales convolucionales (CNN) y las redes neuronales recurrentes (RNN). Sin embargo, existen otras, como LSTM, GRU y autocodificadores.
Redes neuronales convolucionales (CNN)
Las CNN desempeñan un papel fundamental en las tareas de visión por ordenador y reconocimiento de imágenes. Antes de la aparición de las CNN, estas tareas requerían técnicas de extracción de características laboriosas y lentas para identificar objetos en las imágenes. En el contexto del reconocimiento de imágenes, la función principal de una CNN es transformar las imágenes a un formato más manejable, conservando al mismo tiempo las características esenciales para realizar predicciones precisas.
Las CNN suelen superar a otras redes neuronales por su excepcional rendimiento con entradas de imágenes, señales de audio o voz.
Emplean tres tipos principales de capas para realizar sus tareas:
Capa de convolución: Identifica las características dentro de los píxeles.
Capa de agrupamiento: Resume las características para su posterior procesamiento.
Capa de conexión total (FC): Utiliza las características adquiridas para la predicción.
La capa convolucional es el componente más fundamental de una CNN, donde se produce la mayor parte del cálculo. Esta capa consta de datos de entrada, un filtro y un mapa de características. Las capas convolucionales realizan una operación de convolución en la entrada antes de enviar el resultado a la capa de agrupación.
En una tarea de reconocimiento de imágenes, esta convolución condensa todos los píxeles de su campo receptivo en un único valor. En términos más sencillos, aplicar una convolución a una imagen reduce su tamaño y combina toda la información dentro del campo en un único píxel. Las características básicas, como los bordes horizontales y diagonales, se extraen en la capa convolucional. La salida generada por la capa convolucional se denomina mapa de características.
El objetivo principal de la capa de agrupación es reducir el tamaño del mapa de características, disminuyendo así el cálculo y las conexiones entre capas.
La tercera capa de una CNN es la capa FC, que conecta neuronas entre dos capas distintas. A menudo situada antes de la capa de salida, las imágenes de entrada de las capas anteriores se aplanan. La imagen aplanada suele pasar por capas FC adicionales, donde funciones matemáticas inician el proceso de clasificación.
Redes neuronales recurrentes (RNN)
Las redes neuronales recurrentes (RNN) representan algunos de los algoritmos más avanzados que se han desarrollado, y son empleadas por tecnologías de uso generalizado como Siri y la búsqueda por voz de Google.
La RNN es el primer algoritmo capaz de retener su entrada gracias a la memoria interna, lo que la hace valiosa para los problemas de aprendizaje automático que implican datos secuenciales como el habla, el texto, los datos financieros, el audio, etc. La arquitectura única de las RNN les permite capturar eficazmente dependencias y patrones dentro de las secuencias, lo que permite predicciones más precisas y un mejor rendimiento general en una amplia gama de aplicaciones.
La característica distintiva de una RNN es su capacidad para mantener un estado oculto, que funciona como una memoria interna que le permite recordar información de pasos temporales anteriores. Esta capacidad de memoria permite a las RNN aprender y explotar dependencias de largo alcance dentro de la secuencia de entrada, lo que las hace especialmente eficaces para tareas como el análisis de series temporales, la PNL y el reconocimiento del habla.
La estructura de una RNN consiste en una serie de capas interconectadas, donde cada capa es responsable de procesar un paso temporal de la secuencia de entrada. La entrada de cada paso temporal es una combinación del punto de datos actual y el estado oculto del paso temporal anterior. Esta información es procesada por la capa RNN, que actualiza el estado oculto y genera una salida. El estado oculto actúa como una memoria que contiene información de pasos anteriores para influir en el procesamiento futuro.
Retos del aprendizaje profundo
A pesar de los notables éxitos del aprendizaje profundo, sigue habiendo varios retos y áreas de investigación futura que justifican una mayor exploración para avanzar en este campo y garantizar un despliegue responsable de estas tecnologías.
Interpretabilidad y explicabilidad
Una de las principales limitaciones de los modelos de aprendizaje profundo es su naturaleza de caja negra, que se refiere a la opacidad y complejidad de su funcionamiento interno. Esto dificulta que los profesionales, los usuarios y los reguladores comprendan e interpreten el razonamiento que subyace a sus predicciones y decisiones. Desarrollo de técnicas para una mejor interpretabilidad y explicabilidad es fundamental para abordar estas preocupaciones, y tiene varias implicaciones importantes.

