
Comprender las estructuras de precios LLM: Entradas, salidas y ventanas contextuales



Para las estrategias empresariales de IA, comprender las estructuras de precios de los grandes modelos lingüísticos (LLM) es crucial para una gestión eficaz de los costes. Los costes operativos asociados a los LLM pueden aumentar rápidamente sin una supervisión adecuada, lo que puede dar lugar a picos de costes inesperados que pueden desbaratar los presupuestos y obstaculizar la adopción generalizada. T
sta entrada del blog profundiza en los componentes clave de las estructuras de precios de los LLM, proporcionando información que le ayudará a optimizar su uso de los LLM y a controlar los gastos.
Los precios de los LLM suelen girar en torno a tres componentes principales: fichas de entrada, fichas de salida y ventanas contextuales. Cada uno de estos elementos desempeña un papel importante a la hora de determinar el coste global de utilizar LLM en sus aplicaciones. Si conoce a fondo estos componentes, estará mejor preparado para tomar decisiones informadas sobre la selección de modelos, los patrones de uso y las estrategias de optimización.
Componentes básicos de la fijación de precios LLM
Fichas de entrada
Los tokens de entrada representan el texto introducido en el LLM para su procesamiento. Esto incluye sus indicaciones, instrucciones y cualquier contexto adicional proporcionado al modelo. El número de tokens de entrada influye directamente en el coste de cada llamada a la API, ya que un mayor número de tokens requiere más recursos informáticos para su procesamiento.
Fichas de salida
Los tokens de salida son el texto generado por el LLM en respuesta a su entrada. El precio de los tokens de salida suele diferir del de los tokens de entrada, lo que refleja el esfuerzo computacional adicional necesario para la generación de texto. Gestionar el uso de tokens de salida es crucial para controlar los costes, especialmente en aplicaciones que generan grandes volúmenes de texto.
Ventanas contextuales
Las ventanas de contexto se refieren a la cantidad de texto previo que el modelo puede tener en cuenta a la hora de generar respuestas. Las ventanas de contexto más amplias permiten una comprensión más completa, pero tienen un coste más elevado debido al mayor uso de tokens y a los requisitos computacionales.
