
Resumen del trabajo de investigación sobre IA: "¿Cadena de pensamiento(menos)?" Sugerencia



Las instrucciones de cadena de pensamiento (CoT) han sido consideradas un gran avance en el desarrollo de las capacidades de razonamiento de los grandes modelos lingüísticos (LLM). Esta técnica, que consiste en proporcionar ejemplos de razonamiento paso a paso para guiar a los LLM, ha suscitado una gran atención en la comunidad de la IA. Numerosos investigadores y profesionales afirman que las instrucciones CoT permiten a los LLM abordar tareas de razonamiento complejas con mayor eficacia, lo que podría salvar la brecha entre la computación artificial y la resolución de problemas de tipo humano.
Sin embargo, un artículo reciente titulado "¿Cadena de irreflexión? Un análisis de la CoT en la planificación"cuestiona estas afirmaciones optimistas. Este trabajo de investigación, centrado en las tareas de planificación, ofrece un examen crítico de la eficacia y la generalizabilidad de las instrucciones CoT. Como profesionales de la IA, es crucial comprender estas conclusiones y sus implicaciones para el desarrollo de aplicaciones de IA que requieran capacidades de razonamiento sofisticadas.
Comprender el estudio
Los investigadores eligieron un dominio de planificación clásico llamado Blocksworld como principal campo de pruebas. En Blocksworld, la tarea consiste en reorganizar un conjunto de bloques desde una configuración inicial hasta una configuración objetivo mediante una serie de acciones de movimiento. Este dominio es ideal para probar las capacidades de razonamiento y planificación porque:
Permite generar problemas de complejidad variable
Tiene soluciones claras y verificables algorítmicamente.
Es poco probable que esté muy representado en los datos de formación del LLM
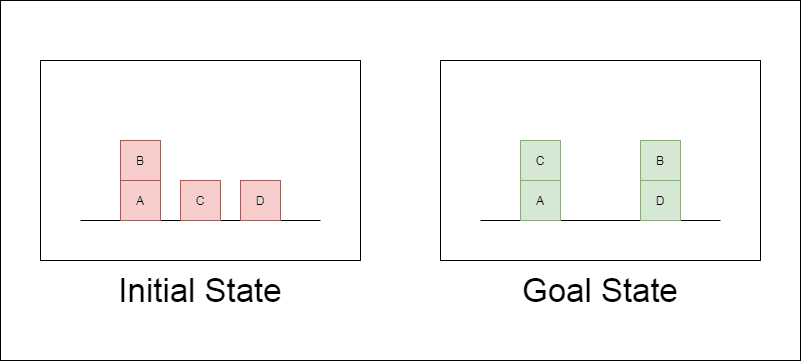
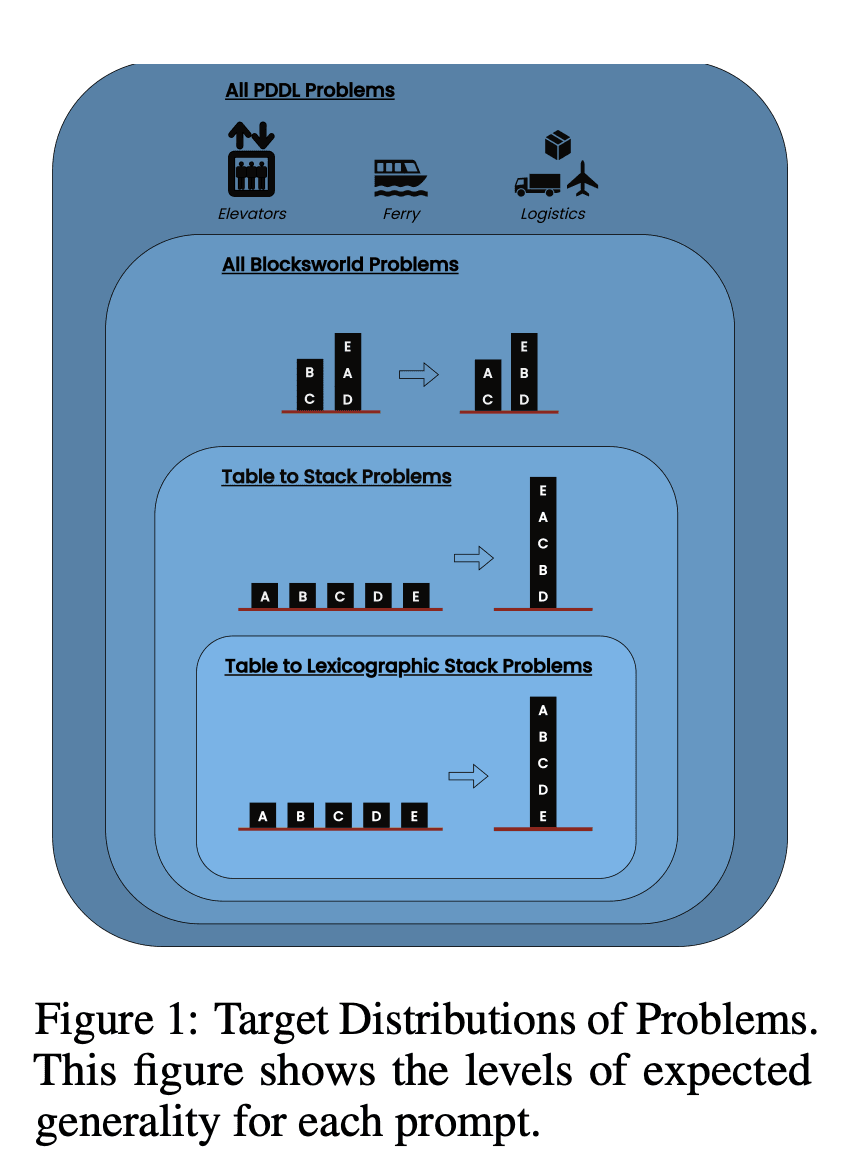
El estudio examinó tres LLM de última generación: GPT-4, Claude-3-Opus y GPT-4-Turbo. Estos modelos se probaron con instrucciones de distinta especificidad:
Cadena de pensamiento Zero-Shot (Universal): Simplemente añadiendo "pensemos paso a paso" a la indicación.
Prueba de progresión (específica para PDDL): Explicación general de la corrección del plan con ejemplos.
Algoritmo universal Blocksworld: Demostración de un algoritmo general para resolver cualquier problema de Blocksworld.
Stacking Prompt: Centrarse en una subclase específica de problemas de Blocksworld (tabla a pila).
Apilamiento lexicográfico: Limitarse aún más a una forma sintáctica concreta del estado objetivo.
Al probar estas indicaciones en problemas de complejidad creciente, los investigadores pretendían evaluar hasta qué punto los LLM podían generalizar el razonamiento demostrado en los ejemplos.