Una mayor interpretabilidad y explicabilidad ayudará a los usuarios y partes interesadas a comprender mejor cómo los modelos de aprendizaje profundo llegan a sus predicciones o decisiones, fomentando así la confianza en sus capacidades y fiabilidad. Esto es especialmente importante en aplicaciones sensibles como sanidadLa inteligencia artificial puede tener consecuencias importantes en la vida de las personas.
La capacidad de interpretar y explicar los modelos de aprendizaje profundo también puede facilitar la identificación y mitigación de posibles sesgos, errores o consecuencias no deseadas. Al proporcionar información sobre el funcionamiento interno de los modelos, los profesionales pueden tomar decisiones informadas sobre la selección de modelos, la formación y el despliegue para garantizar que los sistemas de IA se utilicen de forma responsable y ética.
Conocer los procesos internos de los modelos de aprendizaje profundo puede ayudar a los profesionales a identificar problemas o errores que pueden estar afectando a su rendimiento. Al comprender los factores que influyen en las predicciones de un modelo, los profesionales pueden ajustar su arquitectura, los datos de entrenamiento o los hiperparámetros para mejorar el rendimiento y la precisión generales.
Datos y requisitos computacionales para el aprendizaje profundo
El aprendizaje profundo es increíblemente potente, pero esta potencia viene acompañada de importantes requisitos computacionales y de datos. En ocasiones, estos requisitos pueden plantear dificultades para la aplicación del aprendizaje profundo.

Uno de los principales retos del aprendizaje profundo es la necesidad de grandes cantidades de datos de entrenamiento etiquetados. Los modelos de aprendizaje profundo a menudo requieren grandes cantidades de datos para aprender y generalizar con eficacia. Esto se debe a que estos modelos están diseñados para extraer y aprender automáticamente características a partir de datos brutos, y cuantos más datos tengan acceso, mejor podrán identificar y capturar patrones y relaciones intrincados.
Sin embargo, adquirir y etiquetar cantidades tan grandes de datos puede llevar mucho tiempo, ser laborioso y costoso. En algunos casos, los datos etiquetados pueden ser escasos o difíciles de obtener, sobre todo en ámbitos especializados como la imagen médica o las lenguas raras. Para hacer frente a este reto, los investigadores han explorado varias técnicas, como el aumento de datos, el aprendizaje por transferencia y el aprendizaje no supervisado o semisupervisado, cuyo objetivo es mejorar el rendimiento de los modelos con datos etiquetados limitados.
Los modelos de aprendizaje profundo también exigen importantes recursos computacionales para el entrenamiento y la inferencia. Estos modelos suelen implicar un gran número de parámetros y capas, lo que requiere un hardware potente y unidades de procesamiento especializadas, como GPU o TPU, para realizar los cálculos necesarios de forma eficiente.
Las exigencias computacionales de los modelos de aprendizaje profundo pueden resultar prohibitivas para algunas aplicaciones u organizaciones con recursos limitados, lo que conlleva tiempos de entrenamiento más largos y costes más elevados. Para mitigar estos problemas, los investigadores y los profesionales han estado investigando métodos para optimizar los modelos de aprendizaje profundo y reducir el tamaño y la complejidad del modelo manteniendo su rendimiento, lo que en última instancia conduce a tiempos de entrenamiento más rápidos y menores requisitos de recursos.
Robustez y seguridad
Los modelos de aprendizaje profundo han demostrado un rendimiento excepcional en diversas aplicaciones; sin embargo, siguen siendo susceptibles de ataques de adversarios. Estos ataques consisten en crear muestras de entrada maliciosas diseñadas deliberadamente para engañar al modelo y hacer que genere predicciones o resultados incorrectos. Afrontar estas vulnerabilidades y mejorar la robustez y seguridad de los modelos de aprendizaje profundo frente a ejemplos adversos y otros riesgos potenciales es un reto crítico para la comunidad de la IA. Las consecuencias de estos ataques pueden ser de gran alcance, especialmente en ámbitos de alto riesgo como los vehículos autónomos, la ciberseguridad y la atención sanitaria, donde la integridad y la fiabilidad de los sistemas de IA son primordiales.