Fichas de Entrada: Qué son y cómo se cobran
Los tokens de entrada son las unidades fundamentales del texto procesado por un LLM. Suelen corresponder a partes de palabras, con palabras comunes representadas por un único token y palabras menos comunes divididas en múltiples tokens. Por ejemplo, la frase "The quick brown fox" podría tokenizarse como ["The", "quick", "bro", "wn", "fox"], lo que daría como resultado 5 tokens de entrada.
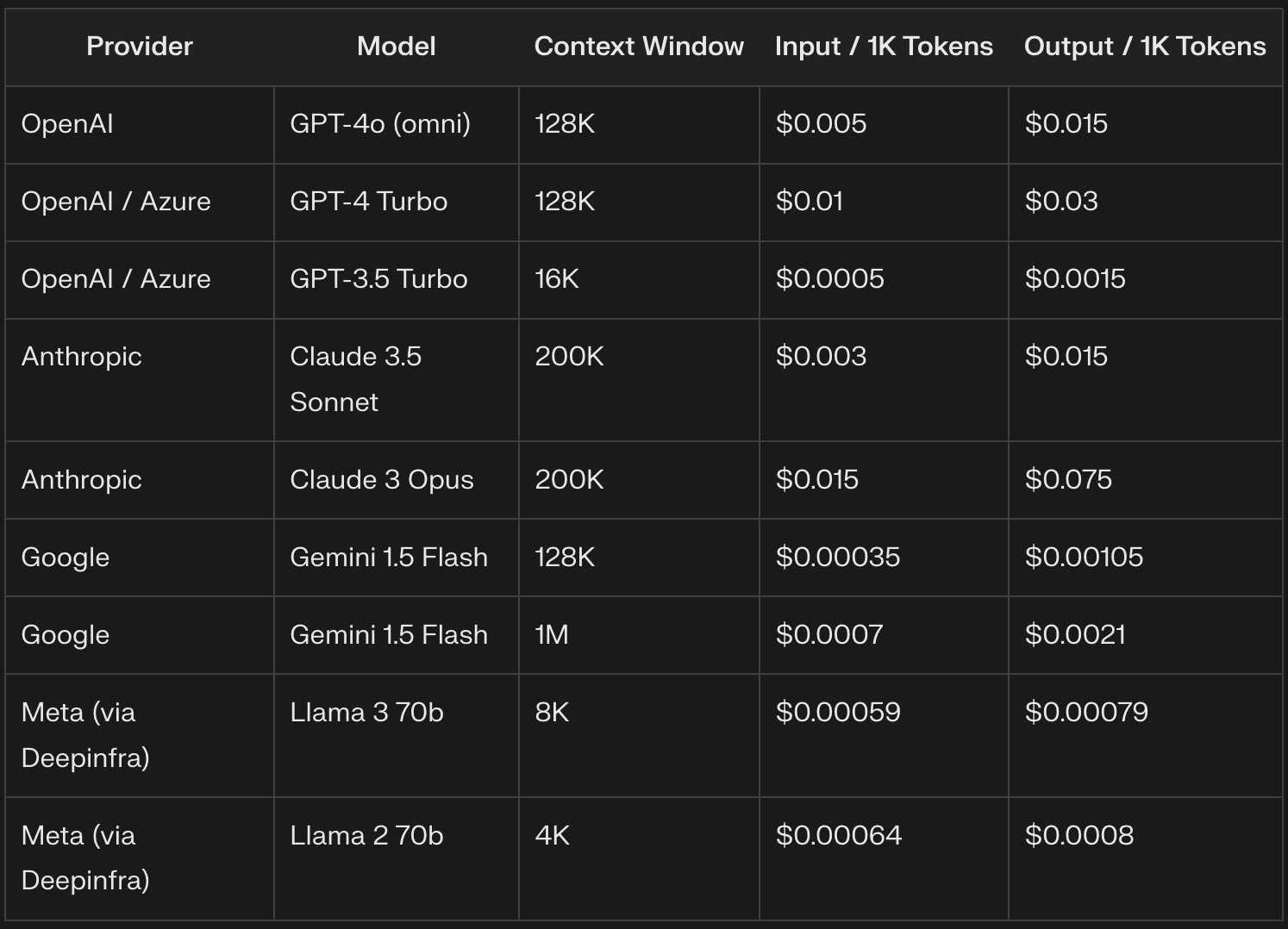
Los proveedores de LLM suelen cobrar por los tokens de entrada una tarifa por cada mil tokens. Por ejemplo, GPT-4o cobra $5 por cada millón de tokens de entrada, lo que equivale a $0,005 por cada 1.000 tokens de entrada. El precio exacto puede variar significativamente entre proveedores y versiones de modelos, y los modelos más avanzados suelen cobrar tarifas más altas.
Para gestionar eficazmente los costes de LLM, tenga en cuenta estas estrategias para optimizar el uso de tokens de entrada:
Crear avisos concisos: Elimine las palabras innecesarias y céntrese en instrucciones claras y directas.
Utilice una codificación eficiente: Elija un método de codificación que represente su texto con menos tokens.
Implantar plantillas de avisos: Desarrollar y reutilizar estructuras optimizadas para tareas comunes.
Si gestiona cuidadosamente sus tokens de entrada, podrá reducir significativamente los costes asociados al uso de LLM, manteniendo al mismo tiempo la calidad y eficacia de sus aplicaciones de IA.
Fichas de salida: Entender los costes
Los tokens de salida representan el texto generado por el LLM en respuesta a su entrada. Al igual que los tokens de entrada, los tokens de salida se calculan a partir del proceso de tokenización del modelo. Sin embargo, el número de tokens de salida puede variar significativamente en función de la tarea y de la configuración del modelo. Por ejemplo, una pregunta sencilla puede generar una respuesta breve con pocos tokens, mientras que una petición de una explicación detallada puede dar lugar a cientos de tokens.
Los proveedores de LLM suelen fijar precios diferentes para los tokens de salida y los de entrada, normalmente más elevados debido a la complejidad computacional de la generación de texto. Por ejemplo, OpenAI cobra $15 por 1 millón de tokens ($0,015 por 1.000 tokens) por GPT-4o.