Principales conclusiones
Los resultados de este estudio ponen en tela de juicio muchas de las hipótesis predominantes sobre la incitación al TdC:
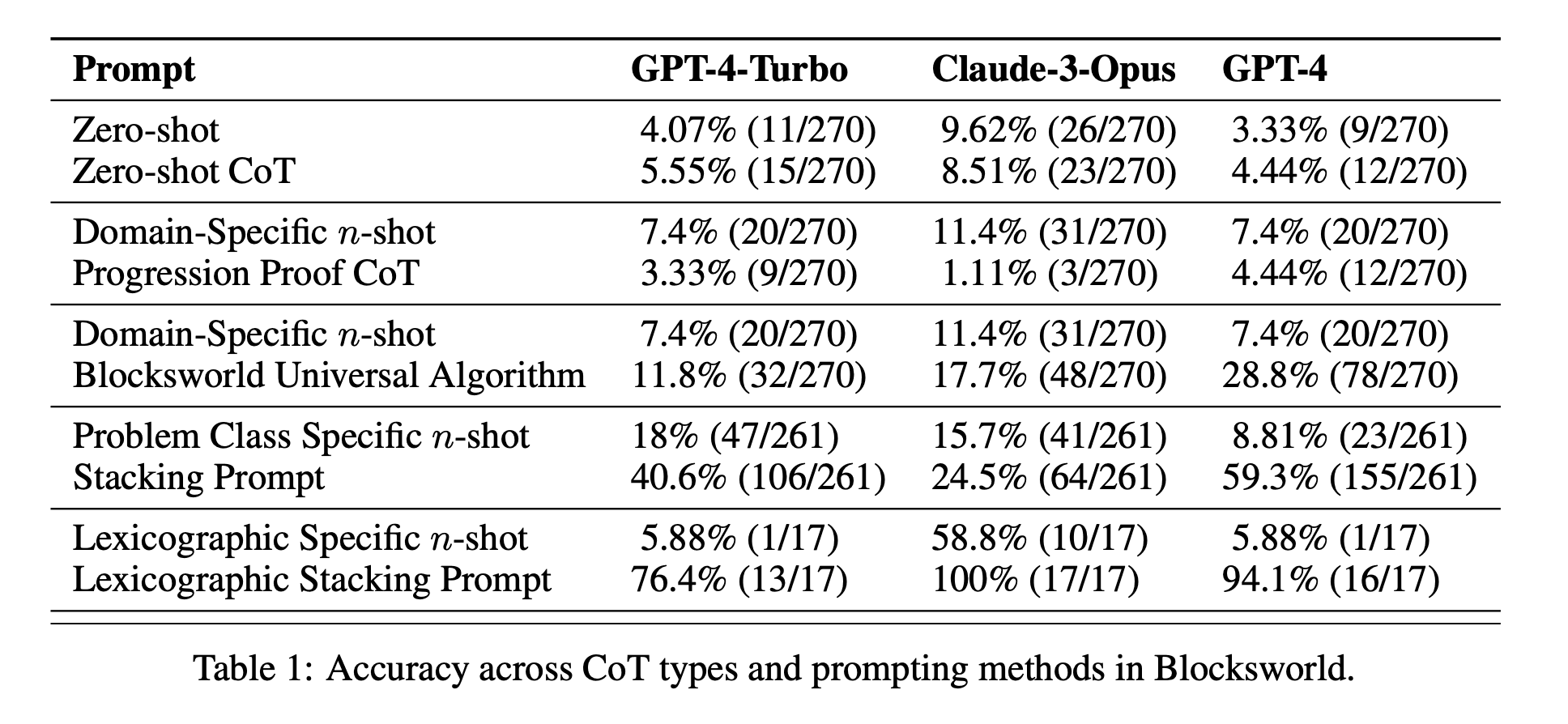
Eficacia limitada del CdT: Contrariamente a lo que se había afirmado hasta ahora, el rendimiento de CoT sólo mejoraba significativamente cuando los ejemplos eran muy similares al problema consultado. En cuanto los problemas se desviaban del formato exacto de los ejemplos, el rendimiento disminuía drásticamente.
Rápida degradación del rendimiento: A medida que aumentaba la complejidad de los problemas (medida por el número de bloques implicados), la precisión de todos los modelos disminuía drásticamente, independientemente de la indicación de CoT utilizada. Esto sugiere que los LLM tienen dificultades para extender el razonamiento demostrado en ejemplos sencillos a escenarios más complejos.
Ineficacia de los avisos generales: Sorprendentemente, las indicaciones más generales de CoT a menudo dieron peores resultados que las indicaciones estándar sin ningún ejemplo de razonamiento. Esto contradice la idea de que el CdT ayuda a los LLM a aprender estrategias generalizables de resolución de problemas.
Compromiso de especificidad: El estudio reveló que las instrucciones muy específicas podían lograr una gran precisión, pero sólo en un subconjunto muy reducido de problemas. Esto pone de manifiesto la existencia de un claro equilibrio entre el aumento del rendimiento y la aplicabilidad de la indicación.