Los ataques de adversarios explotan la sensibilidad de los modelos de aprendizaje profundo a pequeñas perturbaciones, a menudo imperceptibles, en los datos de entrada. Incluso pequeñas alteraciones en los datos originales pueden dar lugar a predicciones o clasificaciones drásticamente diferentes, a pesar de que las entradas parezcan prácticamente idénticas a los observadores humanos. Este fenómeno plantea dudas sobre la estabilidad y fiabilidad de los modelos de aprendizaje profundo en situaciones reales en las que los adversarios podrían manipular los datos de entrada para comprometer el rendimiento del sistema.
Aplicaciones del aprendizaje profundo
El aprendizaje profundo ha demostrado su potencial transformador en una amplia gama de aplicaciones e industrias. Algunas de las aplicaciones más destacadas son:
- Reconocimiento de imágenes y visión por ordenador: El aprendizaje profundo ha mejorado drásticamente la precisión y eficiencia de las tareas de reconocimiento de imágenes y visión por ordenador. Las CNN, en particular, han destacado en la clasificación de imágenes, la detección de objetos y la segmentación. Estos avances han allanado el camino para aplicaciones como el reconocimiento facial, los vehículos autónomos y el análisis de imágenes médicas.
- NLP: El aprendizaje profundo ha revolucionado el procesamiento del lenguaje natural, permitiendo el desarrollo de modelos y aplicaciones lingüísticas más sofisticados. Se han empleado varios modelos para lograr resultados de vanguardia en tareas como la traducción automática, el análisis de sentimientos, el resumen de textos y los sistemas de respuesta a preguntas.
- Reconocimiento y generación del habla: El aprendizaje profundo también ha hecho avances significativos en el reconocimiento y la generación del habla. Se han utilizado técnicas como las RNN y las CNN para desarrollar sistemas de reconocimiento automático del habla (ASR) más precisos y eficientes, que convierten el lenguaje hablado en texto escrito. Los modelos de aprendizaje profundo también han permitido la síntesis del habla de alta calidad, generando habla similar a la humana a partir de texto.
- Aprendizaje por refuerzo: El aprendizaje profundo, cuando se combina con el aprendizaje por refuerzo, ha llevado al desarrollo de aprendizaje por refuerzo profundo (DRL) algoritmos. El DRL se ha empleado para entrenar agentes capaces de aprender políticas óptimas para la toma de decisiones y el control. Las aplicaciones de DRL abarcan la robótica, las finanzas y los juegos.
- Modelos generativos: Los modelos generativos de aprendizaje profundo, como Redes generativas adversariales (GAN)han demostrado un notable potencial para generar muestras de datos realistas. Estos modelos se han utilizado para tareas como la síntesis de imágenes, la transferencia de estilos, el aumento de datos y la detección de anomalías.
- Sanidad: El aprendizaje profundo también ha hecho importantes contribuciones a la atención sanitaria, revolucionando el diagnóstico, el descubrimiento de fármacos y la medicina personalizada. Por ejemplo, los algoritmos de aprendizaje profundo se han utilizado para analizar imágenes médicas para la detección precoz de enfermedades, predecir los resultados de los pacientes e identificar posibles candidatos a fármacos.
Revolucionando industrias y aplicaciones
El aprendizaje profundo se ha convertido en una tecnología innovadora con potencial para revolucionar una amplia gama de sectores y aplicaciones. En esencia, el aprendizaje profundo aprovecha las redes neuronales artificiales para imitar la capacidad del cerebro humano para aprender y procesar información. Las CNN y las RNN son dos arquitecturas destacadas que han permitido avances significativos en campos como el reconocimiento de imágenes, la PNL, el reconocimiento del habla y la atención sanitaria.
El aprendizaje profundo sigue afrontando retos que deben abordarse para garantizar su despliegue responsable y ético. Estos retos incluyen mejorar la interpretabilidad y explicabilidad de los modelos de aprendizaje profundo, abordar los requisitos computacionales y de datos, y mejorar la robustez y seguridad de estos modelos frente a ataques de adversarios.
A medida que investigadores y profesionales sigan explorando y desarrollando técnicas innovadoras para afrontar estos retos, el campo del aprendizaje profundo seguirá avanzando sin duda, aportando nuevas capacidades y aplicaciones que transformarán nuestra forma de vivir, trabajar e interactuar con el mundo que nos rodea. Con su inmenso potencial, el aprendizaje profundo está llamado a desempeñar un papel cada vez más importante en la configuración del futuro de la inteligencia artificial y en el impulso del progreso tecnológico en diversos ámbitos.