Para optimizar el uso de fichas de salida y controlar los costes:
Establezca límites claros de longitud de salida en sus avisos o llamadas a la API.
Utilice técnicas como el "aprendizaje de pocos disparos" para guiar al modelo hacia respuestas más concisas.
Implementar el postprocesamiento para recortar el contenido innecesario de los resultados de LLM.
Considere la posibilidad de almacenar en caché la información solicitada con frecuencia para reducir las llamadas redundantes a LLM.
Ventanas contextuales: El factor de coste oculto
Las ventanas de contexto determinan la cantidad de texto anterior que el LLM puede tener en cuenta al generar una respuesta. Esta característica es crucial para mantener la coherencia en las conversaciones y permitir que el modelo haga referencia a información anterior. El tamaño de la ventana de contexto puede influir significativamente en el rendimiento del modelo, sobre todo en tareas que requieren memoria a largo plazo o razonamiento complejo.
Las ventanas de contexto más grandes aumentan directamente el número de tokens de entrada procesados por el modelo, lo que conlleva mayores costes. Por ejemplo:
Un modelo con una ventana de contexto de 4.000 tokens que procesa una conversación de 3.000 tokens cobrará por los 3.000 tokens.
La misma conversación con una ventana contextual de 8.000 tokens podría cobrarse por 7.000 tokens, incluyendo partes anteriores de la conversación.
Este escalado puede suponer un aumento sustancial de los costes, especialmente en el caso de las aplicaciones que manejan diálogos largos o análisis de documentos.
Para optimizar el uso de la ventana contextual:
Implementar un dimensionamiento dinámico del contexto basado en los requisitos de la tarea.
Utilice técnicas de resumen para condensar la información relevante de conversaciones más largas.
Emplear enfoques de ventanas deslizantes para procesar documentos largos, centrándose en las secciones más relevantes.
Considere la posibilidad de utilizar modelos más pequeños y especializados para tareas que no requieran un contexto amplio.
Mediante una gestión cuidadosa de las ventanas de contexto, se puede lograr un equilibrio entre el mantenimiento de resultados de alta calidad y el control de los costes del LLM. Recuerde que el objetivo es proporcionar un contexto suficiente para la tarea en cuestión sin inflar innecesariamente el uso de tokens y los gastos asociados.
Tendencias futuras en la fijación de precios de los LLM
A medida que evolucione el panorama de los LLM, es posible que veamos cambios en las estructuras de precios:
Tarificación por tareas: Los modelos cobran en función de la complejidad de la tarea y no del número de fichas.
Modelos de suscripción: Acceso con tarifa plana a los LLM con límites de uso o precios escalonados.
Precios basados en el rendimiento: Costes vinculados a la calidad o precisión de los resultados, en lugar de sólo a la cantidad.
Impacto de los avances tecnológicos en los costes
La investigación y el desarrollo continuos en IA pueden conducir a:
Modelos más eficientes: Reducción de los requisitos informáticos, lo que se traduce en menores costes operativos.
Técnicas de compresión mejoradas: Métodos mejorados para reducir el número de tokens de entrada y salida.
Integración de Edge Computing: Procesamiento local de tareas LLM, reduciendo potencialmente los costes de computación en nube.
Lo esencial
Comprender las estructuras de precios LLM es esencial para una gestión eficaz de los costes en las aplicaciones empresariales de IA. Al comprender los matices de los tokens de entrada, los tokens de salida y las ventanas de contexto, las organizaciones pueden tomar decisiones informadas sobre la selección de modelos y los patrones de uso. La aplicación de técnicas estratégicas de gestión de costes, como la optimización del uso de tokens y el aprovechamiento del almacenamiento en caché, puede suponer un ahorro significativo.
A medida que la tecnología LLM siga evolucionando, mantenerse informado sobre las tendencias de precios y las estrategias de optimización emergentes será crucial para mantener unas operaciones de IA rentables. Recuerde que el éxito de la gestión de costes LLM es un proceso continuo que requiere un seguimiento, análisis y adaptación continuos para garantizar el máximo valor de sus inversiones en IA.
Si quieres saber cómo tu empresa puede aprovechar mejor las estructuras de precios de LLM, no dudes en ponerte en contacto con nosotros.