Falta de verdadero aprendizaje algorítmico: Los resultados sugieren claramente que los LLM no aprenden a aplicar procedimientos algorítmicos generales a partir de los ejemplos del CdT. En su lugar, parecen basarse en la concordancia de patrones, que se rompe rápidamente cuando se enfrentan a problemas nuevos o más complejos.
Estos resultados tienen importantes implicaciones para los profesionales de la IA y las empresas que deseen aprovechar la inducción CoT en sus aplicaciones. Sugieren que, aunque el CoT puede mejorar el rendimiento en determinados escenarios, puede que no sea la panacea para tareas de razonamiento complejas que muchos esperaban.
Más allá de Blocksworld: Ampliación de la investigación
Para asegurarse de que sus hallazgos no se limitaban al dominio de Blocksworld, los investigadores ampliaron su investigación a varios dominios de problemas sintéticos utilizados habitualmente en estudios anteriores sobre CoT:
CoinFlip: Tarea que consiste en predecir el estado de una moneda tras una serie de lanzamientos.
ÚltimaLetraConcatenación: Tarea de tratamiento de texto que requiere la concatenación de las últimas letras de palabras dadas.
Aritmética en varios pasos: Problemas de simplificación de expresiones aritméticas complejas.
Se eligieron estos dominios porque permiten generar problemas con una complejidad creciente, similar a Blocksworld. Los resultados de estos experimentos adicionales fueron sorprendentemente coherentes con los de Blocksworld:
Falta de generalización: El sistema CoT sólo mejoró en problemas muy similares a los ejemplos presentados. A medida que aumentaba la complejidad de los problemas, el rendimiento disminuía rápidamente hasta niveles comparables o peores que los de las instrucciones estándar.
Concordancia sintáctica de patrones: En la tarea LastLetterConcatenation, la ayuda de CoT mejoró ciertos aspectos sintácticos de las respuestas (como el uso de las letras correctas), pero no consiguió mantener la precisión a medida que aumentaba el número de palabras.
Fracaso a pesar de pasos intermedios perfectos: En las tareas aritméticas, incluso cuando los modelos podían resolver perfectamente todas las operaciones posibles con un solo dígito, seguían sin generalizar a secuencias más largas de operaciones.
Estos resultados refuerzan aún más la conclusión de que los LLM actuales no aprenden realmente estrategias de razonamiento generalizables a partir de ejemplos de CdT. En su lugar, parecen depender en gran medida de la coincidencia de patrones superficiales, que se rompe cuando se enfrentan a problemas que se desvían de los ejemplos demostrados.
Implicaciones para el desarrollo de la IA
Las conclusiones de este estudio tienen importantes implicaciones para el desarrollo de la IA, sobre todo para las empresas que trabajan en aplicaciones que requieren capacidades complejas de razonamiento o planificación:
Reevaluación de la eficacia del CdT: El estudio pone en tela de juicio la idea de que la inducción de CoT "desbloquea" las capacidades de razonamiento general en los LLM. Los desarrolladores de IA deben ser cautelosos a la hora de confiar en CoT para tareas que requieran un verdadero pensamiento algorítmico o generalización a nuevos escenarios.
Limitaciones de los LLM actuales: A pesar de sus impresionantes capacidades en muchas áreas, los LLM más avanzados siguen teniendo dificultades para realizar razonamientos coherentes y generalizables. Esto sugiere que pueden ser necesarios enfoques alternativos para aplicaciones que requieran una planificación robusta o la resolución de problemas en varios pasos.
El coste de la ingeniería rápida: Aunque las instrucciones muy específicas del TdC pueden dar buenos resultados en conjuntos de problemas limitados, el esfuerzo humano necesario para elaborarlas puede compensar los beneficios, sobre todo si se tiene en cuenta su limitada generalizabilidad.
Repensar las métricas de evaluación: El estudio subraya la importancia de probar los modelos de IA en problemas de complejidad y estructura variables. Basarse únicamente en conjuntos de pruebas estáticas puede sobrestimar la verdadera capacidad de razonamiento de un modelo.
La brecha entre percepción y realidad: Existe una discrepancia significativa entre las capacidades de razonamiento percibidas de los LLM (a menudo antropomorfizadas en el discurso popular) y sus capacidades reales, como demuestra este estudio.
Recomendaciones para los profesionales de la IA
A la vista de estos datos, he aquí algunas recomendaciones clave para los profesionales de la IA y las empresas que trabajan con LLM:
Prácticas de evaluación rigurosas:
Implantar marcos de pruebas que puedan generar problemas de diversa complejidad.
No confíe únicamente en conjuntos de pruebas estáticos o puntos de referencia que puedan estar representados en los datos de formación.
Evaluar el rendimiento en un espectro de variaciones de problemas para valorar la verdadera generalización.
Expectativas realistas para el CdT:
Utilizar las indicaciones del TdC con criterio, comprendiendo sus limitaciones en la generalización.
Tenga en cuenta que las mejoras de rendimiento de CoT pueden limitarse a conjuntos de problemas reducidos.
Considere la compensación entre el rápido esfuerzo de ingeniería y las posibles mejoras de rendimiento.
Enfoques híbridos:
Para tareas de razonamiento complejas, considere la posibilidad de combinar los LLM con enfoques algorítmicos tradicionales o módulos de razonamiento especializados.
Explorar métodos que puedan aprovechar los puntos fuertes de los LLM (por ejemplo, la comprensión del lenguaje natural) y compensar al mismo tiempo sus puntos débiles en el razonamiento algorítmico.
Transparencia en las aplicaciones de IA:
Comunicar claramente las limitaciones de los sistemas de IA, especialmente cuando implican tareas de razonamiento o planificación.
Evitar exagerar las capacidades de los LLM, sobre todo en aplicaciones críticas para la seguridad o de alto riesgo.
Investigación y desarrollo continuados:
Invertir en investigación destinada a mejorar las verdaderas capacidades de razonamiento de los sistemas de IA.
Explorar arquitecturas o métodos de entrenamiento alternativos que puedan conducir a una generalización más robusta en tareas complejas.
Perfeccionamiento específico del dominio:
En el caso de ámbitos problemáticos limitados y bien definidos, se puede considerar la posibilidad de perfeccionar los modelos a partir de datos y patrones de razonamiento específicos del ámbito.
Tenga en cuenta que este tipo de ajuste puede mejorar el rendimiento dentro del dominio, pero no generalizarse más allá del mismo.
Siguiendo estas recomendaciones, los profesionales de la IA pueden desarrollar aplicaciones de IA más sólidas y fiables, evitando posibles escollos asociados a la sobreestimación de las capacidades de razonamiento de los actuales LLM. Los resultados de este estudio son un valioso recordatorio de la importancia de la evaluación crítica y realista en el campo de la IA, que evoluciona rápidamente.
Lo esencial
Este estudio pionero sobre la inducción de la cadena de pensamiento en tareas de planificación pone en tela de juicio nuestra comprensión de las capacidades de los LLM y suscita una reevaluación de las actuales prácticas de desarrollo de la IA. Al revelar las limitaciones de CoT en la generalización a problemas complejos, subraya la necesidad de pruebas más rigurosas y expectativas realistas en las aplicaciones de IA.
Para los profesionales de la IA y las empresas, estos resultados ponen de relieve la importancia de combinar los puntos fuertes del LLM con enfoques de razonamiento especializados, invertir en soluciones específicas para cada ámbito cuando sea necesario y mantener la transparencia sobre las limitaciones de los sistemas de IA. A medida que avanzamos, la comunidad de la IA debe centrarse en el desarrollo de nuevas arquitecturas y métodos de entrenamiento que puedan salvar la distancia entre la concordancia de patrones y el verdadero razonamiento algorítmico. Este estudio es un recordatorio crucial de que, aunque los LLM han hecho progresos notables, conseguir capacidades de razonamiento similares a las humanas sigue siendo un reto constante en la investigación y el desarrollo de la IA.


